John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Subscribe to our free Weekly Newsletter for articles and videos on practical mathematics, Internet Censorship, ways to fight back against censorship, and other topics by sending an email to: subscribe [at] mathematical-software.com
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Introduction to using Math Recognition Artificial Intelligence (AI) to boost sales at no extra cost by estimating the combination of ad expenditures that maximizes sales for the current ad budget. Demonstration using sales and advertising expenditure data from McDonalds (restaurants) annual reports. About 9 minutes.
Subscribe to our free Weekly Newsletter for articles and videos on practical mathematics, Internet Censorship, ways to fight back against censorship, and other topics by sending an email to: subscribe [at] mathematical-software.com
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Knowing cognitive biases can worsen them. Paradoxically, detailed knowledge of cognitive biases such as “confirmation bias” and “cognitive dissonance” provides a powerful set of tools to reinforce these very biases and dismiss data, evidence, and even direct personal experiences that contradict our preconceived ideas and prejudices.
In practice, one thinks:
I am one of the special intelligent, educated elite who are well aware of the cognitive biases. Knowing the biases, I am able to compensate for them, for example through ‘steelmanning‘ my opponent’s arguments. In contrast, the data or evidence from any third party contradicting my evidence-based beliefs is clearly the product of cognitive biases X,Y, and Z leading to cherry picking of evidence, faulty statistical methodologies, or other mistakes.
That personal experience that contradicts my evidence-based belief is a special case, a fluke, a coincidence, the product of some perceptual error such as the well known phenomenon cited by skeptics of misperceiving the rising Moon, Venus, Jupiter, lighthouses, and other conventional objects as a silvery flying saucer, or some other perceptual or cognitive flaw mined from the literature or made up as needed.
This is due in part to the so-called GI Joe Fallacy:
Knowing about one’s biases does not always allow one to overcome those biases — a phenomenon referred to as the G. I. Joe fallacy.
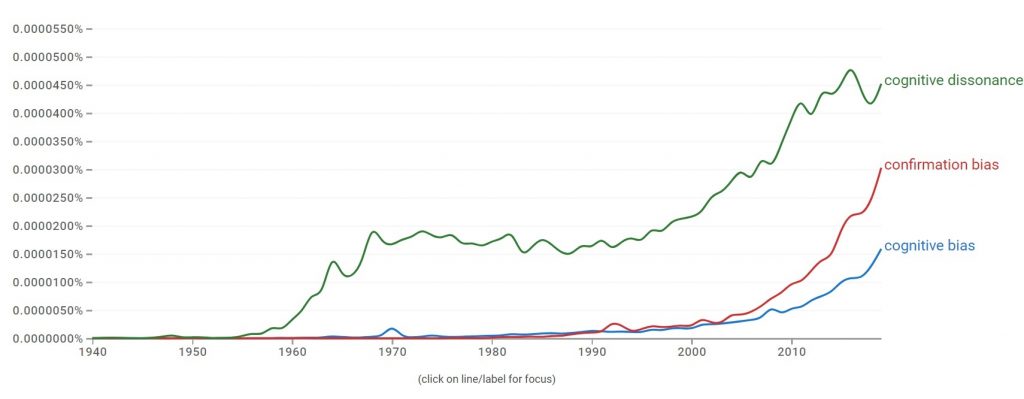
Cognitive Bias Words and Phrases from 1940 to 2019
The use of phrases such as “cognitive bias,” “confirmation bias”, and “cognitive dissonance” has grown dramatically in the last twenty years as shown by Google’s NGRAM viewer above. Indeed if you follow many political or scientific controversies in recent decades, it is likely you will have heard these phrases used to dismiss the data, evidence, opinions, and even direct personal experiences of the “other side” in these debates.
By most accounts the phrase “cognitive dissonance” entered general use from the publication of the popular science book When Prophecy Fails: A Social and Psychological Study of a Modern Group That Predicted the Destruction of the Worldby Leon Festinger, Henry Riecken, and Stanley Schacter in 1956 and A Theory of Cognitive Dissonance by Leon Festinger in 1957. Awareness of cognitive dissonance and other cognitive biases has soared in the last few decades. The publication of Daniel Kahneman’s popular science book Thinking, Fast and Slow in 2011 is often credited with contributing to recent greater awareness of cognitive biases.
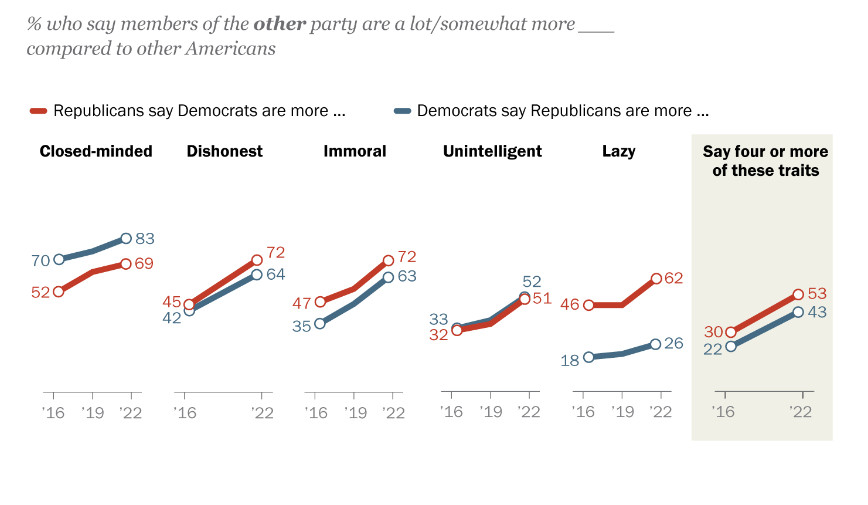
Yet, in fact, this wider awareness of cognitive bias does not appear to have improved the quality of logical argument or debate. Quite the opposite if anything, with censorship and thought-stopping labels such as “conspiracy theory,” “conspiracist,” “conspiracy theorist,” “conspiracy thinking”, even “conspiracy” used as a short hand for “conspiracy theory” in the pejorative, non-literal sense that has become ubiquitous, “denialism” and “denier” in the Holocaust denial sense, “fake news,” “misinformation,” “disinformation,” and “malinformation” proliferating.
More and more people may simultaneously believe that their knowledge of cognitive biases makes them immune to error while dismissing the views of others as hopelessly wrong due to their unrecognized cognitive biases.
Is there anything we can do about this growing problem?
Paradoxically, simply knowing that detailed knowledge of cognitive biases can actually aggravate these biases is not enough. Knowing is not even half the battle.
It is unclear what will actually work. Modern technologies and system such as the Internet as a whole, smartphones, and Twitter can bombard us with huge quantities of often emotional, propagandistic content. Scaling back the quantity of this content may be helpful.
Going through the “news” and other content one consumes, systematically striking out the many popular thought-stopping words and phrases such as “conspiracy theory” and ironically especially invoking “cognitive bias,” “cognitive dissonance,” “confirmation bias,” and related phrases, leaving hopefully a small set of alleged “facts” — not opinion or analysis, may help us drill down to the substance of the content.
Common Thought-Stopping Words and Phrases Today
pseudoscience
climate denial
XXX denial
climate denialism
XXX denialism
anti-vaccine
anti-science
anti-XXX
conspiracy theory
conspiracy thinking
conspiracy theorist
conspiracist
conspiracy
fake news
misinformation
disinformation
malinformation
election interference
far right (more common)
far left (less common)
Russian
Putin
woke
racist
racism
white supremacy
white supremacism
xenophobia
homophobia
Russophobia
XXXphobia
pedo
pedophilia
PARADOXICALLY:
cognitive bias
confirmation bias
cognitive dissonance
cherry picking data/evidence/etc.
The reader can probably list several more from their own experience. It is easier to identify thought-stopping words and phrases that you disagree with.
Edit out thought stopping words and phrases
Edit out other emotional words and phrases
Identify remaining factual or logical claims
Check the facts yourself (don’t rely on so-called fact checkers)
Locate original source or citation
Verify what the original source or citation says in the body of the article — don’t rely on abstracts, summaries, titles, headlines.
Wikipedia relies on secondary sources. Track down the primary (original) sources. Wikipedia is not reliable on “controversial” subjects.
Check sources of funding, possible conflicts of interest or biases of any authors or publishers.
Verify the claimed “facts” through personal experience if possible.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Short video on using AI to estimate how to boost the Cracker Barrel restaurant and gift shop chain’s sales by improving advertising expenditures.
Short Article: http://wordpress.jmcgowan.com/wp/article-can-ai-boost-cracker-barrels-stagnant-sales/
Short Link: bit.ly/3ojdV9t
About Us:
Main Web Site: https://mathematical-software.com/ Censored Search: https://censored-search.com/ A search engine for censored Internet content. Find the answers to your problems censored by advertisers and other powerful interests!
Subscribe to our free Weekly Newsletter for articles and videos on practical mathematics, Internet Censorship, ways to fight back against censorship, and other topics by sending an email to: subscribe [at] mathematical-software.com
Avoid Internet Censorship by Subscribing to Our RSS News Feed: http://wordpress.jmcgowan.com/wp/feed/
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
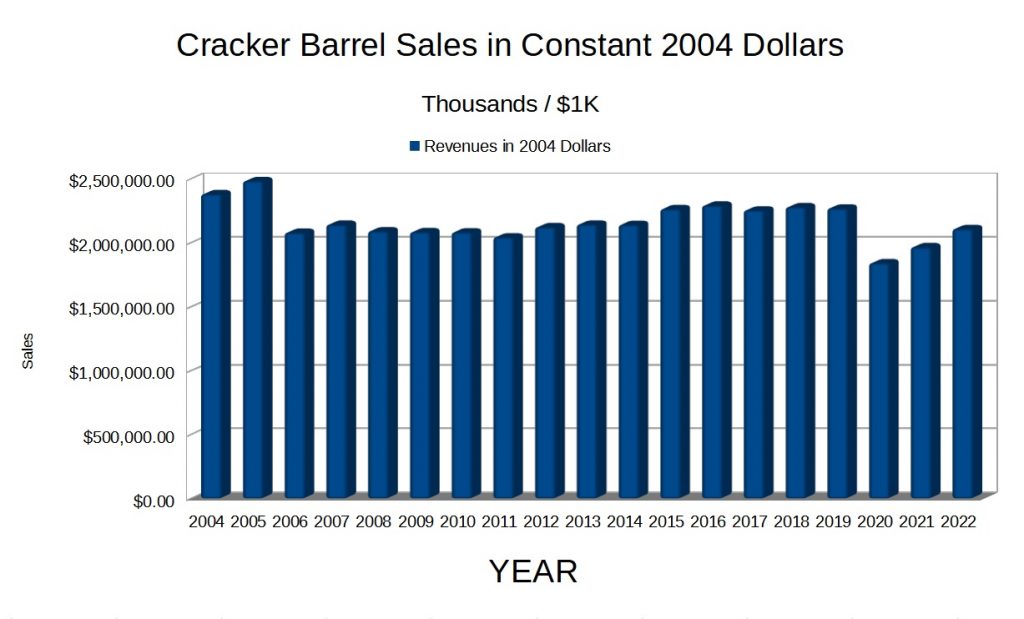
Cracker Barrel (NASDAQ: CBRL), the restaurant and gift shop chain, is one of many successful businesses whose sales in constant dollars have stagnated after a period of rapid, even exponential growth. Historically, Cracker Barrel relied almost exclusively on roadside billboards and word of mouth for its dramatic growth from a small business in Lebanon, TN in 1969 to sales of about $2.4 billion in 2004. Adjusted by the US Consumer Price Index (CPI), Cracker Barrel’s 2022 sales were only $2.1 billion in 2004 dollars.
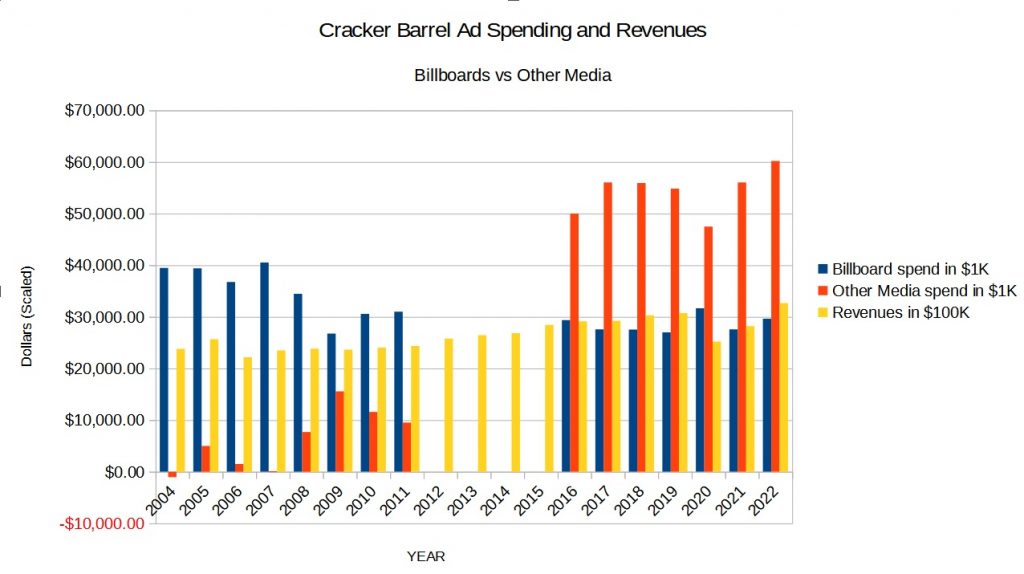
This decline in real sales has occurred despite or even because of a sustained attempt to diversify away from the historically successful billboard advertising into other media.
Is it possible to use modern Artificial Intelligence (AI) technologies such as ChatGPT or other less well known methods to boost Cracker Barrel or other businesses now stagnant sales?
This article examines Cracker Barrel’s publicly reported expenditures on billboards and other media using Artificial Intelligence based Math Recognition to evaluate the effectiveness of Cracker Barrel’s strategies since 2004, generally supporting the company’s focus on other media, now about two thirds of ad expenditures, although also indicating the effectiveness of current advertising methods whether billboards or “other media” is small compared to the spectacular results in the 1980’s and 1990s.
Indeed the public financial data suggests Cracker Barrel may be fighting a negative effect from growing US Gross Domestic Product (GDP), needing to advertise more and more simply to sustain, never mind boost, company revenues.
Cracker Barrel’s publicly available information on the company’s marketing and advertising expenditures is very limited, falling into two aggregate categories: billboards and “other media” which includes radio, TV, Internet, and other non-billboard methods. The data is annual for the entire United States. There is no geographical breakdown, association with specific marketing or advertising campaigns in time, location, or other important factors.
It is almost certain our Math Recognition would construct more complex models from such details and likely make more reliable predictions from more detailed data which Cracker Barrel undoubtedly has in the internal accounting systems than the relatively simple model constructed from the public data.
What is Math Recognition?
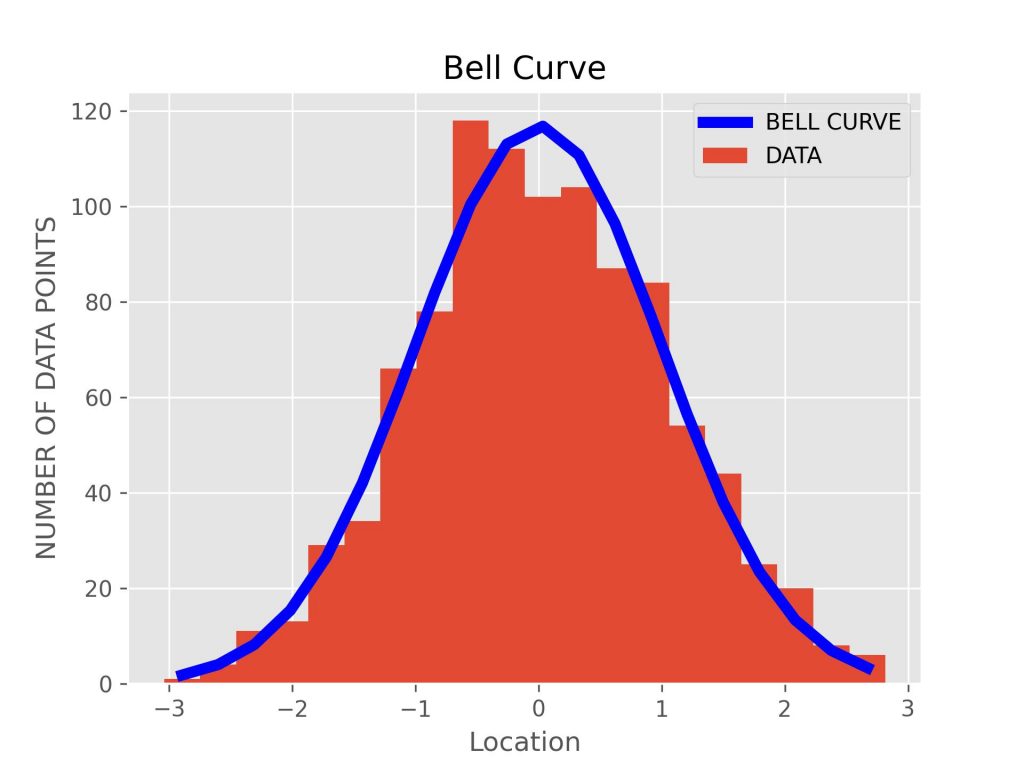
Math recognition is a key part of scientific and engineering practice. It is identifying and recognizing the mathematical formulas and objects describing the data. The Bell Curve often encountered in grading in high school or college is a well known and relatively easy to identify mathematical formula. In addition to grades it describes the frequency of heights in adults of the same sex and many other common measured quantities.
However, scientists, engineers, and financial analysts often struggle to find a viable mathematical formula or formulas for real world data. Without such a formula it is impossible to make predictions or optimize the output of systems.
Our Math Recognizer has a large and growing database of known mathematics including obscure and difficult to identify mathematical objects: special functions, differential equations, etc.. The Math Recognizer uses AI methods to recognize these mathematical formulas in data.
What is the mathematical relationship if any between a company’s advertising expenditures on competing methods and actual sales?
John Wanamaker (1838-1922)
Half the money I spend on advertising is wasted; the trouble is, I don’t know which half.
John Wanamaker (1838-1922)
This is an OLD problem in business.
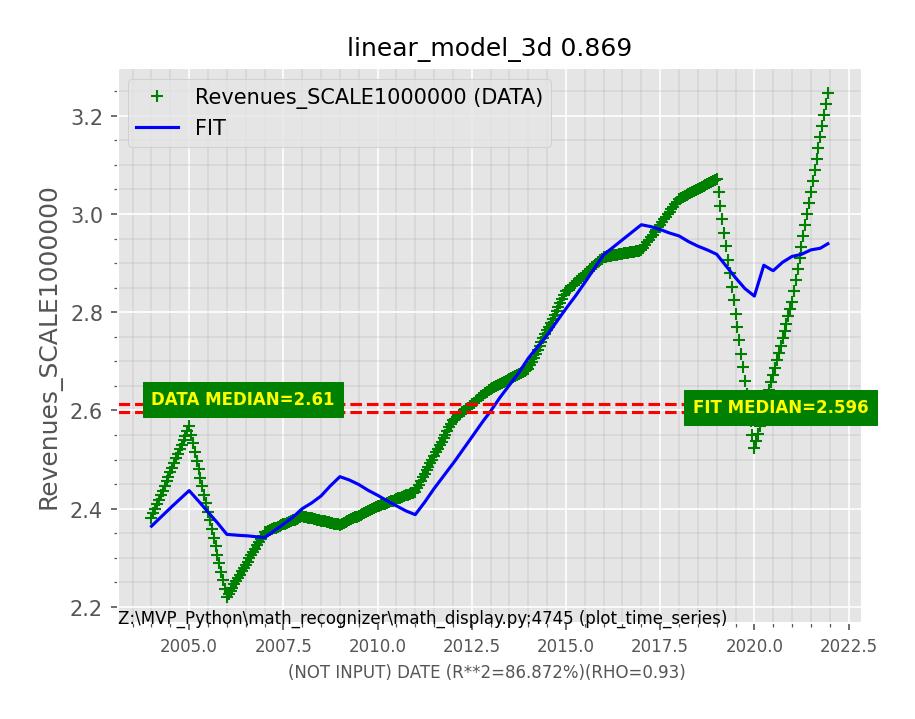
The Math Recognizer is able to identify a relatively simple mathematical model for the Cracker Barrel data combined with the US Gross Domestic Product (GDP) from the St Louis Federal reserve. The GDP is used as a proxy for the overall state of the economy, something the company cannot control. For example, in the revenues reported by Cracker Barrel we can easily see a sharp drop attributable to the 2020 COVID pandemic lockdowns, something clearly beyond the control of the company.
The model roughly “explains” about 86 percent of the variation in the data. This is a roughly correct interpretation of the R**2 or coefficient of determination Goodness of Fit (GoF) metric used in the analysis.
Once we have identified a model with good agreement with the data, we can optimize the output, meaning maximize the sales in this case, given a projected budget. This is actually somewhat disappointing in that the program recommends to spend the entire budget on the “other media,” non-billboard, category with a slight dip in sales due to the negative effect of GDP according to the model.
Budget in Units of $1K ($1,000), about $89.5 Million in 2022
Let’s consider a larger future budget of $150 million, an abrupt increase of about $60 million over 2022. In this case we see the expected sales in current dollars to jump from about $3.2 billion in 2022 to almost $4 billion, an increase of about $800 million per year.
Budget in Units of $1K ($1,000), about $89.5 Million in 2022, new budget of $150 MillionBudget in Units of $1K ($1,000), about $89.5 Million in 2022, new budget of $150 Million
For this increase to pay for itself, the additional $800 million in sales must cost no more than $740 million dollars — a profit margin of about 7.5% (seven point five percent). That is a good profit margin for a restaurant. Restaurants often average only 3-5 percent profit margins.
Conclusion
A simple model based on broad financial numbers like these should not be taken very seriously although it may give some insights into a company. Indeed this simple analysis appears to support Cracker Barrel’s existing policies of diversifying advertising out of billboards, despite the disappointing results with inflation adjusted sales stagnant.
An in depth analysis of finely grained internal accounting data may be able to yield more detailed, reliable, and actionable results including a predictive model.
(C) 2023 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
How to Boost Your Sales with AI short video using sales and advertising data from the annual reports of the McDonalds restaurant company as an example.
(C) 2023 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Sabine Hossenfelder, a disillusioned (former?) theoretical particle physicist and science popularizer, recently published a video “What’s going wrong in particle physics?” on her YouTube channel criticizing fifty years of common practice in particle physics. I’ve previously reviewed her book Lost in Math: How Beauty Leads Physics Astray published in 2018 and an editorial “The Uncertain Future of Particle Physics” in The New York Times (January 23, 2019) questioning the wisdom of funding CERN’s recent proposal to build a new particle accelerator, the Future Circular Collider (FCC), estimated to cost over $10 billion. See the links below for the Lost in Math book review and commentary on the editorial. Comments on the YouTube video follow these links.
Dr. Hossenfelder’s point in the video is fairly simple. She argues that since the formulation of the so-called “standard model” (formerly known as Glashow-Weinberg-Salam or Weinberg-Salam after theoretical physicists Sheldon Glashow, Stephen Weinberg, and Abdus Salam) in the 1960’s and 1970’s, particle physicists have confirmed the standard model, discovering the predicted W and Z bosons in the 1980s, the top quark at Fermilab, and finally the Higgs particle at CERN in 2012.
However, all attempts to find new physics and new particles beyond the standard model since the 1970’s have failed. Particle physicists continue to construct more complex theories that include the standard model such as the Grand Unified Theories (GUTs) of the 1970s that predicted the decay of the proton — never detected. These theories have predicted a long succession of hypothetical particles such as axions, supersymmetric partners, WIMPs (weakly interacting massive particles), other candidates for hypothetical dark matter in cosmology, and many, many more.
These complex beyond the standard model theories keep moving the energy level — usually expressed in billions or trillions of electron volts higher and higher, justifying the research, development, and construction of ever larger and more expensive particle accelerators such as the Tevatron at Fermilab in the United States, the Large Hadron Collider (LHC) at CERN in Switzerland, and the proposed Future Circular Collider (FCC) at CERN.
This lack of success was becoming apparent in the 1980’s when I was studying particle physics at Caltech — I worked briefly on the IMB proton decay experiment which surprise, surprise failed to find the proton decay predicted by the GUTs — and the University of Illinois at Urbana-Champaign on the Stanford Linear Accelerator Center (SLAC)’s disastrous Stanford Linear Collider (SLC) which ran many years over schedule, many millions of dollars over budget, and surprise, surprise discovered nothing beyond the standard model much as Dr. Hossenfelder complains in her recent YouTube video.
Cynical experimental particle physicists would make snide comments about how theory papers kept moving the energy scale for supersymmetry, technicolor, and other popular beyond the standard model theories just above the energy scale of the latest experiments.
Not surprisingly those who clearly perceived this pattern tended to leave the field, most often moving to some form of software development or occasionally other scientific fields. A few found jobs on Wall Street developing models and software for options and other derivative securities.
The second physics bubble burst in about 1993, following the end of the Cold War with huge numbers of freshly minted Ph.D.’s unable to find physics jobs and mostly turning into software developers. The first physics bubble expanded after the launch of Sputnik in 1957 and bust in about 1967. The Reagan administration’s military build-up in the 1980’s fueled another bubble — often unbeknownst to the physics graduate students of the 1980’s.
Dr. Hossenfelder’s recent video, like Lost in Math, focuses on scientific theory and rarely touches on the economic forces that complement and probably drive — consciously or not — both theory and practice independent of actual scientific results.
Scientific research has a high failure rate, sometimes claimed to be eighty to ninety percent when scientists are excusing obvious failures and/or huge cost and schedule overruns — which are common. Even the few successes are often theoretical — better understanding of some physical phenomenon that does not translate into practical results such as new power sources or nuclear weapons for example. But huge experimental mega-projects such as the Large Hadron Collider (LHC) or the Future Circular Collider (FCC), justified by the endless unsuccessful theorizing Dr. Hossenfelder criticizes, are money here and now, jobs for otherwise potentially unemployed physicists, huge construction projects, contracts for research and development of magnets for the accelerators etc.
Big Science creates huge interest groups that perpetuate themselves independent of actual public utility. President Eisenhower identified the problem in his famous Farewell Address in 1961 — best known for popularizing the phrase “military industrial complex.”
Akin to, and largely responsible for the sweeping changes in our industrial-military posture, has been the technological revolution during recent decades.
In this revolution, research has become central; it also becomes more formalized, complex, and costly. A steadily increasing share is conducted for, by, or at the direction of, the Federal government.
Today, the solitary inventor, tinkering in his shop, has been over shadowed by task forces of scientists in laboratories and testing fields. In the same fashion, the free university, historically the fountainhead of free ideas and scientific discovery, has experienced a revolution in the conduct of research. Partly because of the huge costs involved, a government contract becomes virtually a substitute for intellectual curiosity. For every old blackboard there are now hundreds of new electronic computers.
The prospect of domination of the nation’s scholars by Federal employment, project allocations, and the power of money is ever present and is gravely to be regarded.
Yet, in holding scientific research and discovery in respect, as we should, we must also be alert to the equal and opposite danger that public policy could itself become the captive of a scientific-technological elite.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
"""
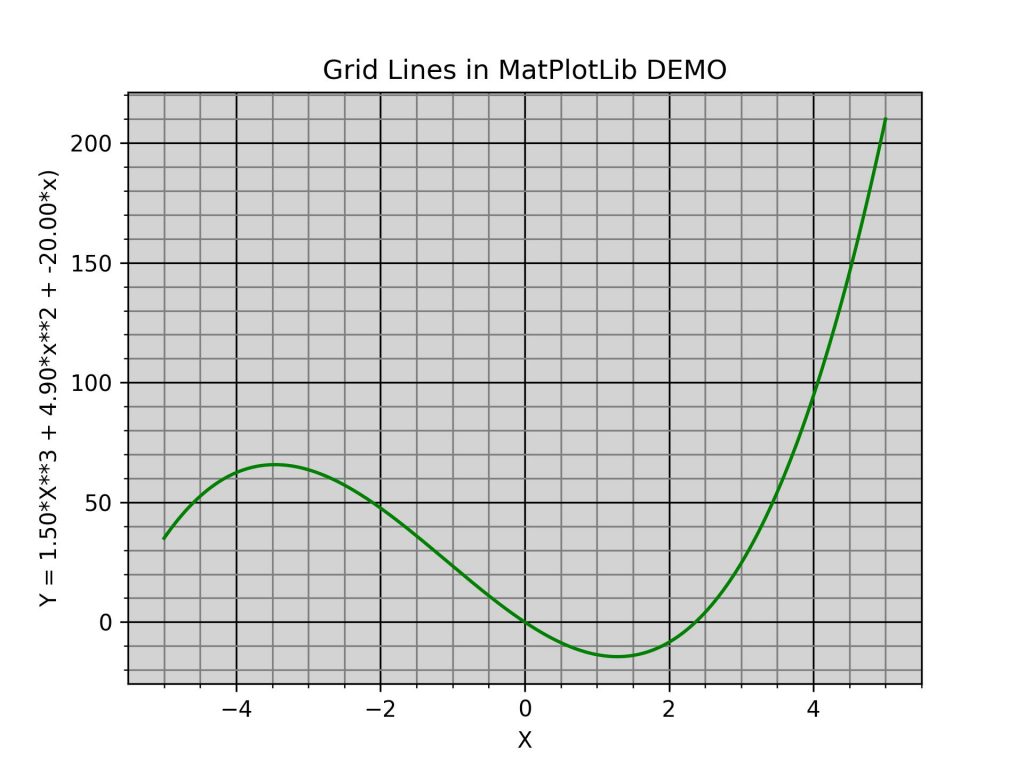
Short demo How to Display Grid Lines in MatPlotLib
(C) 2022 by Mathematical Software Inc.
http://www.mathematical-software.com/
"""
# Python Standard Library
import os
import sys
import time
# NumPy and MatPlotLib add on Python packages/modules
import numpy as np
import matplotlib.pyplot as plt
XRANGE = 5.0
CUBE_CONST = 1.5
ACCELERATION = 9.8
VELOCITY = -20.0
x = np.linspace(-XRANGE, XRANGE, 200)
y = CUBE_CONST*x**3 + 0.5*ACCELERATION*x**2 + VELOCITY*x
# simple MatPlotLib plot
f1 = plt.figure()
ax = plt.axes() # get plot axes
ax.set_facecolor('lightgray') # background color of plot
plt.plot(x, y, 'g-')
plt.title('Grid Lines in MatPlotLib DEMO')
plt.xlabel('X')
plt.ylabel(f'Y = {CUBE_CONST:.2f}*X3 + {0.5*ACCELERATION:.2f}*x**2' f' + {VELOCITY:.2f}*x)')
plt.grid(which='major', color='black')
plt.grid(which='minor', color='gray')
plt.minorticks_on() # need this to see the minor grid lines
plt.show(block=True)
f1.savefig('how_to_display_grid_lines_in_matplotlib.jpg',
dpi=300)
(C) 2022 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).