John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
1If I could speak all the languages of earth and of angels, but didn’t love others, I would only be a noisy gong or a clanging cymbal. 2If I had the gift of prophecy, and if I understood all of God’s secret plans and possessed all knowledge, and if I had such faith that I could move mountains, but didn’t love others, I would be nothing. 3If I gave everything I have to the poor and even sacrificed my body, I could boast about it; but if I didn’t love others, I would have gained nothing.
4Love is patient and kind. Love is not jealous or boastful or proud
5or rude. It does not demand its own way. It is not irritable, and it keeps no record of being wronged.
6It does not rejoice about injustice but rejoices whenever the truth wins out.
7Love never gives up, never loses faith, is always hopeful, and endures through every circumstance.
8Prophecy and speaking in unknown languages and special knowledge will become useless. But love will last forever! 9Now our knowledge is partial and incomplete, and even the gift of prophecy reveals only part of the whole picture! 10But when the time of perfection comes, these partial things will become useless.
11When I was a child, I spoke and thought and reasoned as a child. But when I grew up, I put away childish things. 12Now we see things imperfectly, like puzzling reflections in a mirror, but then we will see everything with perfect clarity. All that I know now is partial and incomplete, but then I will know everything completely, just as God now knows me completely.
13Three things will last forever—faith, hope, and love—and the greatest of these is love.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John Wanamaker, (attributed) US department store merchant (1838 – 1922)
Between $190 billion and $270 billion is spent on advertising in the United States each year (depending on source). It is often hard to tell whether the advertising boosts sales and profits. This is caused by the unpredictability of individual sales and in many cases the other changes in the business and business environment occurring in addition to the advertising. In technical terms, the evaluation of the effect of advertising on sales and profits is often a multidimensional problem.
Many common metrics such as the number of views, click through rates (CTR), and others do not directly measure the change in sales or profits. For example, an embarrassing or controversial video can generate large numbers of views, shares, and even likes on a social media site and yet cause a sizable fall in sales and profits.
Because individual sales are unpredictable, it is often difficult or impossible to tell whether a change in sales is caused by advertising, simply due to chance alone or some combination of advertising and luck.
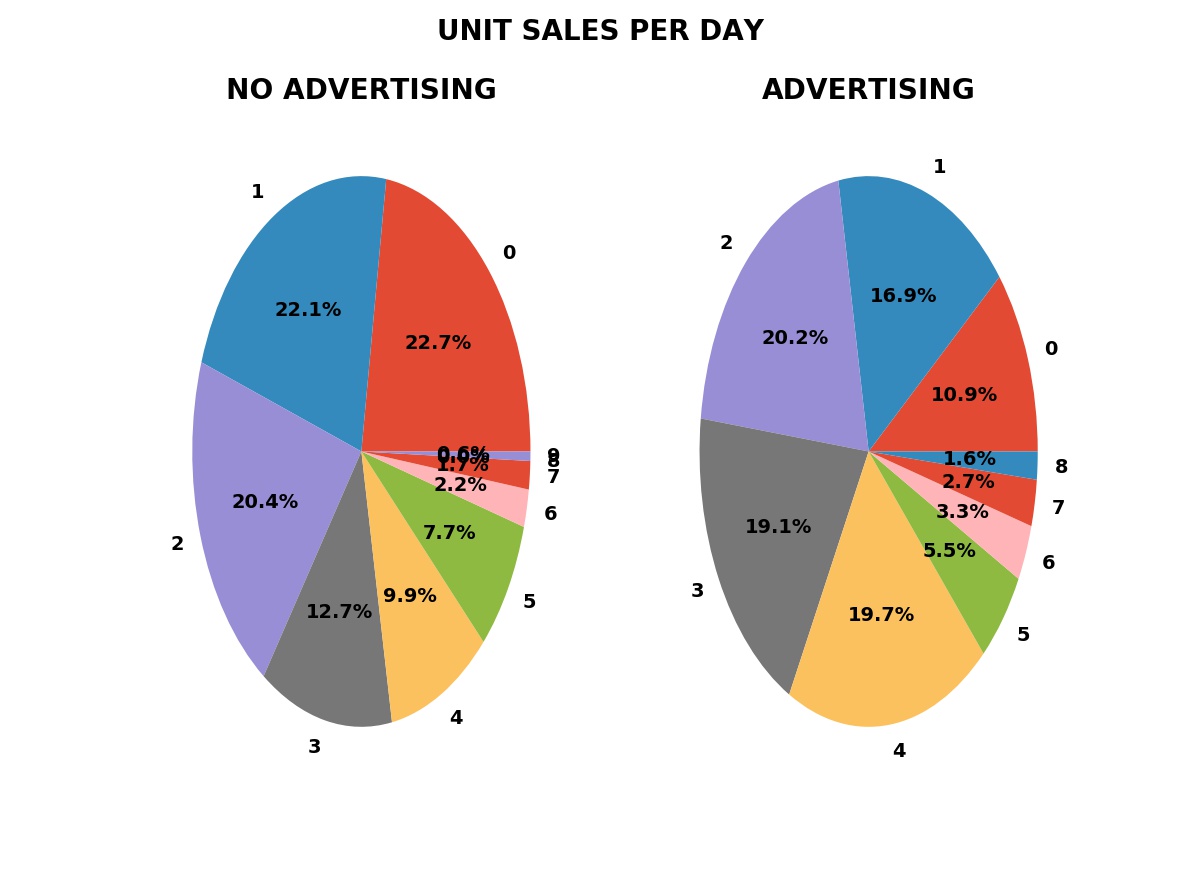
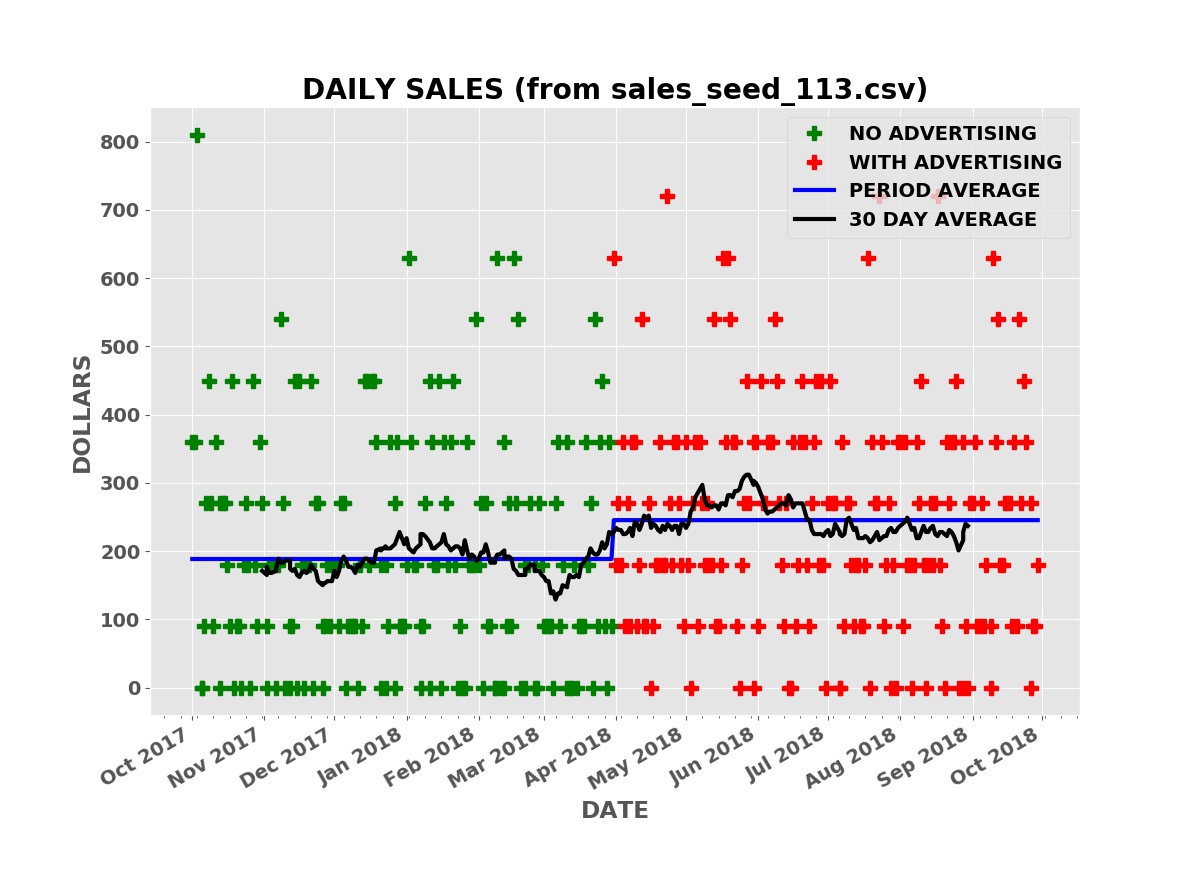
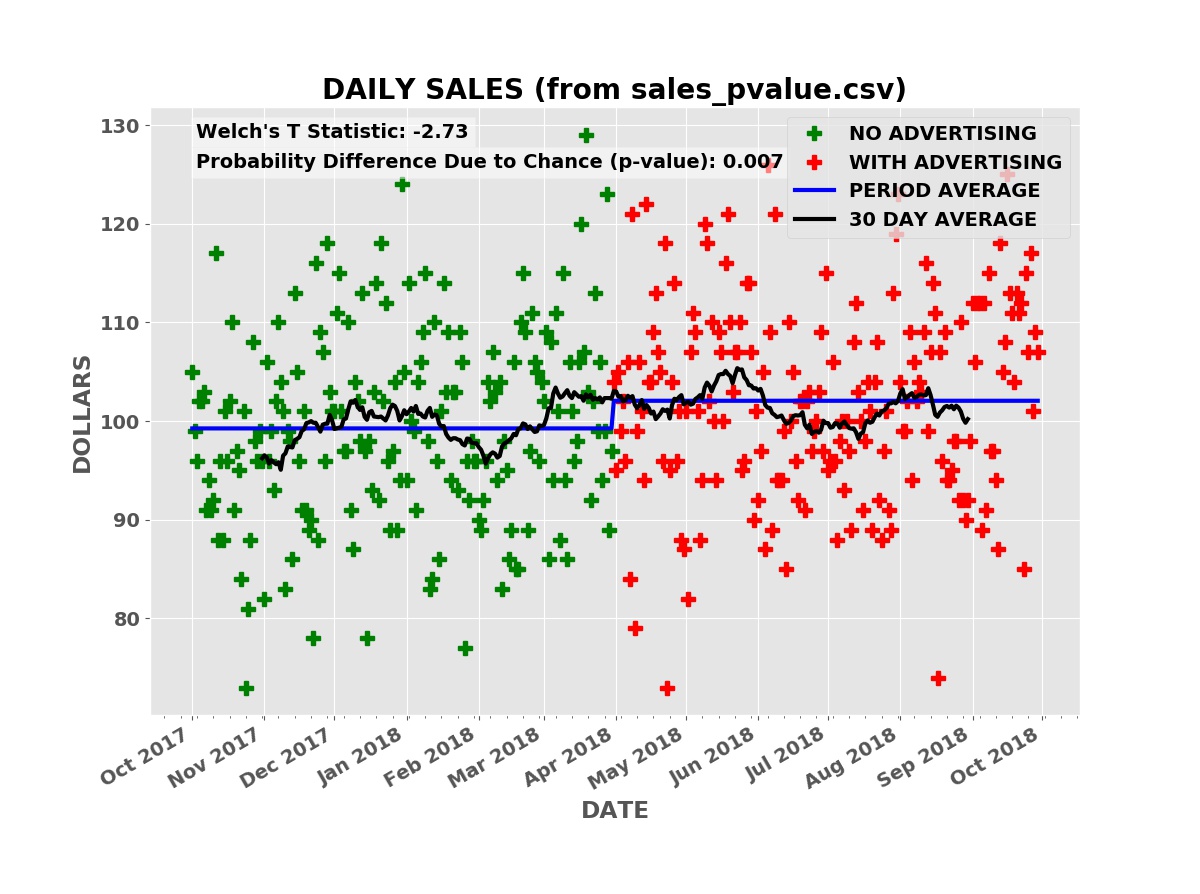
The plot below shows the simulated daily sales for a product or service with a price of $90.00 per unit. Initially, the business has no advertising, relying on word of mouth and other methods to acquire and retain customers. During this “no advertising” period, an average of three units are sold per day. The business then contracts with an advertising service such as Facebook, Google AdWords, Yelp, etc. During this “advertising” period, an average of three and one half units are sold per day.
Daily Sales
The raw daily sales data is impossible to interpret. Even looking at the thirty day moving average of daily sales (the black line), it is far from clear that the advertising campaign is boosting sales.
Taking the average daily sales over the “no advertising” period, the first six months, and over the “advertising” period (the blue line), the average daily sales was higher during the advertising period.
Is the increase in sales due to the advertising or random chance or some combination of the two causes? There is always a possibility that the sales increase is simply due to chance. How much confidence can we have that the increase in sales is due to the advertising and not chance?
This is where statistical methods such as Student’s T test, Welch’s T test, mathematical modeling and computer simulations are needed. These methods compute the effectiveness of the advertising in quantitative terms. These quantitative measures can be converted to estimates of future sales and profits, risks and potential rewards, in dollar terms.
Measuring the Difference Between Two Random Data Sets
In most cases, individual sales are random events like the outcome of flipping a coin. Telling whether sales data with and without advertising is the same is similar to evaluating whether two coins have the same chances of heads and tails. A “fair” coin is a coin with an equal chance of giving a head or a tail when flipped. An “unfair” coin might have a three fourths chance of giving a head and only a one quarter chance of giving a tail when flipped.
If I flip each coin once, I cannot tell the difference between the fair coin and the unfair coin. If I flip the two coins ten times, on average I will get five heads from the fair coin and seven and one half (seven or eight) heads from the unfair coin. It is still hard to tell the difference. With one hundred times, the fair coin will average fifty heads and the unfair coin seventy-five heads. There is still a small chance that the seventy five heads came from a fair coin.
The T statistics used in Student’s T test (Student was a pseudonym used by statistician William Sealy Gossett) and Welch’s T test, a more advanced T test, are measures of the difference in a statistical sense between two random data sets, such as the outcome of flipping coins one hundred times. The larger the T statistic the more different the two random data sets in a statistical sense.
William Sealy Gossett (Student)
Student’s T test and Welch’s T test convert the T statistics into probabilities that the difference between the two data sets (the “no advertising” and “advertising” sales data in our case) is due to chance. Student’s T test and Welch’s T test are included in Excel and many other financial and statistical programs.
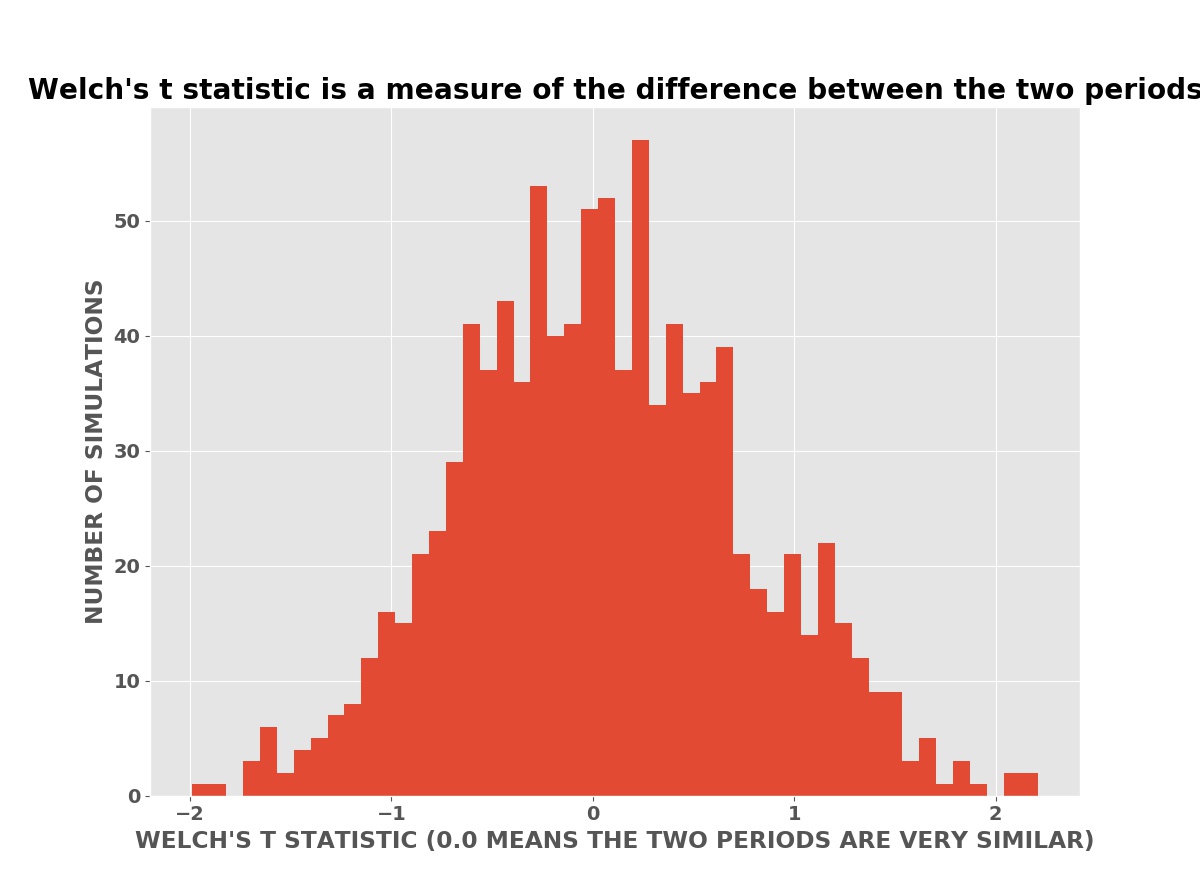
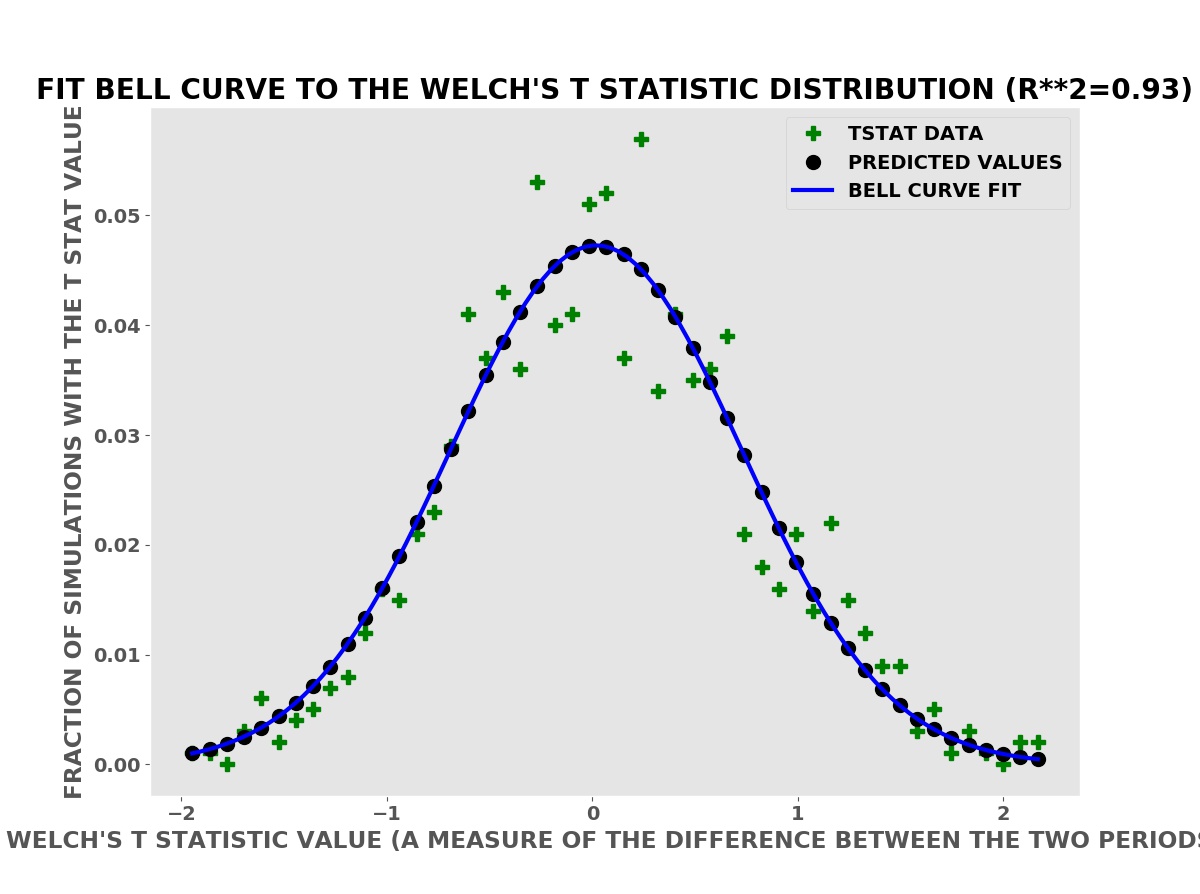
The plot below is a histogram (bar chart) of the number of simulations with a Welch’s T statistic value. In these simulations, the advertising has no effect on the daily sales (or profits). The advertising has no effect is the null hypothesis in the language of classical statistics.
Welch’s T Statistics
Welch was able to derive a mathematical formula for the expected distribution — shape of this histogram — using calculus. The mathematical formula could then be evaluated quickly with pencil and paper or an adding machine, the best available technology of his time (the 1940’s).
To derive his formula using calculus, Welch had to assume that the data had a Bell Curve (Normal or Gaussian) distribution. This is at best only approximately true for the sales data above. The distribution of daily sales in the simulated data is actually the Poisson distribution. The Poisson distribution is a better model of sales data and approximates the Bell Curve as the number of sales gets larger. This is why Welch’s T test is often approximately valid for sales data.
Many methods and tests in classical statistics assume a Bell Curve (Normal or Gaussian) distribution and are often approximately correct for real data that is not Bell Curve data. We can compute better, more reliable results with computer simulations using the actual or empirical probability distributions — shown below.
Welch’s T Statistic has Bell Curve Shape
More precisely, naming one data set the reference data and the other data set the test data, the T test computes the probability that the test data is due to a chance variation in the process that produced the reference data set. In the advertising example above, the “no advertising” period sales data is the reference data and the “advertising” sales data is the test data. Roughly this probability is the fraction of simulations in the Welch’s T statistic histogram that have a T statistic larger (or smaller for a negative T statistic) than the measured T statistic for the actual data. This probability is known as a p-value, a widely used statistic pioneered by Ronald Fisher.
Ronald Aylmer Fisher at the start of his career
The p-value has some obvious drawbacks for a business evaluating the effectiveness of advertising. At best it only tells us the probability that the advertising boosted sales or profits, not how large the boost was nor the risks. Even if on average the advertising boosts sales, what is the risk the advertising will fail or the sales increase will be too small to recover the cost of the advertising?
Fisher worked for Rothamsted Experimental Station in the United Kingdom where he wanted to know whether new breeds of crops, fertilizers, or other new agricultural methods increased yields. His friend and colleague Gossett worked for the Guinness beer company where he was working on improving yields and quality of beer. In both cases, they wanted to know whether a change in the process had a positive effect, not the size of the effect. Without modern computers — using only pencil and paper and adding machines — it was not practical to perform simulations as we can easily today.
Welch’s T statistic has a value of -3.28 for the above sales data. This is in fact lower than nearly all the simulations in the histogram. It is very unlikely the boost in sales is due to chance. The p-value from Welch’s T test for the advertising data above — computed using Welch’s mathematical formula — is only 0.001 (one tenth of one percent). Thus it is very likely the boost in sales is caused by the advertising and not random chance. Note that this does not tell us if the size of the boost, whether the advertising is cost effective, or the risk of the investment.
Sales and Profit Projections Using Computer Simulations
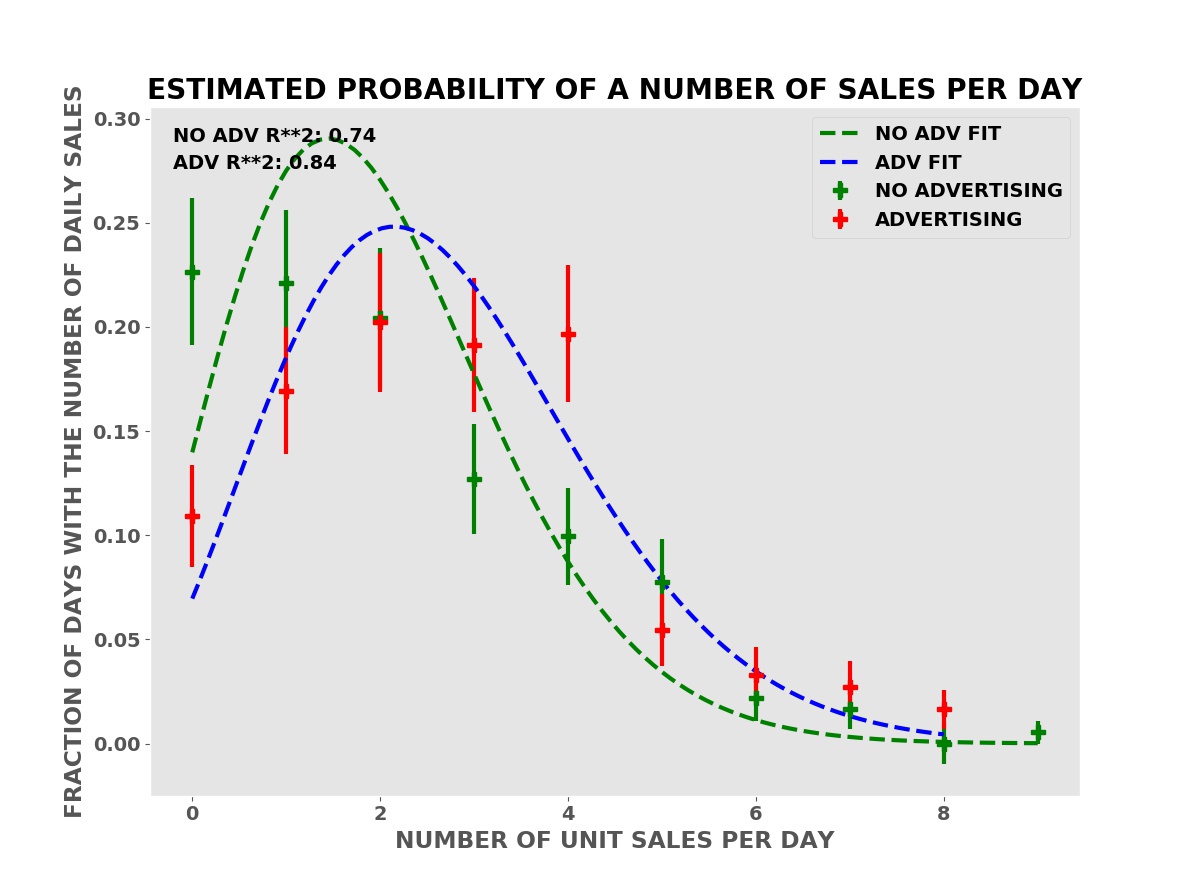
We can do much better than Student’s T test and Welch’s T test by using computer simulations based on the empirical probabilities of sales from the reference data — the “no advertising” period sales data. The simulations use random number generators to simulate the random nature of individual sales.
In these simulations, we simulate one year of business operations with advertising many times — one-thousand in the examples shown — using the frequency of sales from the period with advertising. We also simulate one year of business operations without the advertising, using the frequency of sales from the period without advertising in the sales data.
Frequency of Daily Sales in Both Periods
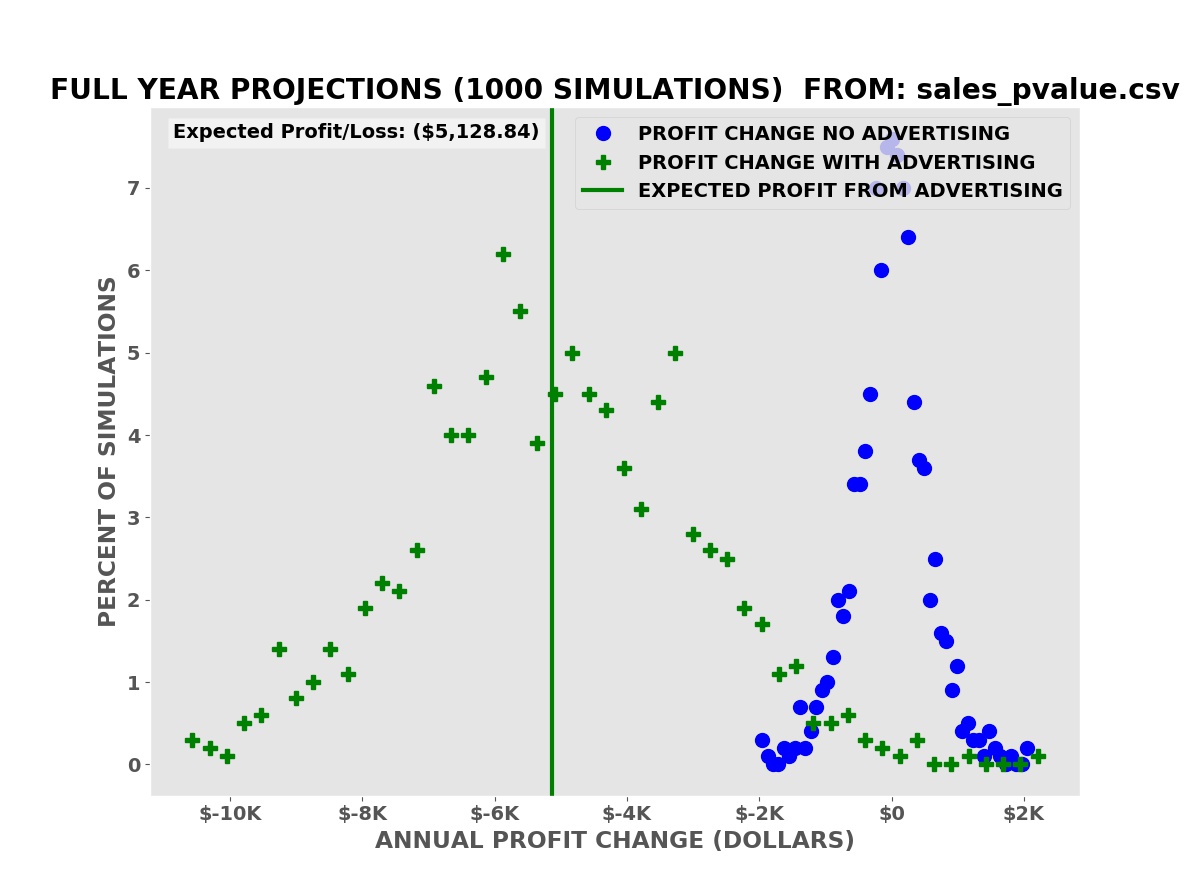
We compute the annual change in the profit relative to the corresponding period — with or without advertising — in the sales data for each simulated year of business operations.
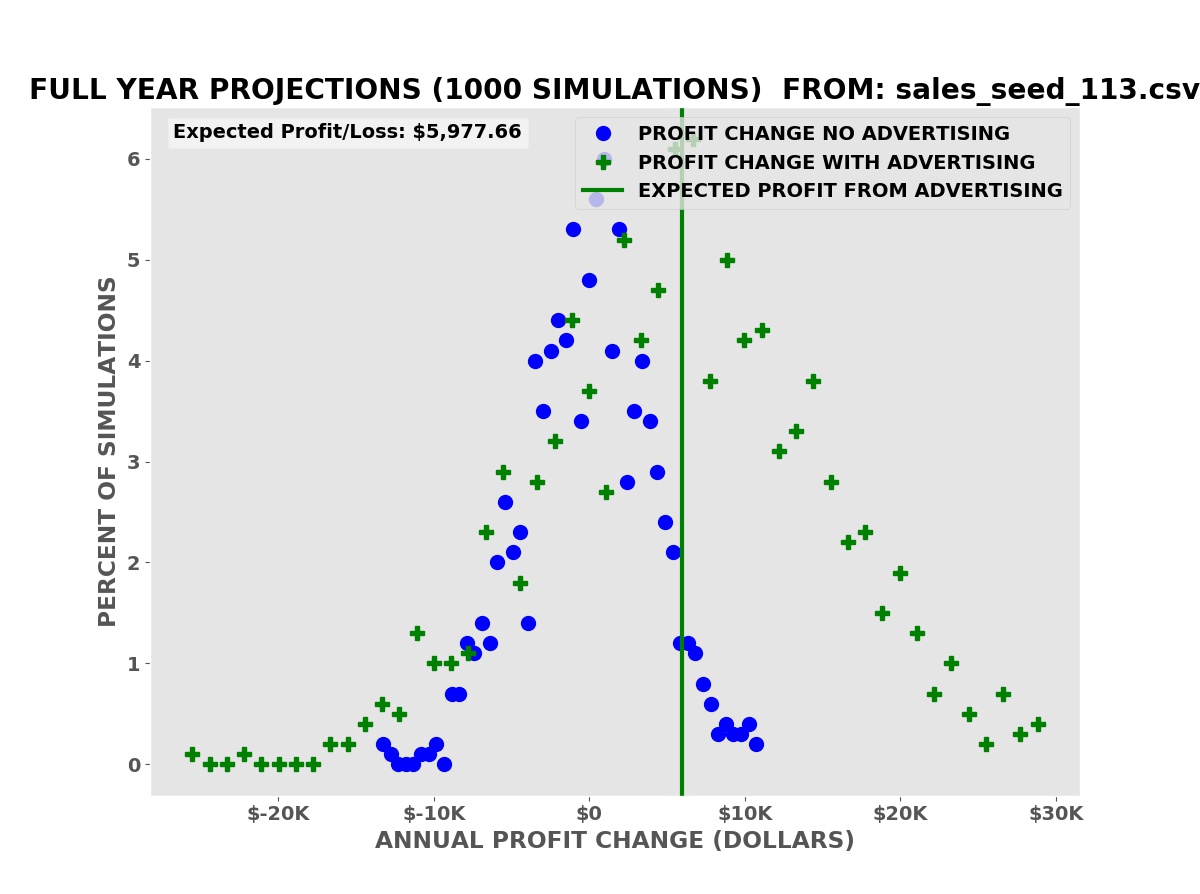
Annual Profit Projections
The simulations show that we have an average expected increase in profit of $5,977.66 over one year (our annual advertising cost is $6,000.00). It also shows that despite this there is a risk of a decrease in profits, some greater than the possible decreases with no advertising.
A business needs to know both the risks — how much money might be lost in a worst case — and the rewards — the average and best possible returns on the advertising investment.
Since sales are a random process like flipping a coin or throwing dice, there is a risk of a decline in profits or actual losses without the advertising. The question is whether the risk with advertising is greater, smaller, or the same. This is known as differential risk.
The Problem with p-values
This is a concrete example of the problem with p-values for evaluating the effectiveness of advertising. In this case, the advertising increases the average daily sales from 100 units per day to 101 units per day. Each unit costs one dollar (a candy bar for example).
P-VALUE SHOWS BOOST IN SALES
The p-value from Welch’s T test is 0.007 (seven tenths of one percent). The advertising is almost certainly effective but the boost in sales is much less than the cost of the advertising:
Profit Projections
The average expected decline in profits over the simulations is $5,128.84.
The p-value is not a good estimate of the potential risks and rewards of investing in advertising. Sales and profit projections from computer simulations based on a mathematical model derived from the reference sales data are a better (not perfect) estimate of the risks and rewards.
Multidimensional Sales Data
The above examples are simple cases where the only change is the addition of the advertising. There are no price changes, other advertising or marketing expenses, or other changes in business or economic conditions. There are no seasonal effects in the sales.
Student’s T test, Welch’s T test, and many other statistical tests are designed and valid only for simple controlled cases such as this where there is only one change between the reference and test data. These tests were well suited to data collected at the Rothamsted Experimental Station, Guinness breweries, and similar operations.
Modern businesses purchasing advertising from Facebook, other social media services, and modern media providers (e.g. the New York Times) face more complex conditions with many possible input variables (unit price, weather, unemployment rate, multiple advertising services, etc.) changing frequently or continuously.
For these, financial analysts need to extract predictive multidimensional mathematical models from the data and then perform similar simulations to evaluate the effect of advertising on sales and profits.
AdEvaluator™ is designed for cases with a single product or service with a constant unit price during both periods. AdEvaluator™ needs a reference period without the new advertising and a test period with the new advertising campaign. The new advertising campaign should be the only significant change between the two periods. AdEvaluator™ also assumes that the probability of the daily sales is independent and identically distributed during each period. This is not true in all cases. Exercise your professional business judgement whether the results of the simulations are applicable to your business.
This program comes with ABSOLUTELY NO WARRANTY; for details use -license option at the command line or select Help | License… in the graphical user interface (GUI). This is free software, and you are welcome to redistribute it under certain conditions.
We are developing a professional version of AdEvaluator™ for multidimensional cases. This version uses our Math Recognition™ technology to automatically identify good multidimensional mathematical models.
The Math Recognition™ technology is applicable to many types of data, not just sales and advertising data. It can for example be applied to complex biological systems such as the blood coagulation system which causes heart attacks and strokes when it fails. According the US Centers for Disease Control (CDC) about 633,000 people died from heart attacks and 140,000 from strokes in 2016.
Conclusion
It is often difficult to evaluate whether advertising is boosting sales and profits, despite the ready availability of sales and profit data for most businesses. This is caused by the unpredictable nature of individual sales and frequently by the complex multidimensional business environment where price changes, economic downturns and upturns, the weather, and other factors combine with the advertising to produce a confusing picture.
In simple cases with a single change, the addition of the new advertising, Student’s T test, Welch’s T test and other methods from classical statistics can help evaluate the effect of the advertising on sales and profits. These statistical tests can detect an effect but provide no clear estimate of the magnitude of the effect on sales and profits and the financial risks and rewards.
Sales and profit projections based on computer simulations using the empirical probability of sales from the actual sales data can provide quantitative estimates of the effect on sales and profits, including estimates of the financial risks (chance of losing money) and the financial rewards (typical and best case profits).
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This is a short article on how to control the order of slides in a slideshow on the Microsoft Windows 10 operating system. Slideshows can be quickly launched in Windows 10 using the Windows File Explorer by selecting the Manage tab and clicking on the Slideshow Icon.
Slide show icon in File Explorer
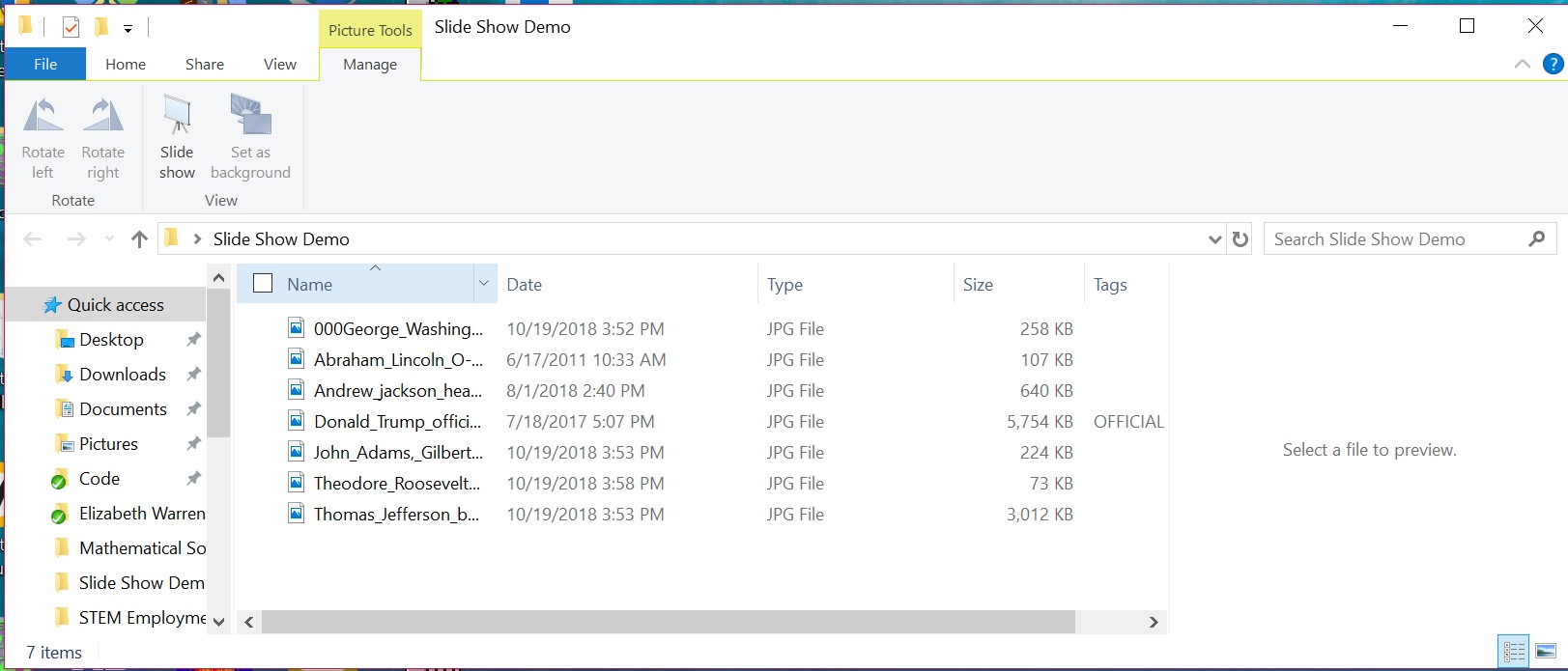
Usually, Windows 10 will display the picture files in the folder in the order displayed in the file explorer: alphabetically if Name is selected, by date if Date is selected, by file size if Size is selected, etc. In my experience on my system, this occasionally does not happen and the files are displayed alphabetically even though another view is selected. Thus, it is probably best to use alphabetical file names to ensure that the files display as desired.
Note that on Windows (and many computer systems) the numbers 0-9 come before A-Z, thus files that start with a number such as 000my_file_name.jpg will display before files that start with a letter such as my_file_name.jpg. In the example below, I use the prefix 000 to display the picture of George Washington first.
Alphabetical View in File Explorer
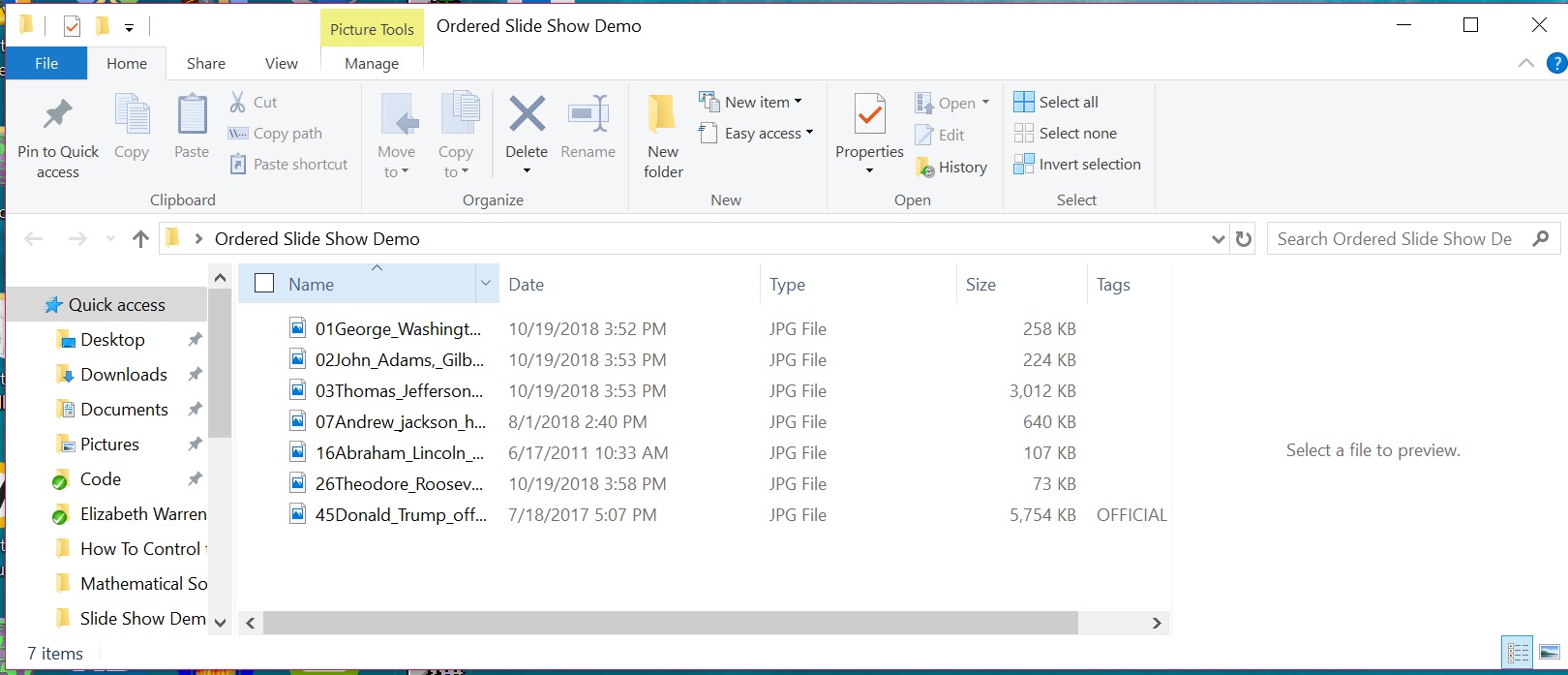
To display the Presidents in chronological order, I add a numeric prefix to each file in the folder. George Washington is the first President of the United States. John Adams is the second. Thomas Jefferson third. Andrew Jackson seventh. Abraham Lincoln sixteenth. Theodore Roosevelt twenty-sixth. Donald Trump forty-fifth.
Slideshow with US Presidents Ordered in Chronological Order
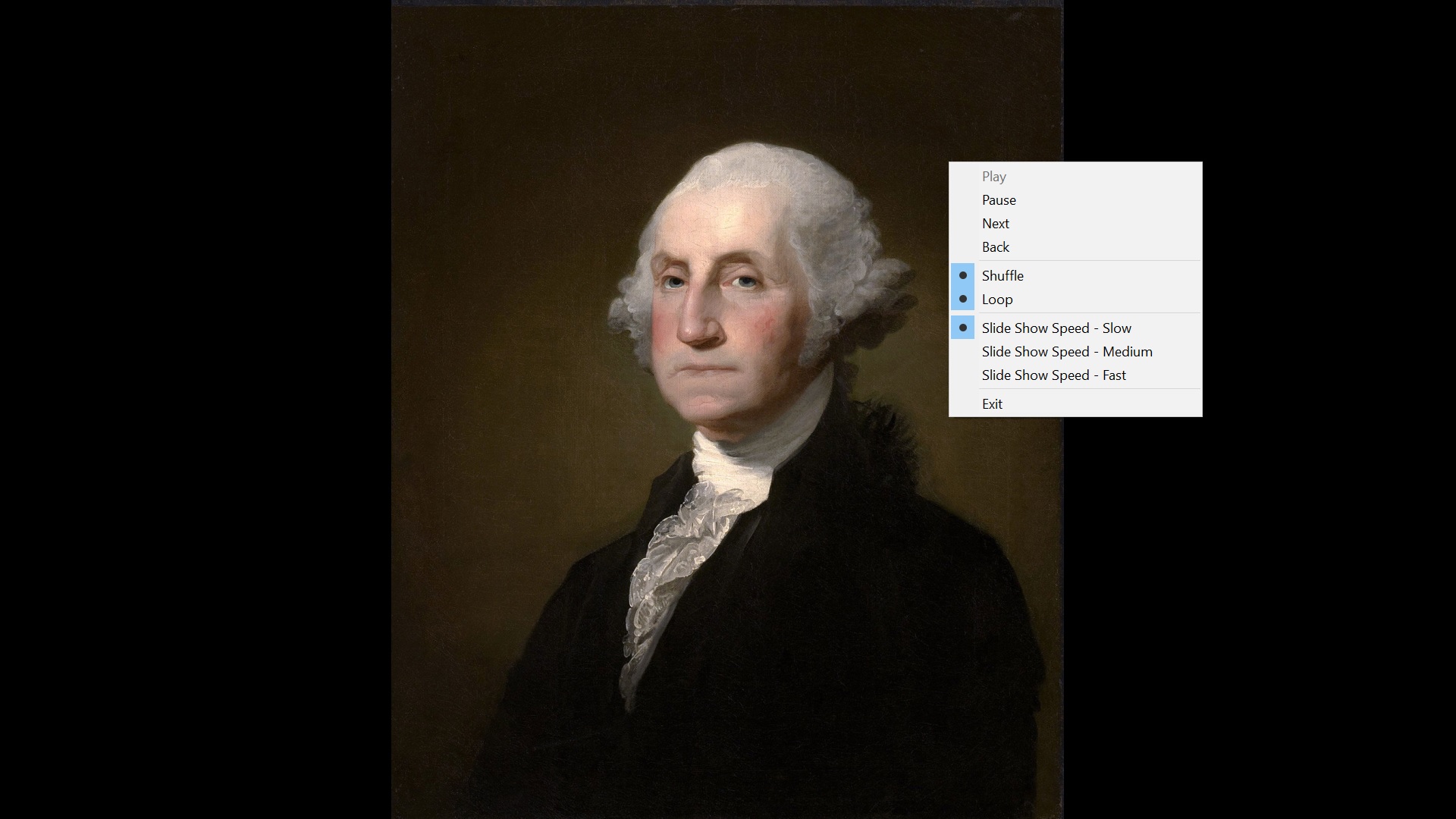
By default, Windows 10 plays the slide show in Loop mode with Shuffle mode off. In this mode, the slides are displayed in order.
Loop Mode Showing George Washington First
Right clicking with the mouse or other pointing device during the slide show brings up a popup menu with the Loop and Shuffle modes as well as other controls.
In the shuffle mode, the first slide is always displayed first. I will still get George Washington first in my example. All subsequent slides are displayed in random order. This seems like a bug; I would prefer the first slide to also be random.
Shuffle Mode Showing George Washington First
NOTE: If for some reason you do not like the first slide displayed every time in shuffle mode, add a prefix to a picture file that you would prefer to be first to place it alphabetically before all other picture files in the folder.
Once shuffle mode or other controls (slow or fast for example) are selected, the selections remain in force for subsequent slide shows until changed.
That is how to control the order of slides in a slide show in Microsoft Windows 10.
This is a short video on how to control the order of slides in a slide show on Windows 10:
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
It is common to encounter claims of a “desperate” or “severe” shortage of STEM (Science, Technology, Engineering, and Mathematics) workers, either current or projected, usually from employers of STEM workers. These claims are perennial and date back at least to the 1940’s after World War II despite the huge number of STEM workers employed in wartime STEM projects (the Manhattan Project that developed the atomic bomb, military radar, code breaking machines and computers, the B-29 and other high tech bombers, the development of penicillin, K-rations, etc.). This article takes a look at the STEM degree numbers in the National Science Foundation’s Science and Engineering Indicators 2018 report.
College STEM Degrees (NSF Science and Engineering Indicators 2018)
I looked at the total Science and Engineering bachelors degrees granted each year which includes degrees in Social Science, Psychology, Biological and agricultural sciences as well as hard core Engineering, Computer Science, Mathematics, and Physical Sciences. I also looked specifically at the totals for “hard” STEM degrees (Engineering, Computer Science, Mathematics, and Physical Sciences). I also included the total number of K-12 students who pass (score 3,4, or 5 out of 5) on the Advanced Placement (AP) Calculus Exam (either the AB exam or the more advanced BC exam) each year.
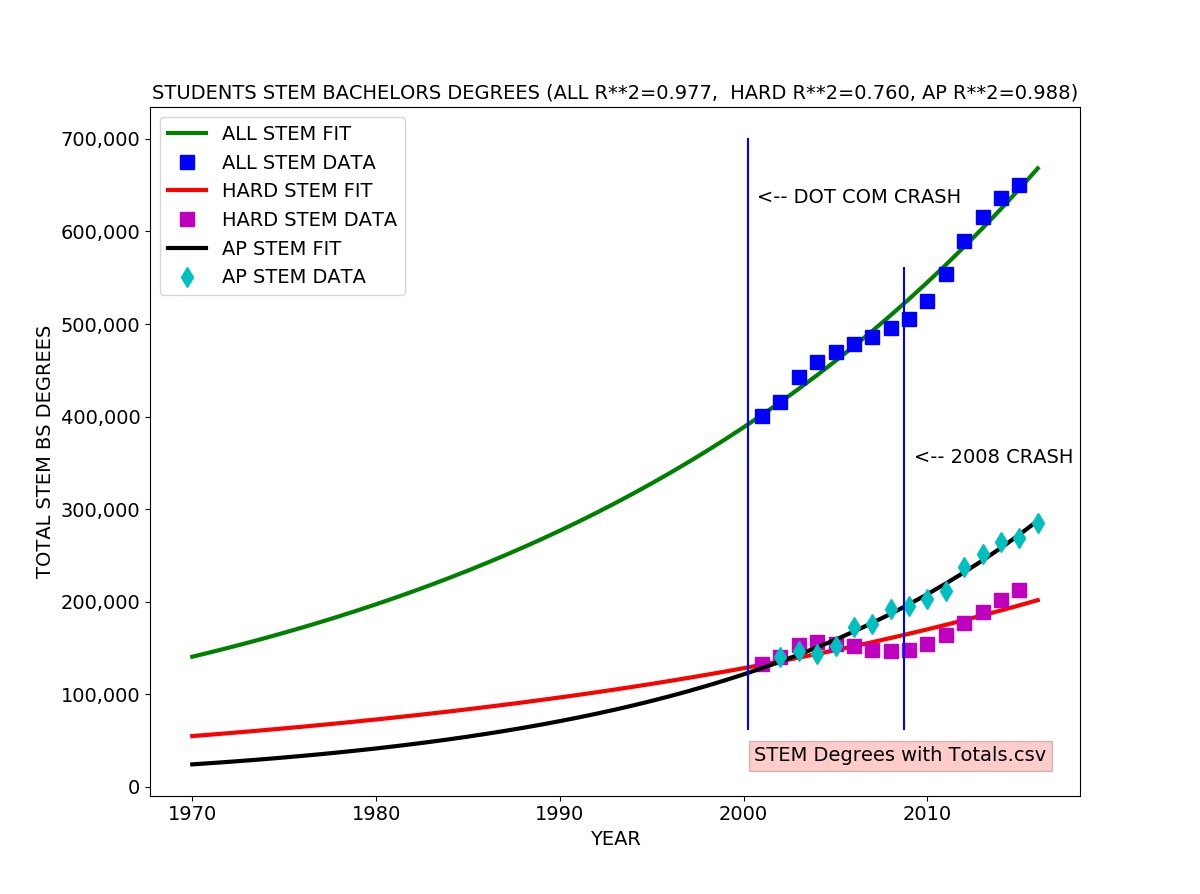
I fitted an exponential growth model to each data series. The exponential growth model fits well to the total STEM degrees and AP passing data. The exponential growth model roughly agrees with the hard STEM degree data, but there is a clear difference, reflected in the coefficient of determination (R-SQUARED) of 0.76 meaning the model explains about 76 percent of the variation in the data.
One can easily see the the number of hard STEM degrees significantly exceeds the trend line in the early 00’s (2000 to about 2004) and drops well below from 2004 to 2008, rebounding in 2008. This probably reflects the surge in CS degrees specifically due to the Internet/dot com bubble (1995-2001).
There appears to be a lag of about four years between the actual dot com crash usually dated to a stock market drop in March of 2000 and the drop in production of STEM bachelor’s degrees in about 2004.
Analysis results:
TOTAL Scientists and Engineers 2016: 6,900,000
ALL STEM Bachelor's Degrees
ESTIMATED TOTAL IN 2016 SINCE 1970: 15,970,052
TOTAL FROM 2001 to 2015 (Science and Engineering Indicators 2018) 7,724,850
ESTIMATED FUTURE STUDENTS (2016 to 2026): 8,758,536
ANNUAL GROWTH RATE: 3.45 % US POPULATION GROWTH RATE (2016): 0.7 %
HARD STEM DEGREES ONLY (Engineering, Physical Sciences, Math, CS)
ESTIMATED TOTAL IN 2016 SINCE 1970: 5,309,239
TOTAL FROM 2001 to 2015 (Science and Engineering Indicators 2018) 2,429,300
ESTIMATED FUTURE STUDENTS (2016 to 2026): 2,565,802
ANNUAL GROWTH RATE: 2.88 % US POPULATION GROWTH RATE (2016): 0.7 %
STUDENTS PASSING AP CALCULUS EXAM
ESTIMATED TOTAL IN 2016 SINCE 1970: 5,045,848
TOTAL FROM 2002 to 2016 (College Board) 3,038,279
ESTIMATED FUTURE STUDENTS (2016 to 2026): 4,199,602
ANNUAL GROWTH RATE: 5.53 % US POPULATION GROWTH RATE (2016): 0.7 %
estimate_college_stem.py ALL DONE
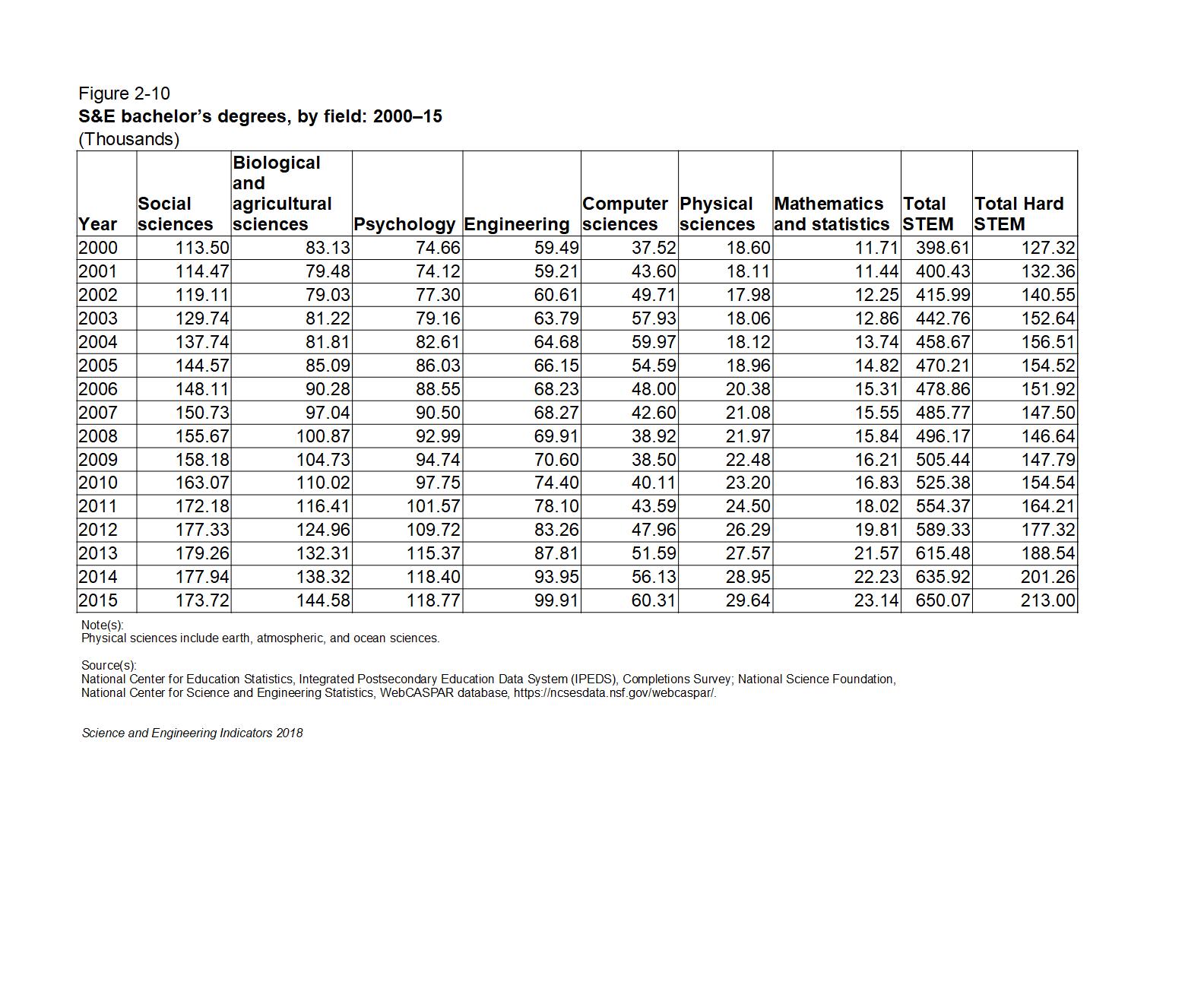
The table below gives the raw numbers from Figure 02-10 in the NSF Science and Engineering Indicators 2018 report with a column for total STEM degrees and a column for total STEM degrees in hard science and technology subjects (Engineering, Computer Science, Mathematics, and Physical Sciences) added for clarity:
STEM Degrees Table fig02-10 Revised
In the raw numbers, we see steady growth in social science and psychology STEM degrees from 2000 to 2015 with no obvious sign of the Internet/dot com bubble. There is a slight drop in Biological and agricultural sciences degrees in the early 00s. Somewhat larger drops can be seen in Engineering and Physical Sciences degrees in the early 00’s as well as a concomittant sharp rise in Computer Science (CS) degrees. This probably reflects strong STEM students shifting into CS degrees.
The number of K-12 students taking and passing the AP Calculus Exam (either the AB or more advanced BC exam) grows continuously and rapidly during the entire period from 1997 to 2016, growing at over five percent per year, far above the United States population growth rate of 0.7 percent per year.
The number of college students earning hard STEM degrees appears to be slightly smaller than the four year lagged number of K-12 students passing the AP exam, suggesting some attrition of strong STEM students at the college level. We might expect the number of hard STEM bachelors degrees granted each year to be the same or very close to the number of AP Exam passing students four years earlier.
A model using only the hard STEM bachelors degree students gives a total number of STEM college students produced since 1970 of five million, pretty close to the number of K-12 students estimated from the AP Calculus exam data. This is somewhat less than the 6.9 million total employed STEM workers estimated by the United States Bureau of Labor Statistics.
Including all STEM degrees gives a huge surplus of STEM students/workers, most not employed in a STEM field as reported by the US Census and numerous media reports.
The hard STEM degree model predicts about 2.5 million new STEM workers graduating between 2016 and 2026. This is slightly more than the number of STEM job openings seemingly predicted by the Bureau of Labor Statistics (about 800,000 new STEM jobs and about 1.5 million retirements and deaths of current aging STEM workers giving a total of about 2.3 million “new” jobs). The AP student model predicts about 4 million new STEM workers, far exceeding the BLS predictions and most other STEM employment predictions.
The data and models do not include the effects of immigration and guest worker programs such as the controversial H1-B visa, L1 visa, OPT visa, and O (“Genius”) visa. Immigrants and guest workers play an outsized role in the STEM labor force and specifically in the computer science/software labor force (estimated at 3-4 million workers, over half of the STEM labor force).
Difficulty of Evaluating “Soft” STEM Degrees
Social science, psychology, biological and agricultural sciences STEM degrees vary widely in rigor and technical requirements. The pioneering statistician Ronald Fisher developed many of his famous methods as an agricultural researcher at the Rothamsted agricultural research institute. The leading data analysis tool SAS from the SAS Institute was originally developed by agricultural researchers at North Carolina State University. IBM’s SPSS (Statistics Package for Social Sciences) data analysis tool, number three in the market, was developed for social sciences. Many “hard” sciences such as experimental particle physics use methods developed by Fisher and other agricultural and social scientists. Nonetheless, many “soft” science STEM degrees do not involve the same level of quantitative, logical, and programming skills typical of “hard” STEM fields.
In general, STEM degrees at the college level are not highly standardized. There is no national or international standard test or tests comparable to the AP Calculus exams at the K-12 level to get a good national estimate of the number of qualified students.
The numbers suggest but do not prove that most K-12 students who take and pass AP Calculus continue on to hard STEM degrees or some type of rigorous biology or agricultural sciences degree — hence the slight drop in biology and agricultural science degrees during the dot com bubble period with students shifting to CS degrees.
Conclusion
Both the college “hard” STEM degree data and the K-12 AP Calculus exam data strongly suggest that the United States can and will produce more qualified STEM students than job openings predicted for the 2016 to 2026 period. Somewhat more according to the college data, much more according to the AP exam data, and a huge surplus if all STEM degrees including psychology and social science are considered. The data and models do not include the substantial number of immigrants and guest workers in STEM jobs in the United States.
NOTE: The raw data in text CSV (comma separated values) format and the Python analysis program are included in the appendix below.
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Year,Social sciences,Biological and agricultural sciences,Psychology,Engineering,Computer sciences,Physical sciences,Mathematics and statistics,Total STEM,Total Hard STEM
2000,113.50,83.13,74.66,59.49,37.52,18.60,11.71,398.61,127.32
2001,114.47,79.48,74.12,59.21,43.60,18.11,11.44,400.43,132.36
2002,119.11,79.03,77.30,60.61,49.71,17.98,12.25,415.99,140.55
2003,129.74,81.22,79.16,63.79,57.93,18.06,12.86,442.76,152.64
2004,137.74,81.81,82.61,64.68,59.97,18.12,13.74,458.67,156.51
2005,144.57,85.09,86.03,66.15,54.59,18.96,14.82,470.21,154.52
2006,148.11,90.28,88.55,68.23,48.00,20.38,15.31,478.86,151.92
2007,150.73,97.04,90.50,68.27,42.60,21.08,15.55,485.77,147.50
2008,155.67,100.87,92.99,69.91,38.92,21.97,15.84,496.17,146.64
2009,158.18,104.73,94.74,70.60,38.50,22.48,16.21,505.44,147.79
2010,163.07,110.02,97.75,74.40,40.11,23.20,16.83,525.38,154.54
2011,172.18,116.41,101.57,78.10,43.59,24.50,18.02,554.37,164.21
2012,177.33,124.96,109.72,83.26,47.96,26.29,19.81,589.33,177.32
2013,179.26,132.31,115.37,87.81,51.59,27.57,21.57,615.48,188.54
2014,177.94,138.32,118.40,93.95,56.13,28.95,22.23,635.92,201.26
2015,173.72,144.58,118.77,99.91,60.31,29.64,23.14,650.07,213.00
estimate_college_stem.py
#
# Estimate the total production of STEM students at the
# College level from BS degrees granted (United States)
#
# (C) 2018 by John F. McGowan, Ph.D. (ceo@mathematical-software.com)
#
# Python standard libraries
import os
import sys
import time
# Numerical/Scientific Python libraries
import numpy as np
import scipy.optimize as opt # curve_fit()
import pandas as pd # reading text CSV files etc.
# Graphics
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from mpl_toolkits.mplot3d import Axes3D
# customize fonts
SMALL_SIZE = 8
MEDIUM_SIZE = 10
LARGE_SIZE = 12
XL_SIZE = 14
XXL_SIZE = 16
plt.rc('font', size=XL_SIZE) # controls default text sizes
plt.rc('axes', titlesize=XL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=XL_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=XL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=XL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=XL_SIZE) # legend fontsize
plt.rc('figure', titlesize=XL_SIZE) # fontsize of the figure title
# STEM Bachelors Degrees earned by year (about 2000 to 2015)
#
# data from National Science Foundation (NSF)/ National Science Board
# Science and Engineering Indicators 2018 Report
# https://www.nsf.gov/statistics/2018/nsb20181/
# Figure 02-10
#
input_file = "STEM Degrees with Totals.csv"
if len(sys.argv) > 1:
index = 1
while index < len(sys.argv):
if sys.argv[index] in ["-i", "-input"]:
input_file = sys.argv[index+1]
index += 1
elif sys.argv[index] in ["-h", "--help", "-help", "-?"]:
print("Usage:", sys.argv[0], " -i input_file='AP Calculus Totals by Year.csv'")
sys.exit(0)
index +=1
print(__file__, "started", time.ctime()) # time stamp
print("Processing data from: ", input_file)
# read text CSV file (exported from spreadsheet)
df = pd.read_csv(input_file)
# drop NaNs for missing values in Pandas
df.dropna()
# get number of students who pass AP Calculus Exam (AB or BC)
# each year
df_ap_pass = pd.read_csv("AP Calculus Totals.csv")
ap_year = df_ap_pass.values[:,0]
ap_total = df_ap_pass.values[:,1]
# numerical data
hard_stem_str = df.values[1:,-1] # engineering, physical sciences, math/stat, CS
all_stem_str = df.values[1:,-2] # includes social science, psychology, agriculture etc.
hard_stem = np.zeros(hard_stem_str.shape)
all_stem = np.zeros(all_stem_str.shape)
for index, val in enumerate(hard_stem_str.ravel()):
if isinstance(val, str):
hard_stem[index] = np.float(val.replace(',',''))
elif isinstance(val, (float, np.float)):
hard_stem[index] = val
else:
raise TypeError("unsupported type " + str(type(val)))
for index, val in enumerate(all_stem_str.ravel()):
if isinstance(val, str):
all_stem[index] = np.float(val.replace(',', ''))
elif isinstance(val, (float, np.float)):
all_stem[index] = val
else:
raise TypeError("unsupported type " + str(type(val)))
DEGREES_PER_UNIT = 1000
# units are thousands of degrees granted
all_stem = DEGREES_PER_UNIT*all_stem
hard_stem = DEGREES_PER_UNIT*hard_stem
years_str = df.values[1:,0]
years = np.zeros(years_str.shape)
for index, val in enumerate(years_str.ravel()):
years[index] = np.float(val)
# almost everyone in the labor force graduated since 1970
# someone 18 years old in 1970 is 66 today (2018)
START_YEAR = 1970
def my_exp(x, *p):
"""
exponential model for curve_fit(...)
"""
return p[0]*np.exp(p[1]*(x - START_YEAR))
# starting guess for model parameters
p_start = [ 50000.0, 0.01 ]
# fit all STEM degree data
popt, pcov = opt.curve_fit(my_exp, years, all_stem, p_start)
# fit hard STEM degree data
popt_hard_stem, pcov_hard_stem = opt.curve_fit(my_exp, \
years, \
hard_stem, \
p_start)
# fit AP Students data
popt_ap, pcov_ap = opt.curve_fit(my_exp, \
ap_year, \
ap_total, \
p_start)
print(popt) # sanity check
STOP_YEAR = 2016
NYEARS = (STOP_YEAR - START_YEAR + 1)
years_fit = np.linspace(START_YEAR, STOP_YEAR, NYEARS)
n_fit = my_exp(years_fit, *popt)
n_pred = my_exp(years, *popt)
r2 = 1.0 - (n_pred - all_stem).var()/all_stem.var()
r2_str = "%4.3f" % r2
n_fit_hard = my_exp(years_fit, *popt_hard_stem)
n_pred_hard = my_exp(years, *popt_hard_stem)
r2_hard = 1.0 - (n_pred_hard - hard_stem).var()/hard_stem.var()
r2_hard_str = "%4.3f" % r2_hard
n_fit_ap = my_exp(years_fit, *popt_ap)
n_pred_ap = my_exp(ap_year, *popt_ap)
r2_ap = 1.0 - (n_pred_ap - ap_total).var()/ap_total.var()
r2_ap_str = "%4.3f" % r2_ap
cum_all_stem = n_fit.sum()
cum_hard_stem = n_fit_hard.sum()
cum_ap_stem = n_fit_ap.sum()
# to match BLS projections
future_years = np.linspace(2016, 2026, 11)
assert future_years.size == 11 # sanity check
future_students = my_exp(future_years, *popt)
future_students_hard = my_exp(future_years, *popt_hard_stem)
future_students_ap = my_exp(future_years, *popt_ap)
# https://fas.org/sgp/crs/misc/R43061.pdf
#
# The U.S. Science and Engineering Workforce: Recent, Current,
# and Projected Employment, Wages, and Unemployment
#
# by John F. Sargent Jr.
# Specialist in Science and Technology Policy
# November 2, 2017
#
# Congressional Research Service 7-5700 www.crs.gov R43061
#
# "In 2016, there were 6.9 million scientists and engineers (as
# defined in this report) employed in the United States, accounting
# for 4.9 % of total U.S. employment."
#
# BLS astonishing/bizarre projections for 2016-2026
# "The Bureau of Labor Statistics (BLS) projects that the number of S&E
# jobs will grow by 853,600 between 2016 and 2026 , a growth rate
# (1.1 % CAGR) that is somewhat faster than that of the overall
# workforce ( 0.7 %). In addition, BLS projects that 5.179 million
# scientists and engineers will be needed due to labor force exits and
# occupational transfers (referred to collectively as occupational
# separations ). BLS projects the total number of openings in S&E due to growth ,
# labor force exits, and occupational transfers between 2016 and 2026 to be
# 6.033 million, including 3.477 million in the computer occupations and
# 1.265 million in the engineering occupations."
# NOTE: This appears to project 5.170/6.9 or 75 percent!!!! of current STEM
# labor force LEAVE THE STEM PROFESSIONS by 2026!!!!
# "{:,}".format(value) to specify the comma separated thousands format
#
print("TOTAL Scientists and Engineers 2016:", "{:,.0f}".format(6.9e6))
# ALL STEM
print("\nALL STEM Bachelor's Degrees")
print("ESTIMATED TOTAL IN 2016 SINCE ", START_YEAR, ": ", \
"{:,.0f}".format(cum_all_stem), sep='')
# don't use comma grouping for years
print("TOTAL FROM", "{:.0f}".format(years_str[0]), \
"to 2015 (Science and Engineering Indicators 2018) ", \
"{:,.0f}".format(all_stem.sum()))
print("ESTIMATED FUTURE STUDENTS (2016 to 2026):", \
"{:,.0f}".format(future_students.sum()))
# annual growth rate of students taking AP Calculus
growth_rate_pct = (np.exp(popt[1]) - 1.0)*100
print("ANNUAL GROWTH RATE: ", "{:,.2f}".format(growth_rate_pct), \
"% US POPULATION GROWTH RATE (2016): 0.7 %")
# HARD STEM
print("\nHARD STEM DEGREES ONLY (Engineering, Physical Sciences, Math, CS)")
print("ESTIMATED TOTAL IN 2016 SINCE ", START_YEAR, ": ", \
"{:,.0f}".format(cum_hard_stem), sep='')
# don't use comma grouping for years
print("TOTAL FROM", "{:.0f}".format(years_str[0]), \
"to 2015 (Science and Engineering Indicators 2018) ", \
"{:,.0f}".format(hard_stem.sum()))
print("ESTIMATED FUTURE STUDENTS (2016 to 2026):", \
"{:,.0f}".format(future_students_hard.sum()))
# annual growth rate of students taking AP Calculus
growth_rate_pct_hard = (np.exp(popt_hard_stem[1]) - 1.0)*100
print("ANNUAL GROWTH RATE: ", "{:,.2f}".format(growth_rate_pct_hard), \
"% US POPULATION GROWTH RATE (2016): 0.7 %")
# AP STEM -- Students passing AP Calculus Exam Each Year
print("\nSTUDENTS PASSING AP CALCULUS EXAM")
print("ESTIMATED TOTAL IN 2016 SINCE ", START_YEAR, ": ", \
"{:,.0f}".format(cum_ap_stem), sep='')
# don't use comma grouping for years
print("TOTAL FROM", "{:.0f}".format(ap_year[-1]), \
"to", "{:.0f}".format(ap_year[0])," (College Board) ", \
"{:,.0f}".format(ap_total.sum()))
print("ESTIMATED FUTURE STUDENTS (2016 to 2026):", \
"{:,.0f}".format(future_students_ap.sum()))
# annual growth rate of students taking AP Calculus
growth_rate_pct_ap = (np.exp(popt_ap[1]) - 1.0)*100
print("ANNUAL GROWTH RATE: ", "{:,.2f}".format(growth_rate_pct_ap), \
"% US POPULATION GROWTH RATE (2016): 0.7 %")
# US Census reports 0.7 percent annual growth of US population in 2016
# SOURCE: https://www.census.gov/newsroom/press-releases/2016/cb16-214.html
#
f1 = plt.figure(figsize=(12,9))
ax = plt.gca()
# add commas to tick values (e.g. 1,000 instead of 1000)
ax.get_yaxis().set_major_formatter(
ticker.FuncFormatter(lambda x, p: format(int(x), ',')))
DOT_COM_CRASH = 2000.25 # usually dated march 10, 2000
OCT_2008_CRASH = 2008.75 # usually dated October 11, 2008
DELTA_LABEL_YEARS = 0.5
plt.plot(years_fit, n_fit, 'g', linewidth=3, label='ALL STEM FIT')
plt.plot(years, all_stem, 'bs', markersize=10, label='ALL STEM DATA')
plt.plot(years_fit, n_fit_hard, 'r', linewidth=3, label='HARD STEM FIT')
plt.plot(years, hard_stem, 'ms', markersize=10, label='HARD STEM DATA')
plt.plot(years_fit, n_fit_ap, 'k', linewidth=3, label='AP STEM FIT')
plt.plot(ap_year, ap_total, 'cd', markersize=10, label='AP STEM DATA')
[ylow, yhigh] = plt.ylim()
dy = yhigh - ylow
# add marker lines for crashes
plt.plot((DOT_COM_CRASH, DOT_COM_CRASH), (ylow+0.1*dy, yhigh), 'b-')
plt.text(DOT_COM_CRASH + DELTA_LABEL_YEARS, 0.9*yhigh, '<-- DOT COM CRASH')
# plt.arrow(...) add arrow (arrow does not render correctly)
plt.plot((OCT_2008_CRASH, OCT_2008_CRASH), (ylow+0.1*dy, 0.8*yhigh), 'b-')
plt.text(OCT_2008_CRASH+DELTA_LABEL_YEARS, 0.5*yhigh, '<-- 2008 CRASH')
plt.legend()
plt.title('STUDENTS STEM BACHELORS DEGREES (ALL R**2=' \
+ r2_str + ', HARD R**2=' + r2_hard_str + \
', AP R**2=' + r2_ap_str + ')')
plt.xlabel('YEAR')
plt.ylabel('TOTAL STEM BS DEGREES')
# appear to need to do this after the plots
# to get valid ranges
[xlow, xhigh] = plt.xlim()
[ylow, yhigh] = plt.ylim()
dx = xhigh - xlow
dy = yhigh - ylow
# put input data file name in lower right corner
plt.text(xlow + 0.65*dx, \
ylow + 0.05*dy, \
input_file, \
bbox=dict(facecolor='red', alpha=0.2))
plt.show()
f1.savefig('College_STEM_Degrees.jpg')
print(__file__, "ALL DONE")
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
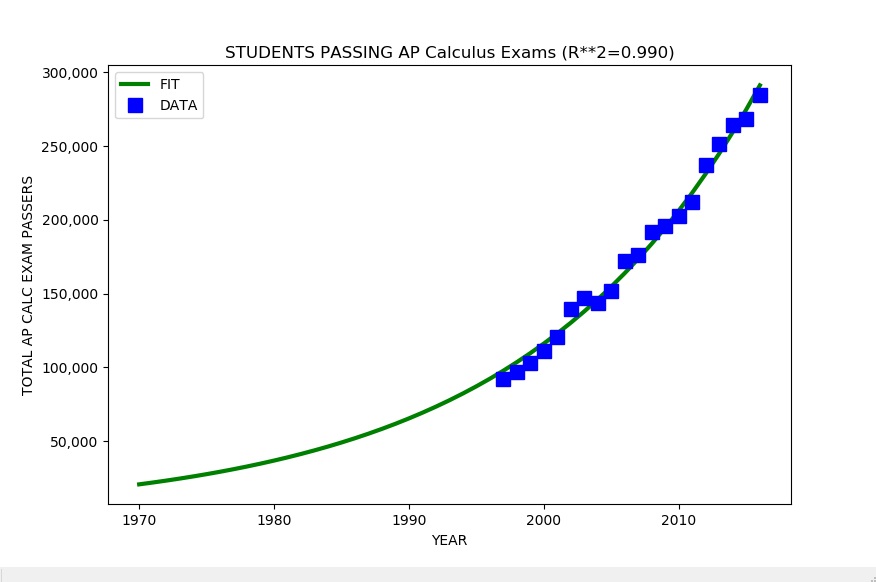
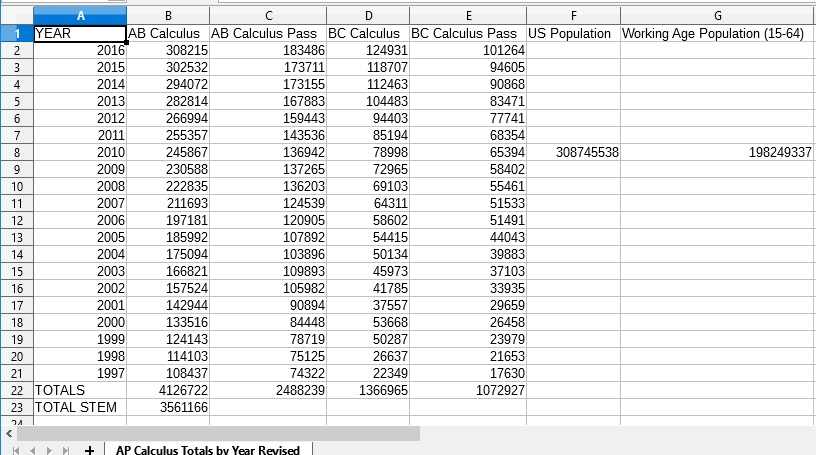
This is a followup to my previous post “A Skeptical Look at STEM Shortage Numbers”. I was able to decipher all the archived data on Advanced Placement (AP) Calculus exams on the College Board web site back to 1997, twenty-one years ago. My previous numbers were from 2002 to 2016 due to harder to decipher formatting of the archived data in 1997 through 2001. This adds an additional five years to the actual data.
AP Calculus Totals by Year (1997-2016)
Repeating my analysis with the new improved numbers gives the following results (see plot above as well):
TOTAL Employed Scientists and Engineers in 2016: 6,900,000.0
ESTIMATED TOTAL PASSING AP CALCULUS SINCE 1970: 4,869,476
ACTUAL TOTAL FROM 1997 to 2016 (College Board Data): 3,561,166.0
ESTIMATED FUTURE STUDENTS (2016 to 2026): 4,337,880
ANNUAL GROWTH RATE OF STUDENTS PASSING AP CALCULUS: 5.9%
US POPULATION GROWTH RATE (2016): 0.7 %
Rapid Growth in Students Taking and Passing AP Calculus
I added an estimate of the annual percent increase in the number of US students taking and passing the AP Calculus exams to the analysis. The analysis shows a steady rapid growth of almost six (5.9) percent per year since 1997. This is much higher than the annual population growth rate in the United States (0.7 percent in 2016).
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).