I will be giving a presentation (about 30 minutes) to the Bay Area SAS User’s Group (BASAS) this Thursday, August 31, 2017 (12:30 PM – 4 PM) at Genentech in South San Francisco, CA: Automating Complex Data Analysis for Fun, Profit, and the Greater Good.
Complex data analysis attempts to solve problems with one or more inputs and one or more outputs related by complex mathematical rules, usually a sequence of two or more non-linear functions applied iteratively to the inputs and intermediate computed values. A prominent example is determining the causes and possible treatments for poorly understood diseases such as heart disease, cancer, and autism spectrum disorders where multiple genetic and environmental factors may contribute to the disease and the disease has multiple symptoms and metrics, e.g. blood pressure, heart rate, and heart rate variability.
Another example are macroeconomic models predicting employment levels, inflation, economic growth, foreign exchange rates and other key economic variables for investment decisions, both public and private, from inputs such as government spending, budget deficits, national debt, population growth, immigration, and many other factors.
A third example is speech recognition where a complex non-linear function somehow maps from a simple sequence of audio measurements — the microphone sound pressure levels — to a simple sequence of recognized words: “I’m sorry Dave. I can’t do that.”
State-of-the-art complex data analysis is labor intensive, time consuming, and error prone — requiring highly skilled analysts, often Ph.D.’s or other highly educated professionals, using tools with large libraries of built-in statistical and data analytical methods and tests: SAS, MATLAB, the R statistical programming language and similar tools. Results often take months or even years to produce, are often difficult to reproduce, difficult to present convincingly to non-specialists, difficult to audit for regulatory compliance and investor due diligence, and sometimes simply wrong, especially where the data involves human subjects or human society.
This talk discusses the current state-of-the-art in attempts to automate complex data analysis. It discusses widely used tools such as SAS and MATLAB and their current limitations. It discusses what the automation of complex data analysis may look like in the future, possible methods of automating complex data analysis, and problems and pitfalls of automating complex data analysis. The talk will include a demonstration of a prototype system for automating complex data analysis including automated generation of SAS analysis code.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I attended a “Machine Learning at Google” event at the Google Quad 3 building off Ellis in Mountain View last night (August 23, 2017). This seemed to be mostly a recruiting event for some or all of Google’s high profile Machine Learning/Deep Learning groups, notably the team responsible for TensorFlow.
Woman Opens Event
I had no trouble finding the registration table when I arrived and getting my badge. All the presentations seemed to run on time or nearly on time. There was free food, a cute bag with Google gewgaws, and plenty of seating (about 280 seats with attendance about 240 I thought).
The event invitation that I received was rather vague and it did not become clear this was a recruiting event until well into the event. It had the alluring title:
An Exclusive Invite | Machine Learning @ Google
Ooh, exclusive! Aren’t I special! Along with 240 other attendees as it turned out. 🙂
Andrew Zaldivar (see below) explicitly called it a recruiting event in the Q&A panel at the end. It would have been good to know this as I am not looking for a job at Google. That does not mean the event wasn’t interesting to me for other reasons, but Google and other companies should be up front about this.
Although I think the speakers were on a low platform, they weren’t up high enough to see that well, even though I was in the front. This was particularly true of Jasmine Hsu who was short. I managed to get one picture of her not fully or mostly obscured by someone’s head. Probably a higher platform for the presenters would have helped.
A good looking woman who seemed to be some sort of public relations or marketing person opened the event at 6:30 PM. She went through all the usual event housekeeping and played a slick Madison Avenue style video on the coming wonders of machine learning. Then she introduced the keynote speaker Ravi Kumar.
Ravi Kumar Keynote
Ravi was followed by a series of “lightning talks” on machine learning and deep learning at Google by Sandeep Tata, Heng-Tze Cheng, Ian Goodfellow, James Kunz, Jasmine Hsu, and Andrew Zaldivar.
The presentations tended to blur together. The typical machine learning/deep learning presentation is an extremely complex model that has been fitted to a very large data set. Giant companies like Google and Facebook have huge proprietary data sets that few others can match. The presenters tend to be very confident and assert major advances over past methods and often to match or exceed human performance. It is often impossible to evaluate these claims without access to both the huge data sets and vast computing power. People who try to duplicate the reported dramatic results with more modest resources often report failure.
The presentations often avoid the goodness-of-fit statistics, robustness, and overfitting issues that experts in mathematical modeling worry about with such complex models. A very complex model such as a polynomial with thousands of terms can always fit a data set but it will usually fail to extrapolate outside the data set correctly. Polynomials, for example, always blow up to plus or minus infinity as the largest power term dominates.
In fact one Google presenter mentioned a “training-server skew” problem where the field data would frequently fail to match the training data used for the model. If I understood his comments, this seemed to occur almost every time supposedly for different reasons for each model. This sounded a lot like the frequent failure of complex models to extrapolate to new data correctly.
Ravi Kumar’s keynote presentation appeared to be a maximum likelihood estimation (MLE) of a complex model of repeat consumption by users: how often, for example, a user will replay the same song or YouTube video. MLE is not a robust estimation method and it is vulnerable to outliers in the data, almost a given in real data, yet there seemed to be no discussion of this issue in the presentation.
Often when researchers and practitioners from other fields that make heavy use of mathematical modeling such as statistics or physics bring up these issues, the machine learning/deep learning folks either circle the wagons and deny the issues or assert dismissively that they have the issues under control. Move on, nothing to see here.
Sandeep TataHang TzeIan Goodfellow on Deep Learning Research at GoogleJasmine Hsu on Robotics and Computer VisionJames KunzAndrew Zaldivar on SPAM Fighting with Machine Learning
Andrew Zaldivar introduced the Q&A panel for which he acted as moderator. Instead of having audience members take the microphone and ask their questions uncensored as many events do, he read out questions supposedly submitted by e-mail or social media.
Andrew Zaldivar Introduces the PanelQ and A Panel
The Q&A panel was followed by a reception from 8-9 PM to “meet the speakers.” It was difficult to see how this would work with about thirty (30) audience members for each presenter. I did not stay for the reception.
Conclusion
I found the presentations interesting but they did not go into most of the deeper technical questions such as goodness-of-fit, robustness, and overfitting that I would have liked to hear. I feel Google should have been clearer about the purpose of the event up front.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Police in Sunnyvale are keeping an eye out for a highly skilled and frustratingly elusive prankster who has been tampering with city traffic lights for more than three months, authorities said Tuesday.
The article gives more details on a series of traffic light tampering incidents in Sunnyvale in the spring of 2005.
Traffic lights went out on Mathilda in Sunnyvale today. See this tweet:
Note to “tricksters.” It is quite easy to kill someone by tampering with traffic lights!
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
There are some known cases of hacking/tampering with traffic lights.
According to the Los Angeles Times, in 2009, two Los Angeles traffic engineers pleaded guilty to hacking into the city’s signal system and slowing traffic at key intersections as part of a labor protest in 2006.
According to the San Francisco Chronicle, in June 2005, police in Sunnyvale, California (where my accident occurred) requested assistance from the public to find a suspected sophisticated “trickster” who had been tampering with traffic lights for several months.
END UPDATE: August 24, 2017
It is possible to hack traffic lights and there has been some published research into how to do it for some traffic light systems. Here are some links to articles and videos on the subject, mostly from 2014:
Talk by Cesar Cerrudo at DEFCON 22 on Hacking Traffic Lights
Someone with sufficient physical access to the traffic lights could always modify the hardware even if a computer-style “hack” was impossible.
I was driving a 1995 Nissan 200SX SE-R with minimal built-in electronics by modern car standards. It would be difficult to hack my car without physical access and it was either with me, in a brightly lit parking lot at my office, or in a secured parking garage at my apartment building.
Just to be clear I am not saying my accident was caused by hacking of the traffic lights, only that it is possible. As noted in my previous post, there are other possible explanations: an accidental failure of the traffic lights or a remarkable mental lapse on my part. None of the three explanations seems likely to me.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I had a serious accident on July 19, 2017 at about 6:30 AM in the morning making a left turn from the off ramp of Central Expressway East onto North Wolfe Road in Sunnyvale, California. Fortunately no one was seriously injured but I could easily have been killed and my car was totaled. I have some whiplash and may have had a very mild concussion.
The accident is something of a mystery. I distinctly remember stopping at the red light at the off ramp from Central Expressway and Wolfe Road. Then the light turned green and I made a left turn across the three lanes of South Wolfe Road. I make this turn almost every morning. I was awake, alert. I was not texting or doing anything reckless. I am generally a cautious driver; people have complained about it.
I had a glancing collision with an SUV coming down North Wolfe that should have had a red light but seemingly did not. The lights from both directions are extremely obvious at this intersection. I was extremely surprised both by the SUV and to see the light that should have stopped the SUV was green when I pulled over. I don’t think the SUV ran a red light although it is hard to be absolutely certain.
Three Unlikely Explanations
I seem to be left with three unlikely explanations. Despite my distinct memory and natural caution, I somehow made a left turn against multiple bright red lights directly in front of me and in my field of view.
Accident Left Turn View (Aug. 18, 2017)
(OR) The lights changed improperly giving both the other driver and myself green lights at the same time due to an electrical or electronic failure.
Lights on Wolfe Should Have Stopped Other Driver
(OR) The lights changed improperly giving both the other driver and myself green lights at the same time because someone tampered with the lights somehow, presumably either a dangerous prank or attempted homicide.
None of these possibilities seems particularly probable, but it seems that the explanation for the accident must be one of them.
Mental glitches of this type may happen but must be very rare. I was wide awake, alert, have made the turn many times and am familiar with the intersection. I am a cautious driver. The red lights should have been easily and clearly visible. I was in good health with no noticeable cognitive issues in the last several years. I remember seeing the red lights and the light changing green and very distinctly no red lights as I made the left turn.
There is a lot of construction at and near the intersection of Wolfe Road and Central Expressway in Sunnyvale that seems associated with an office building under construction in the block bordered by Wolfe, Central, Arques, and Commercial Street. The new office building faces Wolfe and Arques.
Building Construction at Corner of Arques and Wolfe (Aug. 18, 2017)
There is a lot of work going on right at the intersection of Central Expressway, technically the on/off ramps, and Wolfe Road.
Workmen Doing Something at Central Expressway Off Ramp and Wolfe (Aug. 18, 2017)
There were a lot of signs for construction in and around the intersection between Wolfe and the Central Expressway on/off ramps when the accident occurred although I did not see any workmen (it was about 6:30 AM and there do not seem to have been any witnesses).
The question arises whether the construction could have caused a glitch in the lights. To be sure, the lights could have some very rare, bizarre failure mode not due to the construction as well but surely this is less likely than a problem related to the construction.
Then, finally, there is the possibility of deliberate tampering with the traffic lights. This could just be some random, extremely dangerous “prank” or an attempt to kill, harm, or frighten either the other driver or myself (I did not and do not know the other driver). It is a bit concerning coming twelve days after my personal storage locker was broken into (July 7, 2017).
It is difficult to know what to make of deliberate tampering with the traffic lights. Many years ago I worked briefly for a company that shall remain nameless where I developed very serious concerns about the company and the people connected to it after I took the job. I didn’t hang around. They would be my leading suspects if there was tampering but it has been a long time. They would be risking the spotlight of unwanted public attention if they tried to kill me.
I am left with a mystery. None of the three explanations — a serious mental glitch on my part, an improbable electronic failure of the traffic lights, or deliberate tampering with the traffic lights by a person or persons unknown — seems likely, but presumably one of them happened. Previous accidents that I have had have been minor and it was always clear what had happened. 🙁
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
One of the most common arguments for learning math (or computer programming or chess or <insert your favorite subject here>) is that math teaches you to think. This argument has a long history of failing to convince skeptical students and adults especially where more advanced mathematics such as algebra and calculus is concerned.
The “math teaches you to think” argument has several problems. Almost any intellectual activity including learning many sports teaches you to think. Reading Shakespeare teaches you to think. Playing Dungeons and Dragons teaches you to think. What is so special about math?
Math teaches ways of thinking about quantitative problems that can be very powerful. As I have argued in a previous post Why Should You Learn Mathematics? mathematics is genuinely needed to make informed decisions about pharmaceuticals and medical treatments, finance and real estate, important public policy issues such as global warming, and other specialized but important areas. The need for mathematics skills and knowledge beyond the basic arithmetic level is growing rapidly due to the proliferation of, use, and misuse of statistics and mathematical modeling in recent years.
Book Smarts Versus Street Smarts
However, most math courses and even statistics courses such as AP Statistics teach ways of thinking that do not work well or even work at all for many “real world” problems, social interactions, and human society.
This is not a new problem. One of Aesop’s Fables (circa 620 — 524 BC) is The Astronomer which tells the tale of an astronomer who falls into a well while looking up at the stars. The ancient mathematics of the Greeks, Sumerians, and others had its roots in ancient astronomy and astrology.
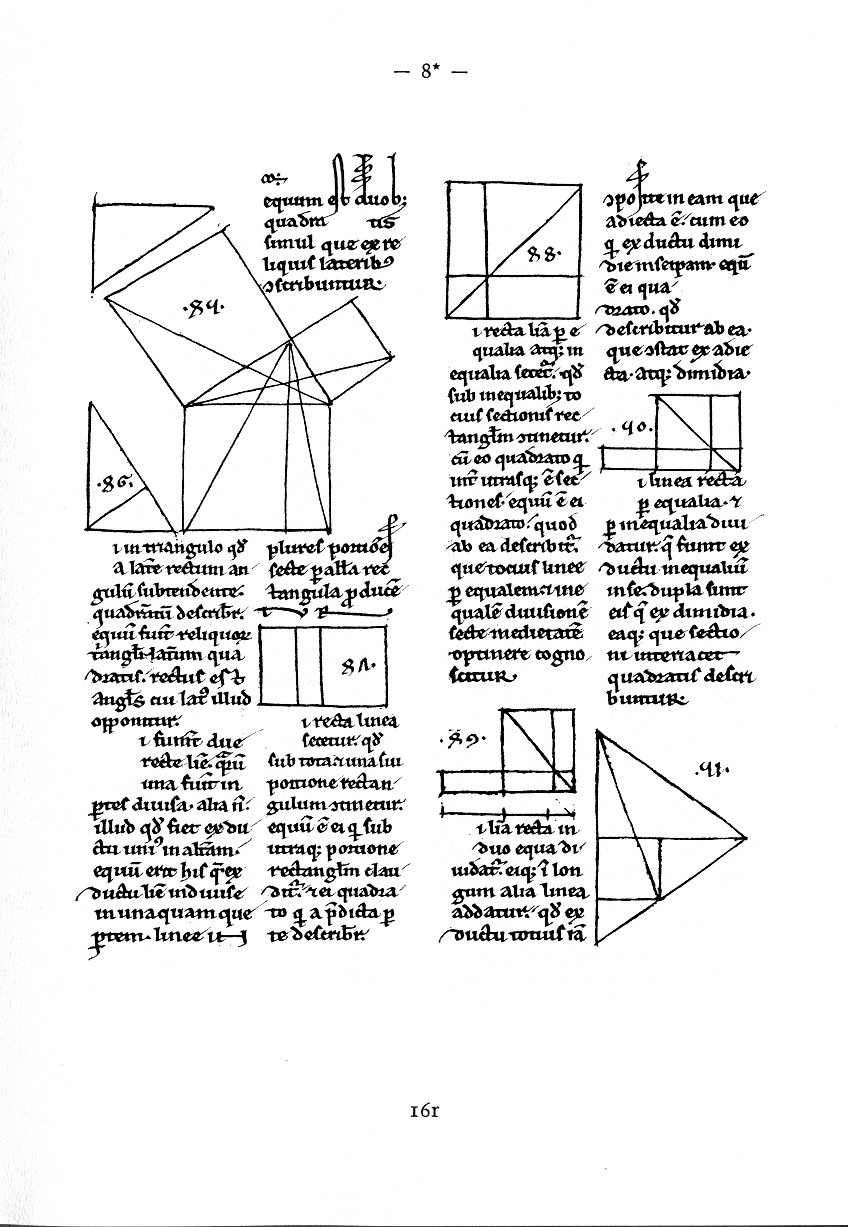
Proof of the Pythagorean Theorem from 1200 A.D.
Why does mathematical thinking often fail in the “real world?” Most mathematics education other than statistics teaches that there is one right answer which can be found by precise logical and mathematical steps. Two plus two is four and that is it. The Pythagorean Theorem is proven step by step by rigorous logic starting with Euclid’s Postulates and Definitions. There is no ambiguity and no uncertainty and no emotion.
If a student tries to apply this type of rigorous, exact thinking to social interactions, human society, even walking across a field where underbrush has obscured a well as in Aesop’s Fable of the Astronomer, the student will often fail. Indeed, the results can be disastrous as in the fable.
In fact, at the K-12 level and even college, liberal arts such as English literature, history, debate, the law do a much better job than math in teaching students the reality that in many situations there are many possible interpretations. Liberal arts deals with people and even the most advanced mathematics has failed to duplicate the human mind.
In dealing with other people, we can’t read their minds. We have to guess (estimate) what they are thinking to predict what they may do in the future. We are often wrong. Mathematical models of human behavior generally don’t predict human behavior reliably. Your intuition from personal experience, learning history, and other generally non-quantitative sources is often better.
The problem is not restricted to human beings and human society. When navigating in a room or open field, some objects will be obscured by other objects or we won’t happen to be looking at them. Whether we realize it or not, we are making estimates — educated guesses — about physical reality. A bush might be just a bush or it might hide a dangerous well that one can fall into.
The Limits of Standard Statistics Courses
It is true that statistics courses such as AP Statistics and/or more advanced college and post-graduate statistics addresses these problems to some degree: unlike basic arithmetic, algebra, and calculus. The famous Bayes Theorem gives a mathematical framework for estimating the probability that a hypothesis is true given the data/observations/evidence. It allows us to make quantitative comparisons between competing hypotheses: just a bush versus a bush hiding a dangerous well.
However, many students at the K-12 level and even college get no exposure to statistics or very little. How many students understand Bayes Theorem? More importantly, there are significant unknowns in the interpretation and proper application of Bayes Theorem to the real world. How many students or even practicing statisticians properly understand the complex debates over Bayes Theorem, Bayesian versus frequentist versus several other kinds of statistics?
All or nearly all statistics that most students learn is based explicitly or implicitly on the assumption of independent identically distributed random variables. These are cases like flipping a “fair” coin where the probability of the outcome is the same every time and is not influenced by the previous outcomes. Every time someone flips a “fair” coin there is the same fifty percent chance of heads and the same fifty percent chance of tails. The coin flips are independent. It does not matter whether the previous flip was heads or tails. The coin flips are identically distributed. The probability of heads or tails is always the same.
The assumption of independent identically distributed is accurate or very nearly accurate for flipping coins, most “fair” games of chance used as examples in statistics courses, radioactive decay, and some other natural phenomena. It is generally not true for human beings and human society. Human beings learn from experience and change over time. Various physical things in the real world also change over time.
Although statistical thinking is closer to the “real world” than many other commonly taught forms of mathematics, it still in practice deviates substantially from everyday experience.
Teaching Students When to Think Mathematically
Claims that math (or computer programming or chess or <insert your favorite subject here>) teaches thinking should be qualified with what kind of thinking is taught, what are its strengths and weaknesses, and what problems is it good for solving.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Credits
The image of a Latin proof of the Pythagorean Theorem with diagrams is from Wikimedia Commons and is in the public domain. The original source is a manuscript from 1200 A.D.
We received a very official looking letter today from Corporate Compliance Services, seeming to be from a federal government agency without actually stating this. The document asked us to send a check or money order for $84 to Corporate Compliance Services for US federal government required posters for our workplace.
Letter from Corporate Compliance Services
This is a scam. The United States Department of Labor does indeed require that employers display posters informing employees of their rights under various laws such as the Fair Labor Standards Act (FLSA), but these are available for free from the US Department of Labor.
FLSA Minimum Wage Poster
The United States Department of Labor web site has a simple, easy-to-use eLaws Advisor to help you determine which posters are required for your business and to then locate and download the required posters for free.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).