This video is a brief introduction to STEM (Science, Technology, Engineering, and Mathematics) Shortage claims: what they are and are they true?
For more details, see these articles:
(C) 2017 by John F. McGowan, Ph.D.

Solving practical problems with mathematics
This video is a brief introduction to STEM (Science, Technology, Engineering, and Mathematics) Shortage claims: what they are and are they true?
For more details, see these articles:
(C) 2017 by John F. McGowan, Ph.D.
This is an edited video of my presentation on “Automating Complex Data Analysis” to the Bay Area SAS Users Group (BASAS) on August 31, 2017 at Building 42, Genentech in South San Francisco, CA.
The demonstration of the Analyst in a Box prototype starts at 14:10 (14 minutes, 10 seconds). The demo is a video screen capture with high quality audio.
Unfortunately there was some background noise from a party in the adjacent room starting about 12:20 until 14:10 although my voice is understandable.
Updated slides for the presentation are available at: https://goo.gl/Gohw87
You can find out more about the Bay Area SAS Users Group at http://www.basas.com/
Abstract:
Complex data analysis attempts to solve problems with one or more inputs and one or more outputs related by complex mathematical rules, usually a sequence of two or more non-linear functions applied iteratively to the inputs and intermediate computed values. A prominent example is determining the causes and possible treatments for poorly understood diseases such as heart disease, cancer, and autism spectrum disorders where multiple genetic and environmental factors may contribute to the disease and the disease has multiple symptoms and metrics, e.g. blood pressure, heart rate, and heart rate variability.
Another example are macroeconomic models predicting employment levels, inflation, economic growth, foreign exchange rates and other key economic variables for investment decisions, both public and private, from inputs such as government spending, budget deficits, national debt, population growth, immigration, and many other factors.
A third example is speech recognition where a complex non-linear function somehow maps from a simple sequence of audio measurements — the microphone sound pressure levels — to a simple sequence of recognized words: “I’m sorry Dave. I can’t do that.”
State-of-the-art complex data analysis is labor intensive, time consuming, and error prone — requiring highly skilled analysts, often Ph.D.’s or other highly educated professionals, using tools with large libraries of built-in statistical and data analytical methods and tests: SAS, MATLAB, the R statistical programming language and similar tools. Results often take months or even years to produce, are often difficult to reproduce, difficult to present convincingly to non-specialists, difficult to audit for regulatory compliance and investor due diligence, and sometimes simply wrong, especially where the data involves human subjects or human society.
A widely cited report from the McKinsey management consulting firm suggests that the United States may face a shortage of 140,000 to 190,000 such human analysts by 2018: http://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation.
This talk discusses the current state-of-the-art in attempts to automate complex data analysis. It discusses widely used tools such as SAS and MATLAB and their current limitations. It discusses what the automation of complex data analysis may look like in the future, possible methods of automating complex data analysis, and problems and pitfalls of automating complex data analysis. The talk will include a demonstration of a prototype system for automating complex data analysis including automated generation of SAS analysis code.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).

Complex data analysis attempts to solve problems with one or more inputs and one or more outputs related by complex mathematical rules, usually a sequence of two or more non-linear functions applied iteratively to the inputs and intermediate computed values. A prominent example is determining the causes and possible treatments for poorly understood diseases such as heart disease, cancer, and autism spectrum disorders where multiple genetic and environmental factors may contribute to the disease and the disease has multiple symptoms and metrics, e.g. blood pressure, heart rate, and heart rate variability.
Another example are macroeconomic models predicting employment levels, inflation, economic growth, foreign exchange rates and other key economic variables for investment decisions, both public and private, from inputs such as government spending, budget deficits, national debt, population growth, immigration, and many other factors.
A third example is speech recognition where a complex non-linear function somehow maps from a simple sequence of audio measurements — the microphone sound pressure levels — to a simple sequence of recognized words: “I’m sorry Dave. I can’t do that.”
State-of-the-art complex data analysis is labor intensive, time consuming, and error prone — requiring highly skilled analysts, often Ph.D.’s or other highly educated professionals, using tools with large libraries of built-in statistical and data analytical methods and tests: SAS, MATLAB, the R statistical programming language and similar tools. Results often take months or even years to produce, are often difficult to reproduce, difficult to present convincingly to non-specialists, difficult to audit for regulatory compliance and investor due diligence, and sometimes simply wrong, especially where the data involves human subjects or human society.
A widely cited report from the McKinsey management consulting firm suggests that the United States may face a shortage of 140,000 to 190,000 such human analysts by 2018: http://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation.
This talk discusses the current state-of-the-art in attempts to automate complex data analysis. It discusses widely used tools such as SAS and MATLAB and their current limitations. It discusses what the automation of complex data analysis may look like in the future, possible methods of automating complex data analysis, and problems and pitfalls of automating complex data analysis. The talk will include a demonstration of a prototype system for automating complex data analysis including automated generation of SAS analysis code.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I attended a “Machine Learning at Google” event at the Google Quad 3 building off Ellis in Mountain View last night (August 23, 2017). This seemed to be mostly a recruiting event for some or all of Google’s high profile Machine Learning/Deep Learning groups, notably the team responsible for TensorFlow.

I had no trouble finding the registration table when I arrived and getting my badge. All the presentations seemed to run on time or nearly on time. There was free food, a cute bag with Google gewgaws, and plenty of seating (about 280 seats with attendance about 240 I thought).
The event invitation that I received was rather vague and it did not become clear this was a recruiting event until well into the event. It had the alluring title:
An Exclusive Invite | Machine Learning @ Google

Ooh, exclusive! Aren’t I special! Along with 240 other attendees as it turned out. 🙂
Andrew Zaldivar (see below) explicitly called it a recruiting event in the Q&A panel at the end. It would have been good to know this as I am not looking for a job at Google. That does not mean the event wasn’t interesting to me for other reasons, but Google and other companies should be up front about this.
Although I think the speakers were on a low platform, they weren’t up high enough to see that well, even though I was in the front. This was particularly true of Jasmine Hsu who was short. I managed to get one picture of her not fully or mostly obscured by someone’s head. Probably a higher platform for the presenters would have helped.
A good looking woman who seemed to be some sort of public relations or marketing person opened the event at 6:30 PM. She went through all the usual event housekeeping and played a slick Madison Avenue style video on the coming wonders of machine learning. Then she introduced the keynote speaker Ravi Kumar.

Ravi was followed by a series of “lightning talks” on machine learning and deep learning at Google by Sandeep Tata, Heng-Tze Cheng, Ian Goodfellow, James Kunz, Jasmine Hsu, and Andrew Zaldivar.
The presentations tended to blur together. The typical machine learning/deep learning presentation is an extremely complex model that has been fitted to a very large data set. Giant companies like Google and Facebook have huge proprietary data sets that few others can match. The presenters tend to be very confident and assert major advances over past methods and often to match or exceed human performance. It is often impossible to evaluate these claims without access to both the huge data sets and vast computing power. People who try to duplicate the reported dramatic results with more modest resources often report failure.
The presentations often avoid the goodness-of-fit statistics, robustness, and overfitting issues that experts in mathematical modeling worry about with such complex models. A very complex model such as a polynomial with thousands of terms can always fit a data set but it will usually fail to extrapolate outside the data set correctly. Polynomials, for example, always blow up to plus or minus infinity as the largest power term dominates.
In fact one Google presenter mentioned a “training-server skew” problem where the field data would frequently fail to match the training data used for the model. If I understood his comments, this seemed to occur almost every time supposedly for different reasons for each model. This sounded a lot like the frequent failure of complex models to extrapolate to new data correctly.
Ravi Kumar’s keynote presentation appeared to be a maximum likelihood estimation (MLE) of a complex model of repeat consumption by users: how often, for example, a user will replay the same song or YouTube video. MLE is not a robust estimation method and it is vulnerable to outliers in the data, almost a given in real data, yet there seemed to be no discussion of this issue in the presentation.
Often when researchers and practitioners from other fields that make heavy use of mathematical modeling such as statistics or physics bring up these issues, the machine learning/deep learning folks either circle the wagons and deny the issues or assert dismissively that they have the issues under control. Move on, nothing to see here.






Andrew Zaldivar introduced the Q&A panel for which he acted as moderator. Instead of having audience members take the microphone and ask their questions uncensored as many events do, he read out questions supposedly submitted by e-mail or social media.


The Q&A panel was followed by a reception from 8-9 PM to “meet the speakers.” It was difficult to see how this would work with about thirty (30) audience members for each presenter. I did not stay for the reception.
Conclusion
I found the presentations interesting but they did not go into most of the deeper technical questions such as goodness-of-fit, robustness, and overfitting that I would have liked to hear. I feel Google should have been clearer about the purpose of the event up front.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This is another brief followup to my earlier post “A Personal Note: Mysterious Accident” about my odd accident in Sunnyvale, CA about a month ago.
Remarkably, in June 2005, SFGate published an article “SUNNYVALE / Trickster is trifling with traffic / Police on lookout for culprit skilled in resetting signals” by Chuck Squatriglia, Chronicle Staff Writer (Published 4:00 am, Wednesday, June 22, 2005) reporting:
Police in Sunnyvale are keeping an eye out for a highly skilled and frustratingly elusive prankster who has been tampering with city traffic lights for more than three months, authorities said Tuesday.
The article gives more details on a series of traffic light tampering incidents in Sunnyvale in the spring of 2005.
Traffic lights went out on Mathilda in Sunnyvale today. See this tweet:
TRAFFIC ADVISORY: Lights @ Mathilda/Moffett Park are out. Please use caution & exercise patience. Traffic is heavy. https://t.co/15EXMliZtM pic.twitter.com/ZU7jKNmPyk
— Sunnyvale DPS (@SunnyvaleDPS) August 23, 2017
Note to “tricksters.” It is quite easy to kill someone by tampering with traffic lights!
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This is a brief followup to my previous post “A Personal Note: Mysterious Accident”
UPDATE: August 24, 2017
There are some known cases of hacking/tampering with traffic lights.
According to the Los Angeles Times, in 2009, two Los Angeles traffic engineers pleaded guilty to hacking into the city’s signal system and slowing traffic at key intersections as part of a labor protest in 2006.
According to the San Francisco Chronicle, in June 2005, police in Sunnyvale, California (where my accident occurred) requested assistance from the public to find a suspected sophisticated “trickster” who had been tampering with traffic lights for several months.
END UPDATE: August 24, 2017
It is possible to hack traffic lights and there has been some published research into how to do it for some traffic light systems. Here are some links to articles and videos on the subject, mostly from 2014:
http://thehackernews.com/2014/08/hacking-traffic-lights-is-amazingly_20.html
https://www.wired.com/2014/04/traffic-lights-hacking/
https://www.schneier.com/blog/archives/2014/08/hacking_traffic.html
https://www.technologyreview.com/s/530216/researchers-hack-into-michigans-traffic-lights/
Talk by Cesar Cerrudo at DEFCON 22 on Hacking Traffic Lights
Someone with sufficient physical access to the traffic lights could always modify the hardware even if a computer-style “hack” was impossible.
I was driving a 1995 Nissan 200SX SE-R with minimal built-in electronics by modern car standards. It would be difficult to hack my car without physical access and it was either with me, in a brightly lit parking lot at my office, or in a secured parking garage at my apartment building.
Just to be clear I am not saying my accident was caused by hacking of the traffic lights, only that it is possible. As noted in my previous post, there are other possible explanations: an accidental failure of the traffic lights or a remarkable mental lapse on my part. None of the three explanations seems likely to me.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I had a serious accident on July 19, 2017 at about 6:30 AM in the morning making a left turn from the off ramp of Central Expressway East onto North Wolfe Road in Sunnyvale, California. Fortunately no one was seriously injured but I could easily have been killed and my car was totaled. I have some whiplash and may have had a very mild concussion.
The accident is something of a mystery. I distinctly remember stopping at the red light at the off ramp from Central Expressway and Wolfe Road. Then the light turned green and I made a left turn across the three lanes of South Wolfe Road. I make this turn almost every morning. I was awake, alert. I was not texting or doing anything reckless. I am generally a cautious driver; people have complained about it.
I had a glancing collision with an SUV coming down North Wolfe that should have had a red light but seemingly did not. The lights from both directions are extremely obvious at this intersection. I was extremely surprised both by the SUV and to see the light that should have stopped the SUV was green when I pulled over. I don’t think the SUV ran a red light although it is hard to be absolutely certain.
Three Unlikely Explanations
I seem to be left with three unlikely explanations. Despite my distinct memory and natural caution, I somehow made a left turn against multiple bright red lights directly in front of me and in my field of view.

(OR) The lights changed improperly giving both the other driver and myself green lights at the same time due to an electrical or electronic failure.

(OR) The lights changed improperly giving both the other driver and myself green lights at the same time because someone tampered with the lights somehow, presumably either a dangerous prank or attempted homicide.
None of these possibilities seems particularly probable, but it seems that the explanation for the accident must be one of them.
Mental glitches of this type may happen but must be very rare. I was wide awake, alert, have made the turn many times and am familiar with the intersection. I am a cautious driver. The red lights should have been easily and clearly visible. I was in good health with no noticeable cognitive issues in the last several years. I remember seeing the red lights and the light changing green and very distinctly no red lights as I made the left turn.
There is a lot of construction at and near the intersection of Wolfe Road and Central Expressway in Sunnyvale that seems associated with an office building under construction in the block bordered by Wolfe, Central, Arques, and Commercial Street. The new office building faces Wolfe and Arques.

There is a lot of work going on right at the intersection of Central Expressway, technically the on/off ramps, and Wolfe Road.

There were a lot of signs for construction in and around the intersection between Wolfe and the Central Expressway on/off ramps when the accident occurred although I did not see any workmen (it was about 6:30 AM and there do not seem to have been any witnesses).
The question arises whether the construction could have caused a glitch in the lights. To be sure, the lights could have some very rare, bizarre failure mode not due to the construction as well but surely this is less likely than a problem related to the construction.
Then, finally, there is the possibility of deliberate tampering with the traffic lights. This could just be some random, extremely dangerous “prank” or an attempt to kill, harm, or frighten either the other driver or myself (I did not and do not know the other driver). It is a bit concerning coming twelve days after my personal storage locker was broken into (July 7, 2017).
It is difficult to know what to make of deliberate tampering with the traffic lights. Many years ago I worked briefly for a company that shall remain nameless where I developed very serious concerns about the company and the people connected to it after I took the job. I didn’t hang around. They would be my leading suspects if there was tampering but it has been a long time. They would be risking the spotlight of unwanted public attention if they tried to kill me.
I am left with a mystery. None of the three explanations — a serious mental glitch on my part, an improbable electronic failure of the traffic lights, or deliberate tampering with the traffic lights by a person or persons unknown — seems likely, but presumably one of them happened. Previous accidents that I have had have been minor and it was always clear what had happened. 🙁
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
An Unconvincing Argument
One of the most common arguments for learning math (or computer programming or chess or <insert your favorite subject here>) is that math teaches you to think. This argument has a long history of failing to convince skeptical students and adults especially where more advanced mathematics such as algebra and calculus is concerned.
The “math teaches you to think” argument has several problems. Almost any intellectual activity including learning many sports teaches you to think. Reading Shakespeare teaches you to think. Playing Dungeons and Dragons teaches you to think. What is so special about math?
Math teaches ways of thinking about quantitative problems that can be very powerful. As I have argued in a previous post Why Should You Learn Mathematics? mathematics is genuinely needed to make informed decisions about pharmaceuticals and medical treatments, finance and real estate, important public policy issues such as global warming, and other specialized but important areas. The need for mathematics skills and knowledge beyond the basic arithmetic level is growing rapidly due to the proliferation of, use, and misuse of statistics and mathematical modeling in recent years.
Book Smarts Versus Street Smarts
However, most math courses and even statistics courses such as AP Statistics teach ways of thinking that do not work well or even work at all for many “real world” problems, social interactions, and human society.
This is not a new problem. One of Aesop’s Fables (circa 620 — 524 BC) is The Astronomer which tells the tale of an astronomer who falls into a well while looking up at the stars. The ancient mathematics of the Greeks, Sumerians, and others had its roots in ancient astronomy and astrology.
Why does mathematical thinking often fail in the “real world?” Most mathematics education other than statistics teaches that there is one right answer which can be found by precise logical and mathematical steps. Two plus two is four and that is it. The Pythagorean Theorem is proven step by step by rigorous logic starting with Euclid’s Postulates and Definitions. There is no ambiguity and no uncertainty and no emotion.
If a student tries to apply this type of rigorous, exact thinking to social interactions, human society, even walking across a field where underbrush has obscured a well as in Aesop’s Fable of the Astronomer, the student will often fail. Indeed, the results can be disastrous as in the fable.
In fact, at the K-12 level and even college, liberal arts such as English literature, history, debate, the law do a much better job than math in teaching students the reality that in many situations there are many possible interpretations. Liberal arts deals with people and even the most advanced mathematics has failed to duplicate the human mind.
In dealing with other people, we can’t read their minds. We have to guess (estimate) what they are thinking to predict what they may do in the future. We are often wrong. Mathematical models of human behavior generally don’t predict human behavior reliably. Your intuition from personal experience, learning history, and other generally non-quantitative sources is often better.
The problem is not restricted to human beings and human society. When navigating in a room or open field, some objects will be obscured by other objects or we won’t happen to be looking at them. Whether we realize it or not, we are making estimates — educated guesses — about physical reality. A bush might be just a bush or it might hide a dangerous well that one can fall into.
The Limits of Standard Statistics Courses
It is true that statistics courses such as AP Statistics and/or more advanced college and post-graduate statistics addresses these problems to some degree: unlike basic arithmetic, algebra, and calculus. The famous Bayes Theorem gives a mathematical framework for estimating the probability that a hypothesis is true given the data/observations/evidence. It allows us to make quantitative comparisons between competing hypotheses: just a bush versus a bush hiding a dangerous well.
However, many students at the K-12 level and even college get no exposure to statistics or very little. How many students understand Bayes Theorem? More importantly, there are significant unknowns in the interpretation and proper application of Bayes Theorem to the real world. How many students or even practicing statisticians properly understand the complex debates over Bayes Theorem, Bayesian versus frequentist versus several other kinds of statistics?
All or nearly all statistics that most students learn is based explicitly or implicitly on the assumption of independent identically distributed random variables. These are cases like flipping a “fair” coin where the probability of the outcome is the same every time and is not influenced by the previous outcomes. Every time someone flips a “fair” coin there is the same fifty percent chance of heads and the same fifty percent chance of tails. The coin flips are independent. It does not matter whether the previous flip was heads or tails. The coin flips are identically distributed. The probability of heads or tails is always the same.
The assumption of independent identically distributed is accurate or very nearly accurate for flipping coins, most “fair” games of chance used as examples in statistics courses, radioactive decay, and some other natural phenomena. It is generally not true for human beings and human society. Human beings learn from experience and change over time. Various physical things in the real world also change over time.
Although statistical thinking is closer to the “real world” than many other commonly taught forms of mathematics, it still in practice deviates substantially from everyday experience.
Teaching Students When to Think Mathematically
Claims that math (or computer programming or chess or <insert your favorite subject here>) teaches thinking should be qualified with what kind of thinking is taught, what are its strengths and weaknesses, and what problems is it good for solving.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Credits
The image of a Latin proof of the Pythagorean Theorem with diagrams is from Wikimedia Commons and is in the public domain. The original source is a manuscript from 1200 A.D.
We received a very official looking letter today from Corporate Compliance Services, seeming to be from a federal government agency without actually stating this. The document asked us to send a check or money order for $84 to Corporate Compliance Services for US federal government required posters for our workplace.

This is a scam. The United States Department of Labor does indeed require that employers display posters informing employees of their rights under various laws such as the Fair Labor Standards Act (FLSA), but these are available for free from the US Department of Labor.

The United States Department of Labor web site has a simple, easy-to-use eLaws Advisor to help you determine which posters are required for your business and to then locate and download the required posters for free.
http://webapps.dol.gov/elaws/posters.htm
Some Internet Links about Corporate Compliance Services
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).

Why should you learn mathematics? By mathematics, I am not referring to basic arithmetic: addition, subtraction, multiplication, division, and raising a number to a power — for example for an interest calculation in personal finance. There is little debate that in the modern world the vast majority of people need to know basic arithmetic to buy and sell goods and services and perform many other common tasks. By mathematics I mean more advanced mathematics such as algebra, geometry, trigonometry, calculus, linear algebra, and college level statistics.
I am not referring to highly specialized advanced areas of mathematics such as number theory or differential geometry generally taught after the sophomore year in college or in graduate school.
I am following the language of Andrew Hacker in his book The Math Myth: And Other STEM Delusions in which he argues the algebra requirement should be eliminated in high schools, community colleges, and universities except for degrees that genuinely require mathematics. Hacker draws a distinction between arithmetic which is clearly needed by all and mathematics such as algebra which few use professionally.
A number of educators such as Eloy Ortiz Oakley, the chancellor of California’s community colleges, have embraced a similar view, even arguing that abolishing the algebra requirement is a civil rights issue since some minority groups fail the algebra requirement at higher rates than white students. Yes, he did say it is a civil rights issue:
The second thing I’d say is yes, this is a civil rights issue, but this is also something that plagues all Americans — particularly low-income Americans. If you think about all the underemployed or unemployed Americans in this country who cannot connect to a job in this economy — which is unforgiving of those students who don’t have a credential — the biggest barrier for them is this algebra requirement. It’s what has kept them from achieving a credential.
(emphasis added)
Eloy Ortiz Oakley on NPR (Say Goodbye to X + Y: Should Community Colleges Abolish Algebra? July 19, 2017)
At present, few jobs, including the much ballyhooed software development jobs, require more than basic arithmetic as defined above. For example, the famous code.org “What Most Schools Don’t Teach” video on coding features numerous software industry luminaries assuring the audience how easy software development is and how little math is involved. Notably Bill Gates at one minute and forty-eight seconds says: “addition, subtraction…that’s about it.”
Bill Gates assessment of the math required in software development today is largely true unless you are one of the few percent of software developers working on highly mathematical software: video codecs, speech recognition engines, gesture recognition algorithms, computer graphics for games and video special effects, GPS, Deep Learning, FDA drug approvals, and other exotic areas.
Thus, the question arises why people who do not use mathematics professionally ought to learn mathematics. I am not addressing the question of whether there should be a requirement to pass algebra to graduate high school or for a college degree such a veterinary degree where there is no professional need for mathematics. The question is whether people who do not need mathematics professionally should still learn mathematics — whether it is required or not.
People should learn mathematics because they need mathematics to make informed decisions about their health care, their finances, public policy issues that affect them such as global warming, and engineering issues such as the safety of buildings, aircraft, and automobiles — even though they don’t use mathematics professionally.
The need to understand mathematics to make informed decisions is increasing rapidly with the proliferation of “big data” and “data science” in recent years: the use and misuse of statistics and mathematical modeling on the large, rapidly expanding quantities of data now being collected with extremely powerful computers, high speed wired and wireless networks, cheap data storage capacity, and inexpensive miniature sensors.
Health and Medicine
An advanced knowledge of statistics is required to evaluate the safety and effectiveness of drugs, vaccines, medical treatments and devices including widely used prescription drugs. A study by the Mayo Clinic in 2013 found that nearly 7 in 10 (70%) of Americans take at least one prescription drug. Another study published in the Journal of the American Medical Association (JAMA) in 2015 estimated about 59% of Americans are taking a prescription drug. Taking a prescription drug can be a life and death decision as the horrific case of the deadly pain reliever Vioxx discussed below illustrates.
The United States and the European Union have required randomized clinical trials and detailed sophisticated statistical analyses to evaluate the safety and effectiveness of drugs, medical devices, and treatments for many decades. Generally, these analyses are performed by medical and pharmaceutical companies who have an obvious conflict of interest. At present, doctors and patients often find themselves outmatched in evaluating the claims for the safety and effectiveness of drugs, both new and old.
In the United States, at least thirty-five FDA approved drugs have been withdrawn due to serious safety problems, generally killing or contributing to the deaths of patients taking the drugs.
The FDA has instituted an FDA Adverse Events Reporting System (FDAERS) for doctors and other medical professionals to report deaths and serious health problems such as hospitalization suspected of being caused by adverse reactions to drugs. In 2014, 123,927 deaths were reported to the FDAERS and 807,270 serious health problems. Of course, suspicion is not proof and a report does not necessarily mean the reported drug was the cause of the adverse event.
Vioxx (generic name rofecoxib) was a pain-killer marketed by the giant pharmaceutical company Merck (NYSE:MRK) between May of 1999 when it was approved by the United States Food and Drug Administration (FDA) and September of 2004 when it was withdrawn from the market. Vioxx was marketed as a “super-aspirin,” allegedly safer and implicitly more effective than aspirin and much more expensive, primarily to elderly patients with arthritis or other chronic pain. Vioxx was a “blockbuster” drug with sales peaking at about $2.5 billion in 2003 1 and about 20 million users 2. Vioxx probably killed between 20,000 and 100,000 patients between 1999 and 2004 3.
Faulty blood clotting is thought to be the main cause of most heart attacks and strokes. Unlike aspirin, which lowers the probability of blood coagulation (clotting) and therefore heart attacks and strokes, Vioxx increased the probability of blood clotting and the probability of strokes and heart attacks by about two to five times.
Remarkably, Merck proposed and the FDA approved Phase III clinical trials of Vioxx with too few patients to show that Vioxx was actually safer than the putative 3.8 deaths per 10,000 patients rate (16,500 deaths per year according to a controversial study used to promote Vioxx) from aspirin and other non-steroidal anti-inflammatory drugs (NSAIDs) such as ibuprofen (the active ingredient in Advil and Motrin), naproxen (the active ingredient in Aleve), and others.
The FDA guideline, Guideline for Industry: The Extent of Population Exposure to Assess Clinical Safety: For Drugs Intended for Long-Term Treatment of Non-Life-Threatening Conditions (March 1995), only required enough patients in the clinical trials to reliably detect a risk of about 0.5 percent (50 deaths per 10,000) of death in patients treated for six months or less (roughly equivalent to one percent death rate for one year assuming a constant risk level) and about 3 percent (300 deaths per 10,000) for one year (recommending about 1,500 patients for six months or less and about 100 patients for at least one year without supporting statistical power computations and assumptions in the guideline document).
The implicit death rate detection threshold in the FDA guideline was well above the risk from aspirin and other NSAIDs and at the upper end of the rate of cardiovascular “events” caused by Vioxx. FDA did not tighten these requirements for Vioxx even though the only good reason for the drug was improved safety compared to aspirin and other NSAIDs. In general, the randomized clinical trials required by the FDA for drug approval have too few patients – insufficient statistical power in statistics terminology – to detect these rare but deadly events 4.
To this day, most doctors and patients lack the statistical skills and knowledge to evaluate the safety level that can be inferred from the FDA required clinical trials. There are many other advanced statistical issues in evaluating the safety and effectiveness of drugs, vaccines, medical treatments, and devices.
Finance and Real Estate
Mathematical models have spread far and wide in finance and real estate, often behind the scenes invisible to casual investors. A particularly visible example is Zillow’s ZEstimate of the value of homes, consulted by home buyers and sellers every day. Zillow is arguably the leading online real estate company. In March 2014, Zillow had over one billion page views, beating competitors Trulia.com and Realtor.com by a wide margin; Zillow has since acquired Trulia.
According to a 2013 Gallup poll, sixty-two percent (62%) of Americans say they own their home. According to a May 2014 study by the Consumer Financial Protection Bureau, about eighty percent (80%) of Americans 65 and older own their home. Homes are a large fraction of personal wealth and retirement savings for a large percentage of Americans.
Zillow’s algorithm for valuing homes is proprietary and Zillow does not disclose the details and/or the source code. Zillow hedges by calling the estimate an “estimate” or a “starting point.” It is not an appraisal.
However, Zillow is large and widely used, claiming estimates for about 110 million homes in the United States. That is almost the total number of homes in the United States. There is the question whether it is so large and influential that it can effectively set the market price.
Zillow makes money by selling advertising to realty agents. Potential home buyers don’t pay for the estimates. Home sellers and potential home sellers don’t pay directly for the estimates either. This raises the question whether the advertising business model might have an incentive for a systematic bias in the estimates. One could argue that a lower valuation would speed sales and increase commissions for agents.
Zillow was recently sued in Illinois over the ZEstimate by a homeowner — real estate lawyer Barbara Andersen 🙂 — claiming the estimate undervalued her home and made it difficult therefore to sell the home. The suit argues that the estimate is in fact an appraisal, despite claims to the contrary by Zillow, and therefore subject to Illinois state regulations regarding appraisals. Andersen has reportedly dropped this suit and expanded to a class-action lawsuit by home builders in Chicago again alleging that the ZEstimate is an appraisal and undervalues homes.
The accuracy of Zillow’s estimate has been questioned by others over the years including home owners, real estate agents, brokers, and the Los Angeles Times. Complaints often seem to involve alleged undervaluation of homes.
On the other hand, Zillow CEO Spencer Rascoff’s Seattle home reportedly sold for $1.05 million on Feb. 29, 2016, 40 percent less than the Zestimate of $1.75 million shown on its property page a day later (March 1, 2016). 🙂
As in the example of Vioxx and other FDA drug approvals, it is actually a substantial statistical analysis project to independently evaluate the accuracy of Zillow’s estimates. What do you do if Zillow substantially undervalues your home when you need to sell it?
Murky mathematical models of the value of mortgage backed securities played a central role in the financial crash in 2008. In this case, the models were hidden behind the scenes and invisible to casual home buyers or other investors. Even if you are aware of these models, how do you properly evaluate their effect on your investment decisions?
Public Policy
Misleading and incorrect statistics have a long history in public policy and government. Darrell Huff’s classic How to Lie With Statistics (1954) is mostly concerned with misleading and false polls, statistics, and claims from American politics in the 1930’s and 1940’s. It remains in print, popular and relevant today. Increasingly however political controversies involve often opaque computerized mathematical models rather than the relatively simple counting statistics debunked in Huff’s classic book.
Huff’s classic and the false or misleading counting statistics in it generally required only basic arithmetic to understand. Modern political controversies such as Value Added Models for teacher evaluation and the global climate models used in the global warming controversy go far beyond basic arithmetic and simple counting statistics.
The Misuse of Statistics and Mathematics
Precisely because many people are intimidated by mathematics and had difficulty with high school or college mathematics classes including failing the courses, statistics and mathematics are often used to exploit and defraud people. Often the victims are the poor, marginalized, and poorly educated. Mathematician Cathy O’Neil gives many examples of this in her recent book Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy (2016).
The misuse of statistics and mathematics is not limited to poor victims. Bernie Madoff successfully conned large numbers of wealthy, highly educated investors in both the United States and Europe using the arcane mathematics of options as a smokescreen. These sophisticated investors were often unable to perform the sort of mathematical analysis that would have exposed the fraud.
Rich and poor alike need to know mathematics to protect themselves from this frequent and growing misuse of statistics and mathematics.
Algebra and College Level Statistics
The misleading and false counting statistics lampooned by Darrell Huff in How to Lie With Statistics does not require algebra or calculus to understand. In contrast, the college level statistics often encountered in more complex issues today does require a mastery of algebra and sometimes calculus.
For example, one of the most common probability distributions encountered in real data and mathematical models is the Gaussian, better known as the Normal Distribution or Bell Curve. This is the common expression for the Gaussian in algebraic notation.
[latex]{P(x) = \frac{1}{{\sigma \sqrt {2\pi } }}e^{{{ – \left( {x – \mu } \right)^2 } \mathord{\left/ {\vphantom {{ – \left( {x – \mu } \right)^2 } {2\sigma ^2 }}} \right. \kern-\nulldelimiterspace} {2\sigma ^2 }}}}[/latex]
[latex]x[/latex] is the position of the data point. [latex]\mu[/latex] is the mean of the distribution. If I have a data set obeying the Normal Distribution, most of the data points will be near the mean [latex]\mu[/latex] and fewer further away. [latex]\sigma[/latex] is the standard deviation — loosely the width — of the distribution. [latex]\pi[/latex] is the ratio of the circumference of a circle to the diameter. [latex]e[/latex] is Euler’s number (about 2.718281828459045).
This is a histogram of simulated data following the Normal Distribution/Bell Curve/Gaussian with a mean [latex]\mu[/latex] of zero (0.0) and a standard deviation [latex]\sigma[/latex] of one (1.0):
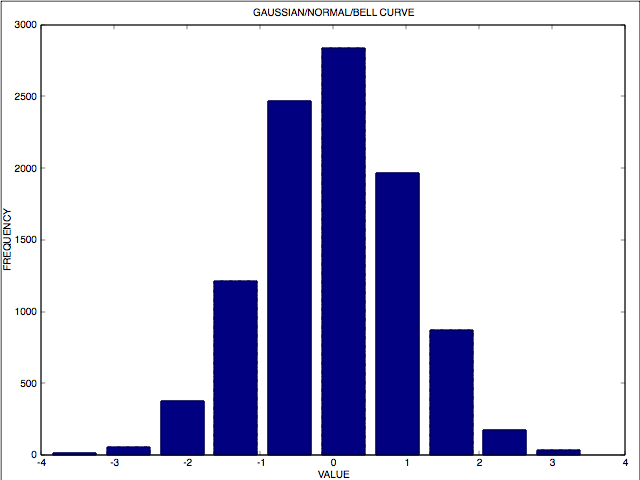
To truly understand the Normal Distribution you need to know Euler’s number e and algebraic notation and symbolic manipulation. It is very hard to express the Normal Distribution with English words or basic arithmetic. The Normal Distribution is just one example of the use of algebra in college level statistics. In fact, an understanding of calculus is needed to have a solid understanding and mastery of college level statistics.
Conclusion
People should learn mathematics — meaning subjects beyond basic arithmetic such as algebra, geometry, trigonometry, calculus, linear algebra, and college level statistics — to make informed decisions about their health care, personal finances and retirement savings, important public policy issues such as teacher evaluation and public education, and other key issues such as evaluating the safety of buildings, airplanes, and automobiles.
There is no doubt that many people experience considerable difficulty learning mathematics whether due to poor teaching, inadequate learning materials or methods, or other causes. There is and has been heated debate over the reasons. These difficulties are not an argument for not learning mathematics. Rather they are an argument for finding better methods to learn and teach mathematics to everyone.
End Notes
1 “How did Vioxx debacle happen?” By Rita Rubin, USA Today, October 12, 2004 The move was a stunning denouement for a blockbuster drug that had been marketed in more than 80 countries with worldwide sales totaling $2.5 billion in 2003.
2 Several estimates of the number of patients killed and seriously harmed by Vioxx were made. Dr. David Graham’s November 2004 Testimony to the US Senate Finance Committee gives several estimates including his own.
3 A “blockbuster” drug is pharmaceutical industry jargon for a drug with at least $1 billion in annual sales. Like Vioxx, it need not be a “wonder drug” that cures or treats a fatal or very serious disease or condition.
4 Drug safety assessment in clinical trials: methodological challenges and opportunities
Sonal Singh and Yoon K Loke
Trials 2012 13:138
DOI: 10.1186/1745-6215-13-138© Singh and Loke; licensee BioMed Central Ltd. 2012
Received: 9 February 2012 Accepted: 30 July 2012 Published: 20 August 2012
The premarketing clinical trials required for approval of a drug primarily guard against type 1 error. RCTs are usually statistically underpowered to detect the specific harm either by recruitment of a low-risk population or low intensity of ascertainment of events. The lack of statistical significance should not be used as proof of clinical safety in an underpowered clinical trial.
Credits
The image of an ancient mathematician or engineer with calipers, often identified as Euclid or Archimedes, is from The School of Athens fresco by Raphael by way of Wikimedia Commons. It is in the public domain.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).