Vioxx: The Case of the Deadly Data Analysis (Video)
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Remarkably, this article prominently claims a shortage of STEM workers in the United States, citing a study by the National Association of Manufacturers (NAM) and the Deloitte accounting firm claiming that employers will need to fill 3.5 million STEM jobs by 2025, with more than 2 million of them going unfilled because of the lack of highly skilled candidates in demand, while also stating:
Higher barriers to H-1B visa access is compounding the STEM shortage: there are low numbers of U.S. STEM field graduates coupled with decreasing foreign STEM talent to mitigate the supply shortage. Forbes reportsin 2016 that there were 568,000 STEM graduates in the U.S., compared to 2.6 million in India and 4.7 million in China.
Emphasis Added
Note that an annual rate of production of 568,000 STEM graduates in the United States multiplied by the seven years between 2018 (the date of the article) and the 2025 date of the NAM/Deloitte projection gives over 3.9 million STEM graduates, substantially more than the NAM projection of 3.5 million jobs to be filled. Thus:
What STEM Shortage?
In fact according to the US Census about half of all US college graduates with STEM degrees are not working in STEM professions despite pervasive claims of a desperate or severe shortage of STEM graduates by STEM employers and others! (For a more in depth discussion of STEM shortage numbers see my recent article “A Skeptical Look at STEM Shortage Numbers“)
Note that the Recruiting Today article, repeating a common theme in STEM shortage claims, attributes the non-existent STEM shortage to a lack of interest in STEM fields by pre-teen and teen K-12 students in the United States, implicitly absolving colleges and universities (or STEM employers) of any responsibility for the alleged STEM shortage. At the same time it actually cites a number of annual STEM graduates that grossly contradicts its assertion of lack of interest in STEM fields and its central claim of a STEM shortage at all.
Neither the article’s author or presumably editor at Recruiting Daily nor Google nor Google’s vaunted ranking algorithm seems to have noticed this astonishing contradiction.
Why is an article on “STEM shortage” with such an extreme (and unexplained) internal inconsistency ranked number oneon Google?
(C) 2019 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
How to Tell Scientifically if Advertising Works Explainer Video
[Slide 1]
“Half the money
I spend on advertising is wasted; the trouble is I don’t know which
half.”
This popular quote
sums up the problem with advertising.
[Slide 2]
There are many
advertising choices today including not advertising, relying on word
of mouth and other “organic” growth. Is the advertising
working?
[Slide 3]
Proxy measures such
as link clicks can be highly misleading. A bad advertisement can get
many clicks, even likes but reduce sales by making the product look
bad in an entertaining way.
[Animation Enter]
[Wait 2 seconds]
[Slide 4]
Did the advertising
increase sales and profits? This requires analysis of the product
sales and advertising expenses from your accounting program such as
QuickBooks. Raw sales reports are often difficult to interpret
unless the boost in sales is extremely large such as doubling sales.
Sales are random like flipping a coin. This means a small but
profitable increase such as twenty percent is often difficult to
distinguish from chance alone.
[Slide 5]
Statistical analysis
and computer simulation of a business can give a quantitative,
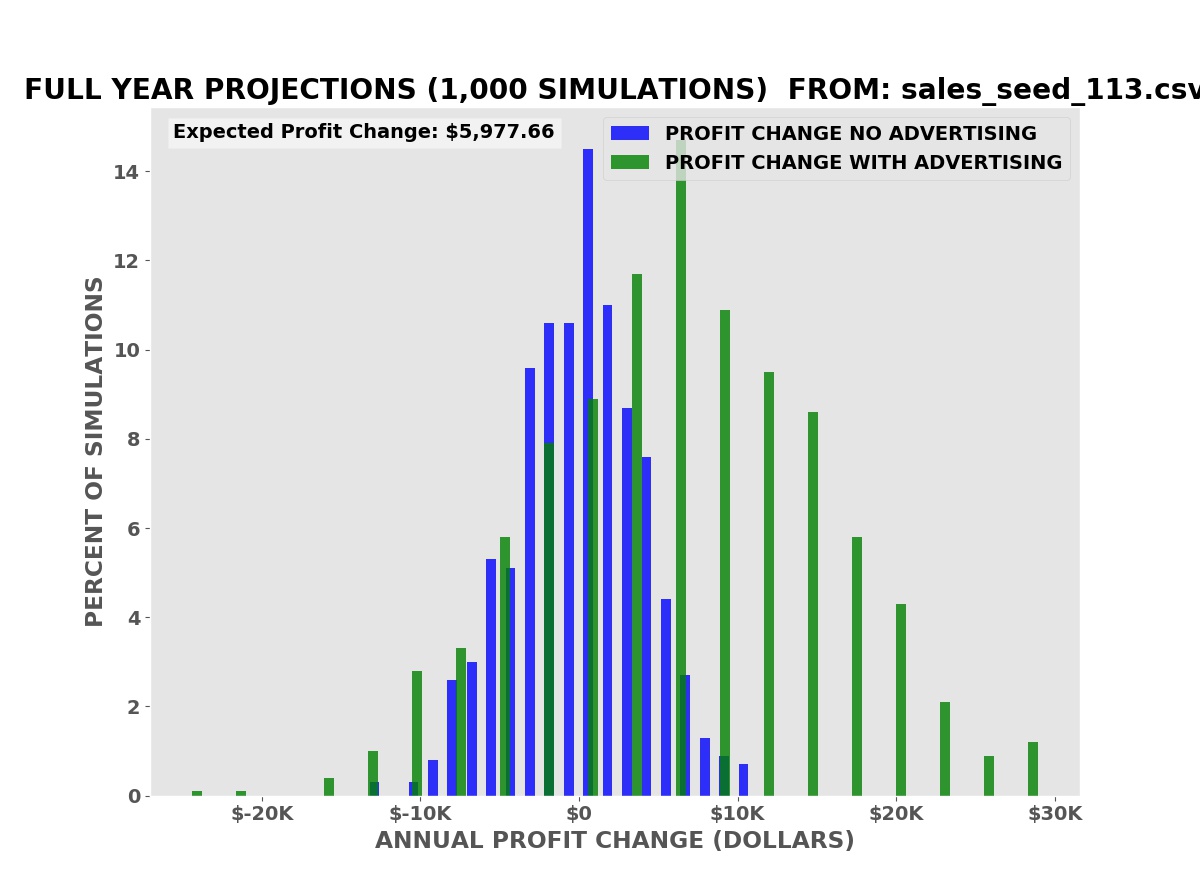
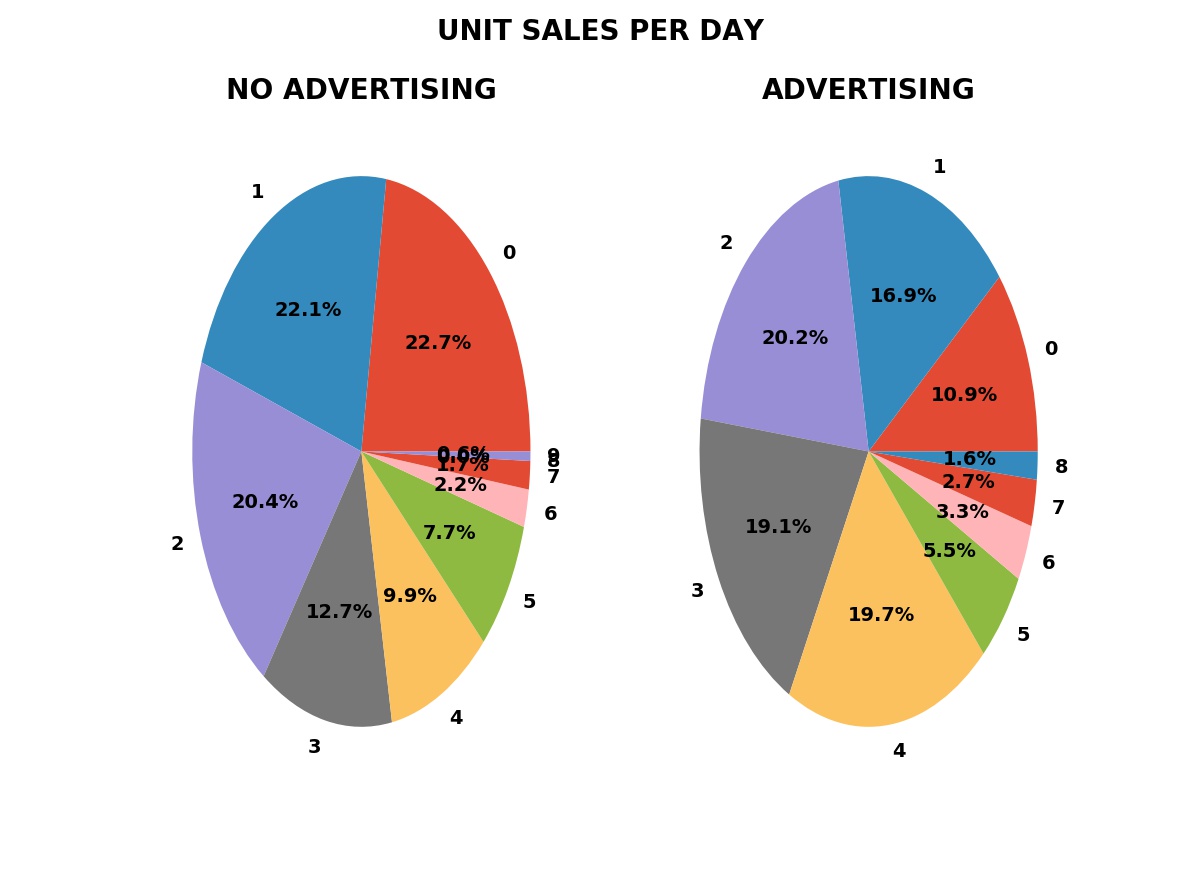
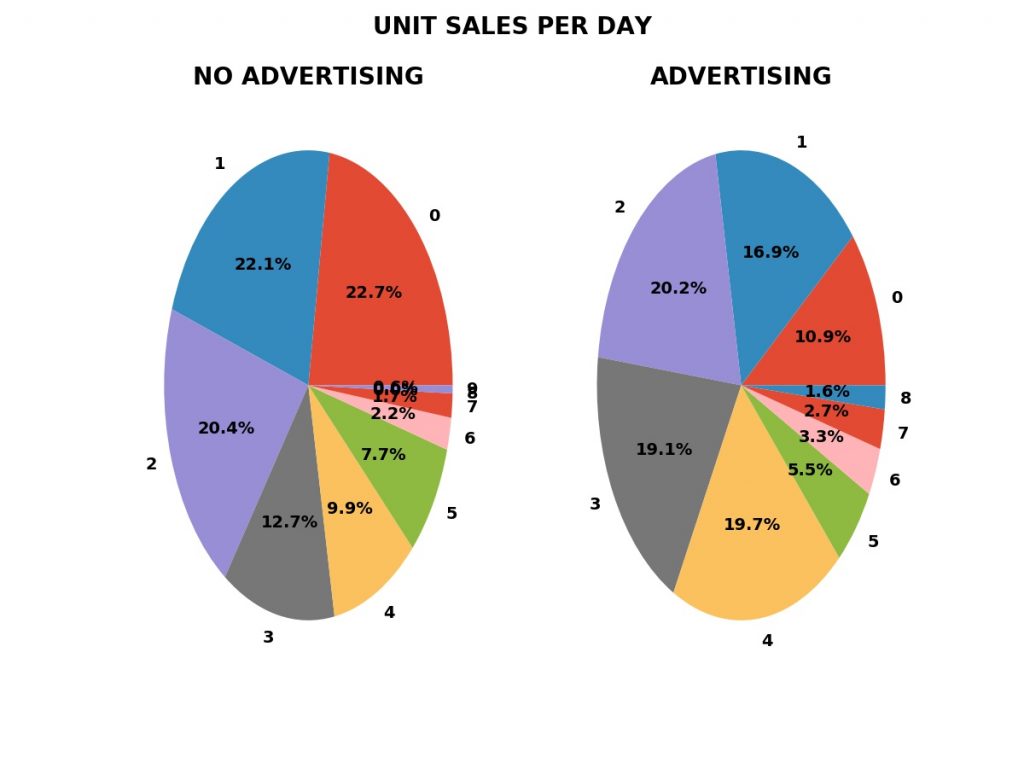
PREDICTIVE answer. We can measure the fraction of days with zero,
one, two, or more unit sales with advertising — the green bars in
the plot shown — and without advertising, the blue bars.
[Slide 6]
With these
fractions, we can simulate the business with and without advertising.
The bar chart shows
the results for one thousand simulations of a year of business
operations. Because sales are random like flipping a coin, there
will be variations in profit from simulation to simulation due to
chance alone.
The horizontal axis
shows the change in profits in the simulation compared to the actual
sales without advertising. The height of the bars shows the FRACTION
of the simulations with the change in profits on the horizontal axis.
The blue bars are
the fractions for one-thousand simulations without advertising.
[Animation Enter]
The green bars are
the fractions for one-thousand simulations with advertising.
[Animation Enter]
The vertical red bar
shows the average change in profits over ALL the simulations WITH THE
ADVERTISING.
There is ALWAYS an
increased risk from the fixed cost of the advertising — $500 per
month, $6,000 per year in this example. The green bars in the lower
left corner show the increased risk with advertising compared to the
blue bars without advertising.
If the advertising
campaign increases profits on average and we can afford the increased
risk, we should continue the advertising.
[Slide 7]
This analysis was
performed with Mathematical Software’s AdEvaluator Free Open Source
Software. AdEvaluator works for sales data where there is a SINGLE
change in the business, a new advertising campaign.
Our AdEvaluator Pro
software for which we will charge money will evaluate cases with
multiple changes such as a price change and a new advertising
campaign overlapping.
Click on the
Downloads TAB for our Downloads page.
[Web Site Animation
Exit]
[Download Links
Animation Entrance]
AdEvaluator can be
downloaded from GitHub or as a ZIP file directly from the downloads
page on our web site.
[Download Links
Animation Exit]
Or scan this QR code
to go to the Downloads page.
This is John F.
McGowan, Ph.D., CEO of Mathematical Software. I have many years
experience solving problems using mathematics and mathematical
software including work for Apple, HP Labs, and NASA. I can be
reached at ceo@mathematical-software.com
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
AdEvaluator™ evaluates the effect of advertising (or marketing, sales, or public relations) on sales and profits by analyzing a sales report in comma separated values (CSV) format from QuickBooks or other accounting programs. It requires a reference period without the advertising and a test period with the advertising. The advertising should be the only change between the two periods. There are some additional limitations explained in the on-line help for the program.
(C) 2019 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
How to Tell Scientifically if Advertising Boosts Profits Video
Short (seven and one half minute) video showing how to evaluate scientifically if advertising boosts profits using mathematical modeling and statistics with a pitch for our free open source AdEvaluator™ software and a teaser for our non-free AdEvaluator Pro™software — coming soon.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John Wanamaker, (attributed) US department store merchant (1838 – 1922)
Between $190 billion and $270 billion is spent on advertising in the United States each year (depending on source). It is often hard to tell whether the advertising boosts sales and profits. This is caused by the unpredictability of individual sales and in many cases the other changes in the business and business environment occurring in addition to the advertising. In technical terms, the evaluation of the effect of advertising on sales and profits is often a multidimensional problem.
Many common metrics such as the number of views, click through rates (CTR), and others do not directly measure the change in sales or profits. For example, an embarrassing or controversial video can generate large numbers of views, shares, and even likes on a social media site and yet cause a sizable fall in sales and profits.
Because individual sales are unpredictable, it is often difficult or impossible to tell whether a change in sales is caused by advertising, simply due to chance alone or some combination of advertising and luck.
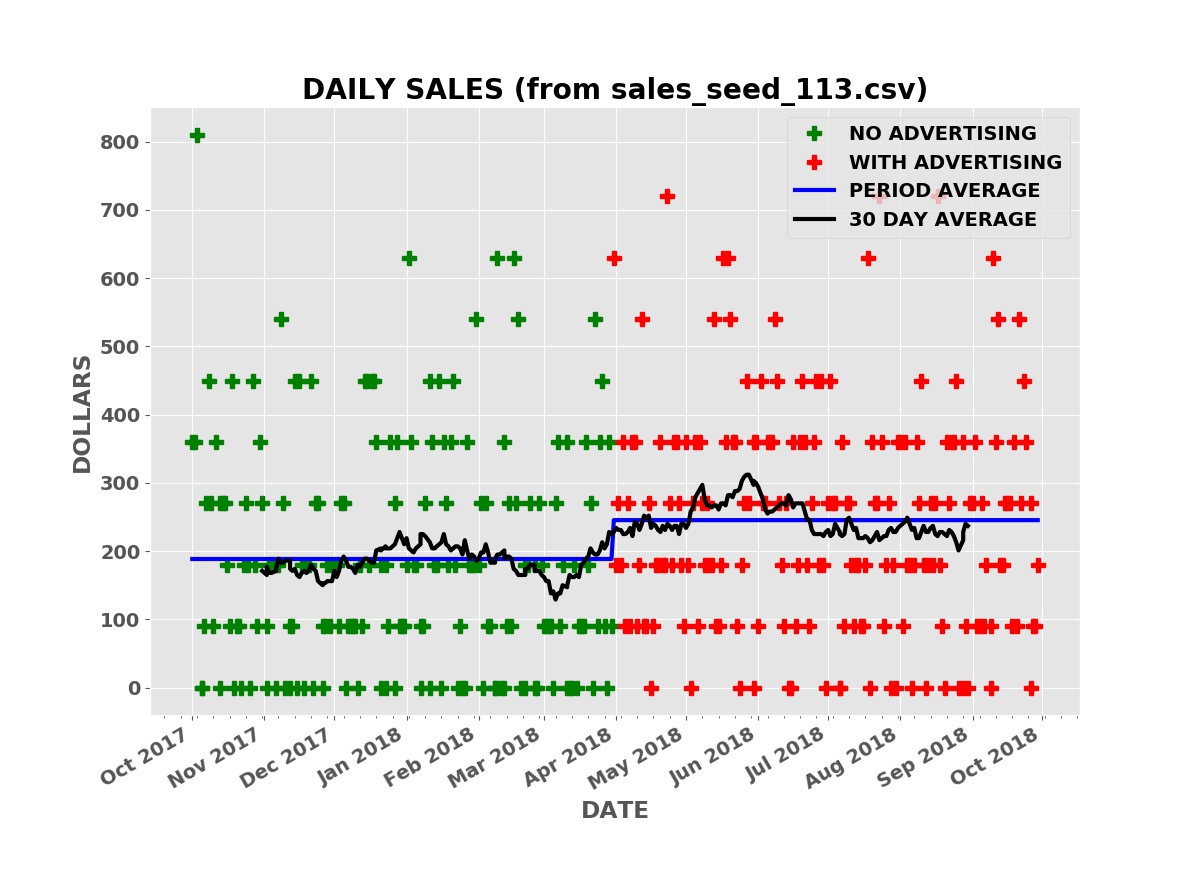
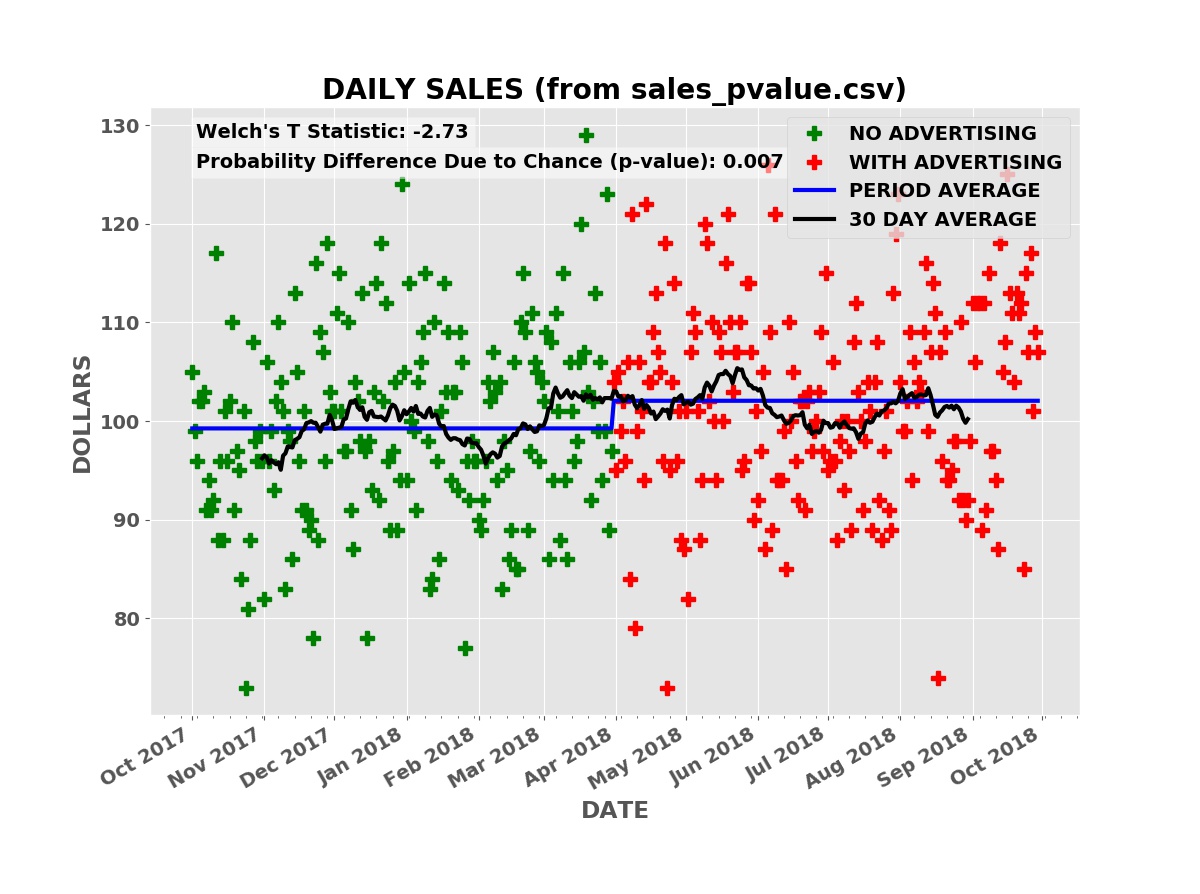
The plot below shows the simulated daily sales for a product or service with a price of $90.00 per unit. Initially, the business has no advertising, relying on word of mouth and other methods to acquire and retain customers. During this “no advertising” period, an average of three units are sold per day. The business then contracts with an advertising service such as Facebook, Google AdWords, Yelp, etc. During this “advertising” period, an average of three and one half units are sold per day.
Daily Sales
The raw daily sales data is impossible to interpret. Even looking at the thirty day moving average of daily sales (the black line), it is far from clear that the advertising campaign is boosting sales.
Taking the average daily sales over the “no advertising” period, the first six months, and over the “advertising” period (the blue line), the average daily sales was higher during the advertising period.
Is the increase in sales due to the advertising or random chance or some combination of the two causes? There is always a possibility that the sales increase is simply due to chance. How much confidence can we have that the increase in sales is due to the advertising and not chance?
This is where statistical methods such as Student’s T test, Welch’s T test, mathematical modeling and computer simulations are needed. These methods compute the effectiveness of the advertising in quantitative terms. These quantitative measures can be converted to estimates of future sales and profits, risks and potential rewards, in dollar terms.
Measuring the Difference Between Two Random Data Sets
In most cases, individual sales are random events like the outcome of flipping a coin. Telling whether sales data with and without advertising is the same is similar to evaluating whether two coins have the same chances of heads and tails. A “fair” coin is a coin with an equal chance of giving a head or a tail when flipped. An “unfair” coin might have a three fourths chance of giving a head and only a one quarter chance of giving a tail when flipped.
If I flip each coin once, I cannot tell the difference between the fair coin and the unfair coin. If I flip the two coins ten times, on average I will get five heads from the fair coin and seven and one half (seven or eight) heads from the unfair coin. It is still hard to tell the difference. With one hundred times, the fair coin will average fifty heads and the unfair coin seventy-five heads. There is still a small chance that the seventy five heads came from a fair coin.
The T statistics used in Student’s T test (Student was a pseudonym used by statistician William Sealy Gossett) and Welch’s T test, a more advanced T test, are measures of the difference in a statistical sense between two random data sets, such as the outcome of flipping coins one hundred times. The larger the T statistic the more different the two random data sets in a statistical sense.
William Sealy Gossett (Student)
Student’s T test and Welch’s T test convert the T statistics into probabilities that the difference between the two data sets (the “no advertising” and “advertising” sales data in our case) is due to chance. Student’s T test and Welch’s T test are included in Excel and many other financial and statistical programs.
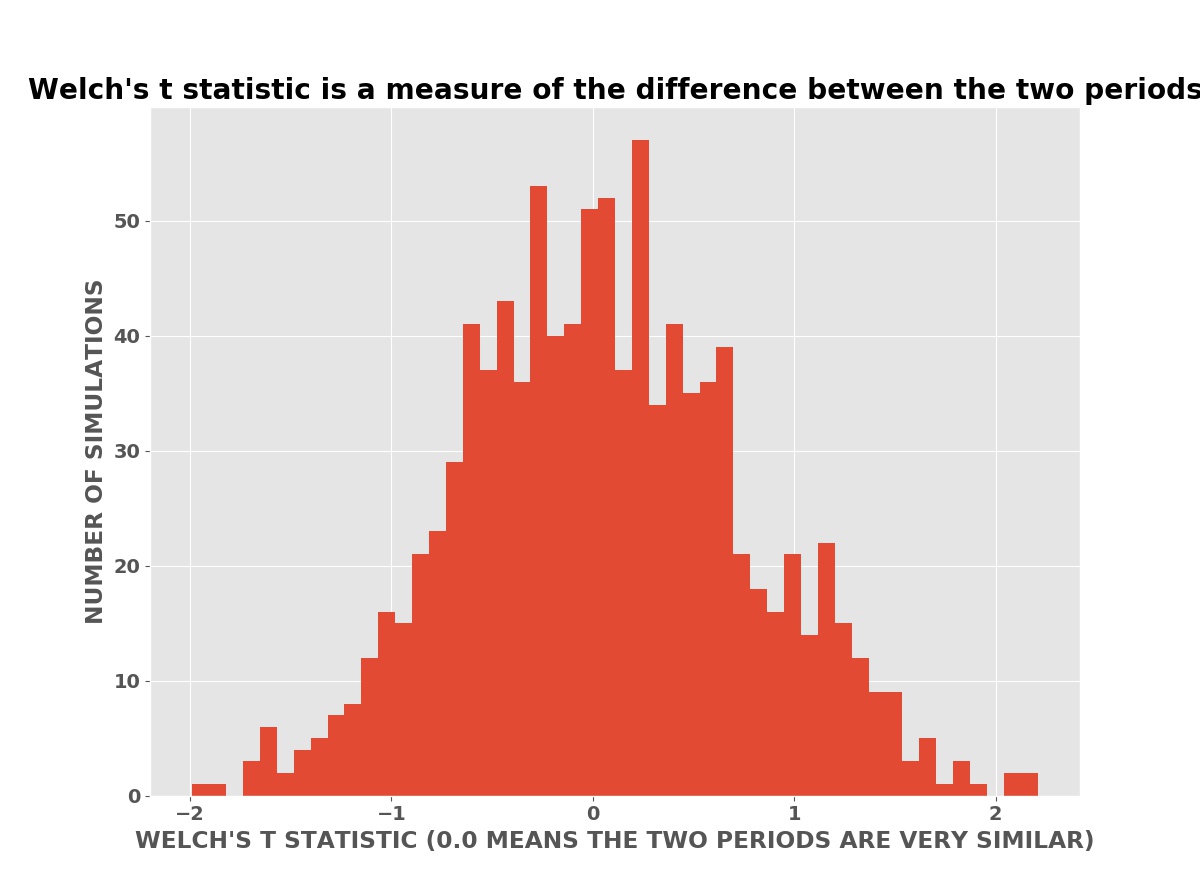
The plot below is a histogram (bar chart) of the number of simulations with a Welch’s T statistic value. In these simulations, the advertising has no effect on the daily sales (or profits). The advertising has no effect is the null hypothesis in the language of classical statistics.
Welch’s T Statistics
Welch was able to derive a mathematical formula for the expected distribution — shape of this histogram — using calculus. The mathematical formula could then be evaluated quickly with pencil and paper or an adding machine, the best available technology of his time (the 1940’s).
To derive his formula using calculus, Welch had to assume that the data had a Bell Curve (Normal or Gaussian) distribution. This is at best only approximately true for the sales data above. The distribution of daily sales in the simulated data is actually the Poisson distribution. The Poisson distribution is a better model of sales data and approximates the Bell Curve as the number of sales gets larger. This is why Welch’s T test is often approximately valid for sales data.
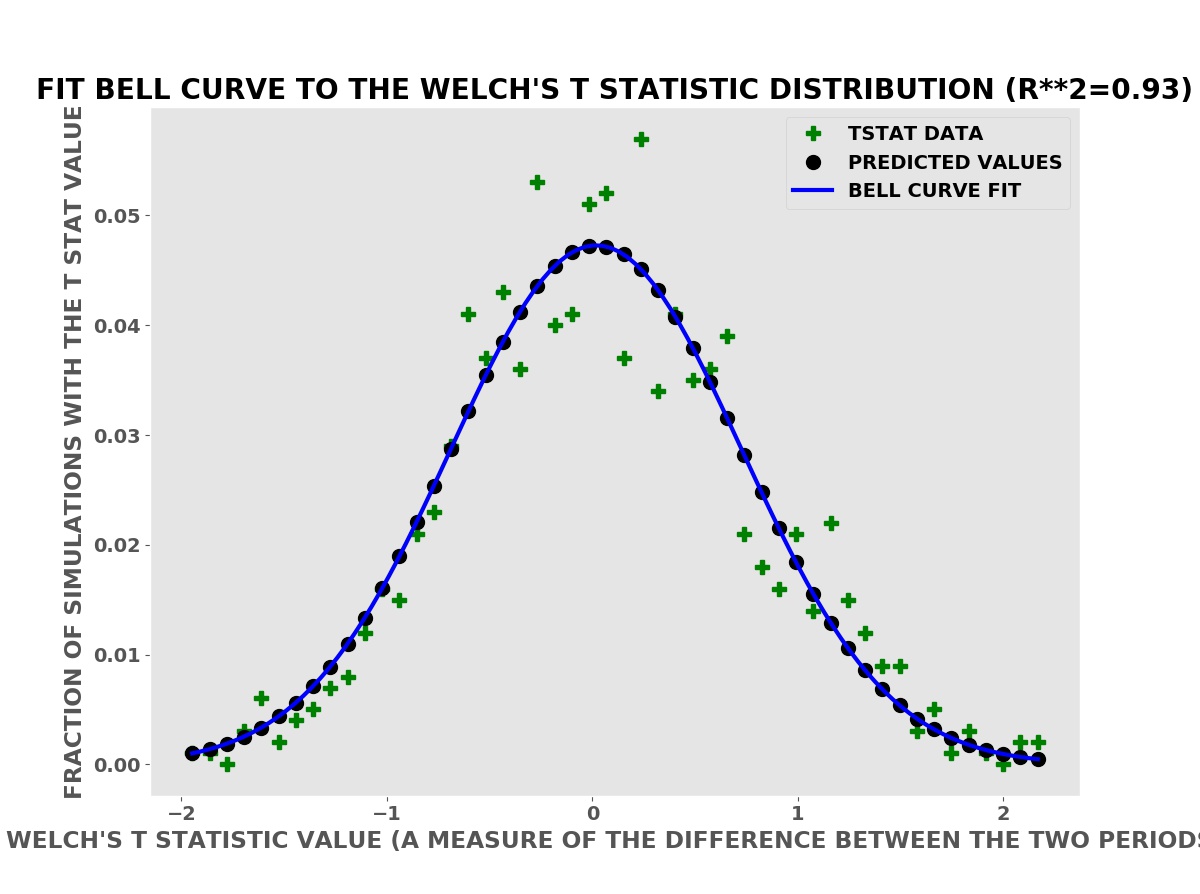
Many methods and tests in classical statistics assume a Bell Curve (Normal or Gaussian) distribution and are often approximately correct for real data that is not Bell Curve data. We can compute better, more reliable results with computer simulations using the actual or empirical probability distributions — shown below.
Welch’s T Statistic has Bell Curve Shape
More precisely, naming one data set the reference data and the other data set the test data, the T test computes the probability that the test data is due to a chance variation in the process that produced the reference data set. In the advertising example above, the “no advertising” period sales data is the reference data and the “advertising” sales data is the test data. Roughly this probability is the fraction of simulations in the Welch’s T statistic histogram that have a T statistic larger (or smaller for a negative T statistic) than the measured T statistic for the actual data. This probability is known as a p-value, a widely used statistic pioneered by Ronald Fisher.
Ronald Aylmer Fisher at the start of his career
The p-value has some obvious drawbacks for a business evaluating the effectiveness of advertising. At best it only tells us the probability that the advertising boosted sales or profits, not how large the boost was nor the risks. Even if on average the advertising boosts sales, what is the risk the advertising will fail or the sales increase will be too small to recover the cost of the advertising?
Fisher worked for Rothamsted Experimental Station in the United Kingdom where he wanted to know whether new breeds of crops, fertilizers, or other new agricultural methods increased yields. His friend and colleague Gossett worked for the Guinness beer company where he was working on improving yields and quality of beer. In both cases, they wanted to know whether a change in the process had a positive effect, not the size of the effect. Without modern computers — using only pencil and paper and adding machines — it was not practical to perform simulations as we can easily today.
Welch’s T statistic has a value of -3.28 for the above sales data. This is in fact lower than nearly all the simulations in the histogram. It is very unlikely the boost in sales is due to chance. The p-value from Welch’s T test for the advertising data above — computed using Welch’s mathematical formula — is only 0.001 (one tenth of one percent). Thus it is very likely the boost in sales is caused by the advertising and not random chance. Note that this does not tell us if the size of the boost, whether the advertising is cost effective, or the risk of the investment.
Sales and Profit Projections Using Computer Simulations
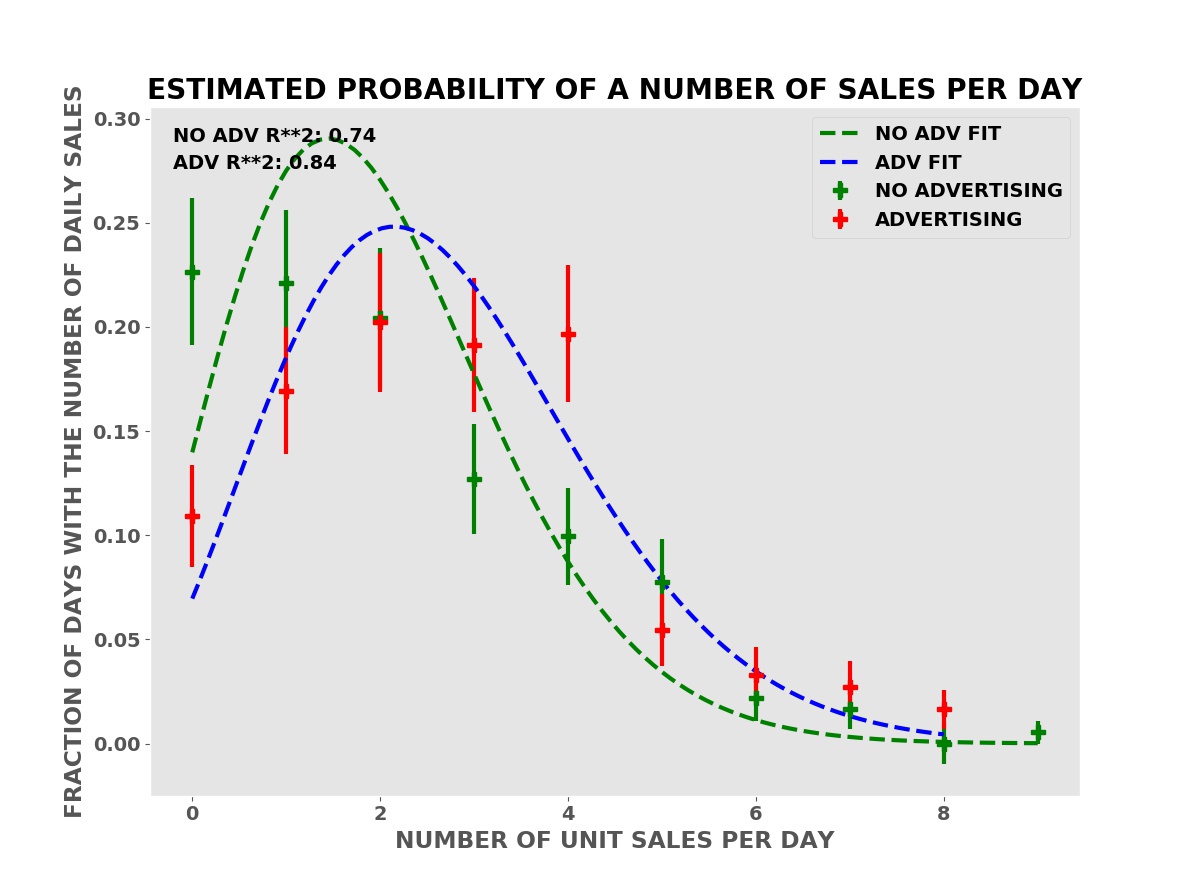
We can do much better than Student’s T test and Welch’s T test by using computer simulations based on the empirical probabilities of sales from the reference data — the “no advertising” period sales data. The simulations use random number generators to simulate the random nature of individual sales.
In these simulations, we simulate one year of business operations with advertising many times — one-thousand in the examples shown — using the frequency of sales from the period with advertising. We also simulate one year of business operations without the advertising, using the frequency of sales from the period without advertising in the sales data.
Frequency of Daily Sales in Both Periods
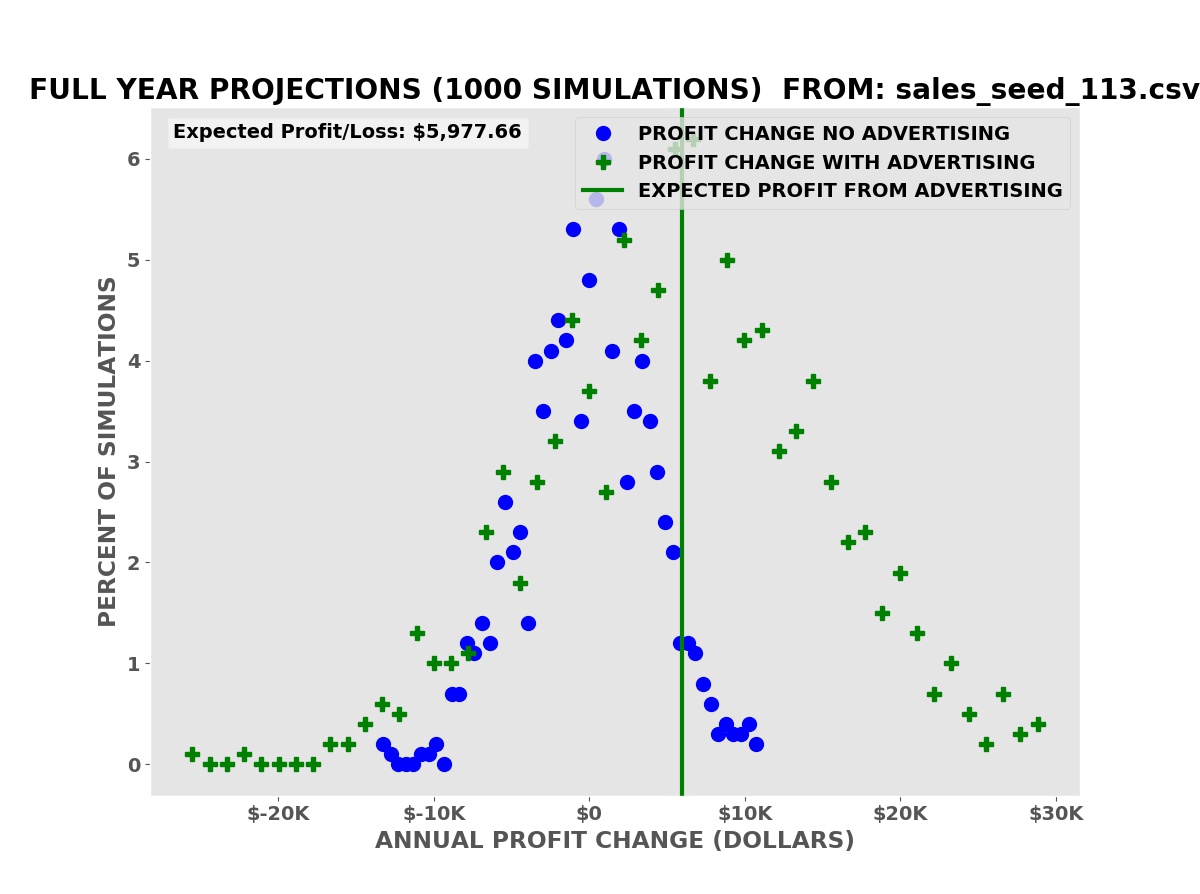
We compute the annual change in the profit relative to the corresponding period — with or without advertising — in the sales data for each simulated year of business operations.
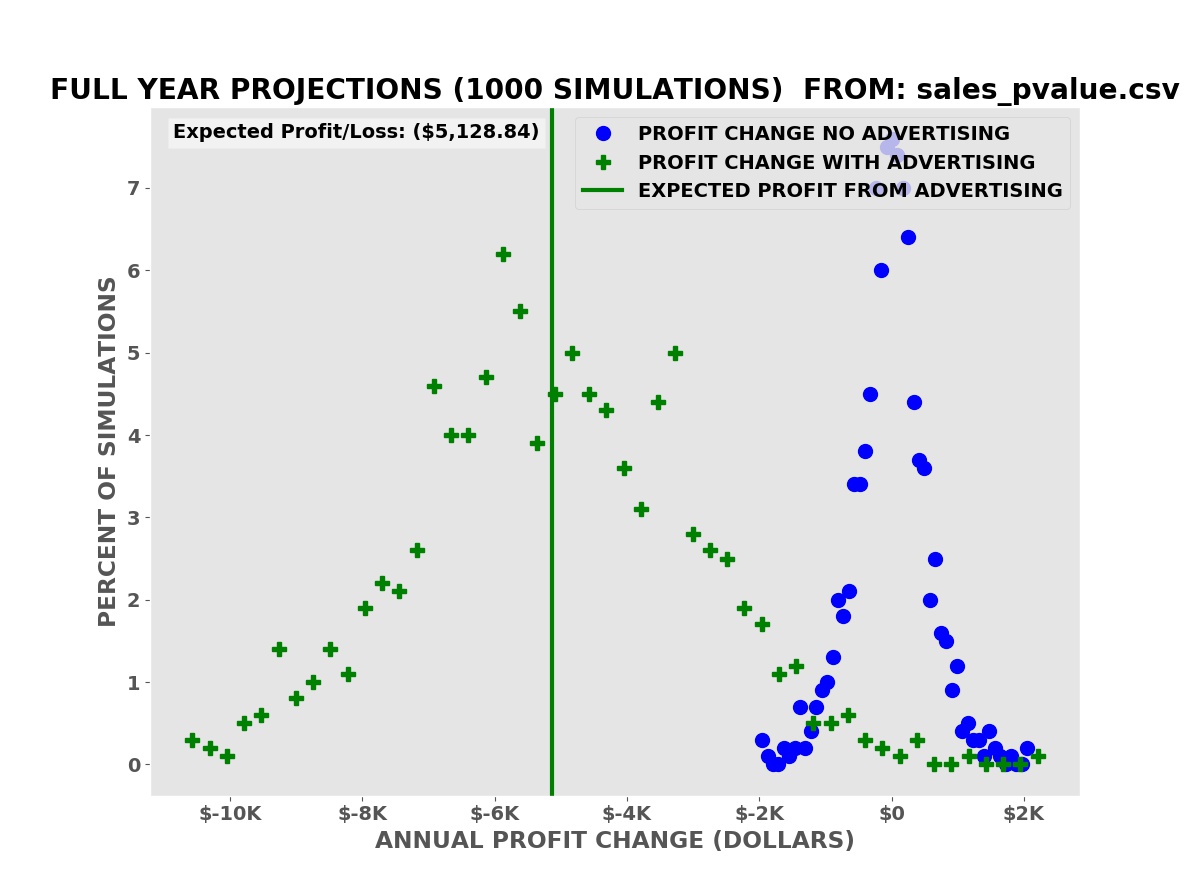
Annual Profit Projections
The simulations show that we have an average expected increase in profit of $5,977.66 over one year (our annual advertising cost is $6,000.00). It also shows that despite this there is a risk of a decrease in profits, some greater than the possible decreases with no advertising.
A business needs to know both the risks — how much money might be lost in a worst case — and the rewards — the average and best possible returns on the advertising investment.
Since sales are a random process like flipping a coin or throwing dice, there is a risk of a decline in profits or actual losses without the advertising. The question is whether the risk with advertising is greater, smaller, or the same. This is known as differential risk.
The Problem with p-values
This is a concrete example of the problem with p-values for evaluating the effectiveness of advertising. In this case, the advertising increases the average daily sales from 100 units per day to 101 units per day. Each unit costs one dollar (a candy bar for example).
P-VALUE SHOWS BOOST IN SALES
The p-value from Welch’s T test is 0.007 (seven tenths of one percent). The advertising is almost certainly effective but the boost in sales is much less than the cost of the advertising:
Profit Projections
The average expected decline in profits over the simulations is $5,128.84.
The p-value is not a good estimate of the potential risks and rewards of investing in advertising. Sales and profit projections from computer simulations based on a mathematical model derived from the reference sales data are a better (not perfect) estimate of the risks and rewards.
Multidimensional Sales Data
The above examples are simple cases where the only change is the addition of the advertising. There are no price changes, other advertising or marketing expenses, or other changes in business or economic conditions. There are no seasonal effects in the sales.
Student’s T test, Welch’s T test, and many other statistical tests are designed and valid only for simple controlled cases such as this where there is only one change between the reference and test data. These tests were well suited to data collected at the Rothamsted Experimental Station, Guinness breweries, and similar operations.
Modern businesses purchasing advertising from Facebook, other social media services, and modern media providers (e.g. the New York Times) face more complex conditions with many possible input variables (unit price, weather, unemployment rate, multiple advertising services, etc.) changing frequently or continuously.
For these, financial analysts need to extract predictive multidimensional mathematical models from the data and then perform similar simulations to evaluate the effect of advertising on sales and profits.
AdEvaluator™ is designed for cases with a single product or service with a constant unit price during both periods. AdEvaluator™ needs a reference period without the new advertising and a test period with the new advertising campaign. The new advertising campaign should be the only significant change between the two periods. AdEvaluator™ also assumes that the probability of the daily sales is independent and identically distributed during each period. This is not true in all cases. Exercise your professional business judgement whether the results of the simulations are applicable to your business.
This program comes with ABSOLUTELY NO WARRANTY; for details use -license option at the command line or select Help | License… in the graphical user interface (GUI). This is free software, and you are welcome to redistribute it under certain conditions.
We are developing a professional version of AdEvaluator™ for multidimensional cases. This version uses our Math Recognition™ technology to automatically identify good multidimensional mathematical models.
The Math Recognition™ technology is applicable to many types of data, not just sales and advertising data. It can for example be applied to complex biological systems such as the blood coagulation system which causes heart attacks and strokes when it fails. According the US Centers for Disease Control (CDC) about 633,000 people died from heart attacks and 140,000 from strokes in 2016.
Conclusion
It is often difficult to evaluate whether advertising is boosting sales and profits, despite the ready availability of sales and profit data for most businesses. This is caused by the unpredictable nature of individual sales and frequently by the complex multidimensional business environment where price changes, economic downturns and upturns, the weather, and other factors combine with the advertising to produce a confusing picture.
In simple cases with a single change, the addition of the new advertising, Student’s T test, Welch’s T test and other methods from classical statistics can help evaluate the effect of the advertising on sales and profits. These statistical tests can detect an effect but provide no clear estimate of the magnitude of the effect on sales and profits and the financial risks and rewards.
Sales and profit projections based on computer simulations using the empirical probability of sales from the actual sales data can provide quantitative estimates of the effect on sales and profits, including estimates of the financial risks (chance of losing money) and the financial rewards (typical and best case profits).
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
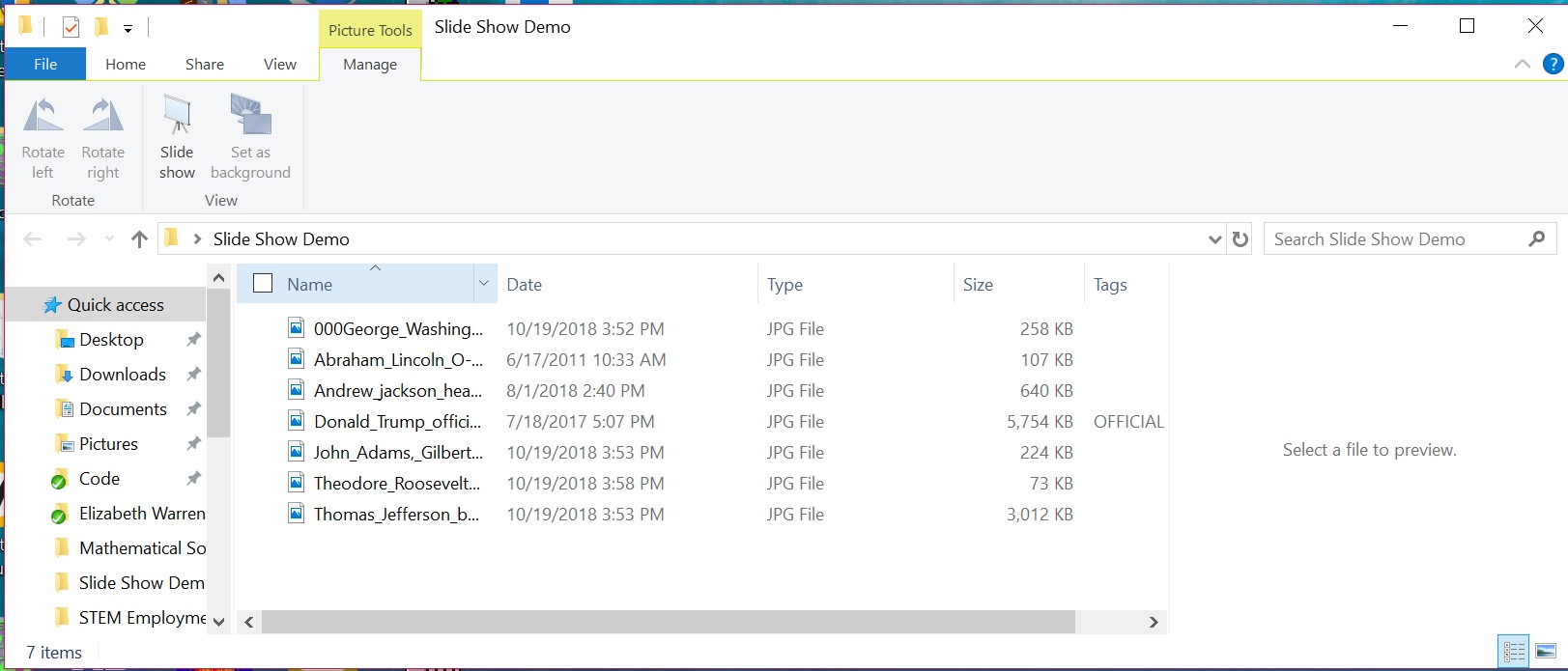
This is a short article on how to control the order of slides in a slideshow on the Microsoft Windows 10 operating system. Slideshows can be quickly launched in Windows 10 using the Windows File Explorer by selecting the Manage tab and clicking on the Slideshow Icon.
Slide show icon in File Explorer
Usually, Windows 10 will display the picture files in the folder in the order displayed in the file explorer: alphabetically if Name is selected, by date if Date is selected, by file size if Size is selected, etc. In my experience on my system, this occasionally does not happen and the files are displayed alphabetically even though another view is selected. Thus, it is probably best to use alphabetical file names to ensure that the files display as desired.
Note that on Windows (and many computer systems) the numbers 0-9 come before A-Z, thus files that start with a number such as 000my_file_name.jpg will display before files that start with a letter such as my_file_name.jpg. In the example below, I use the prefix 000 to display the picture of George Washington first.
Alphabetical View in File Explorer
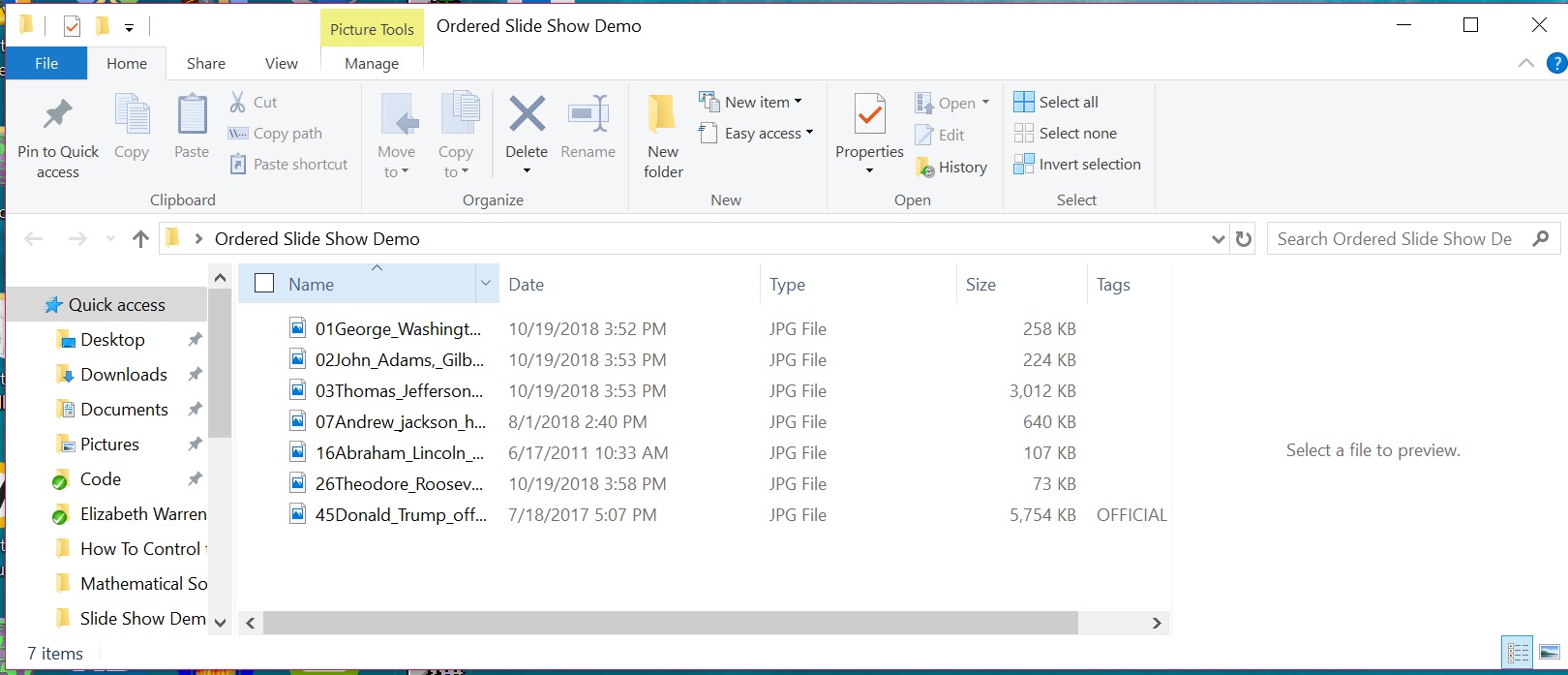
To display the Presidents in chronological order, I add a numeric prefix to each file in the folder. George Washington is the first President of the United States. John Adams is the second. Thomas Jefferson third. Andrew Jackson seventh. Abraham Lincoln sixteenth. Theodore Roosevelt twenty-sixth. Donald Trump forty-fifth.
Slideshow with US Presidents Ordered in Chronological Order
By default, Windows 10 plays the slide show in Loop mode with Shuffle mode off. In this mode, the slides are displayed in order.
Loop Mode Showing George Washington First
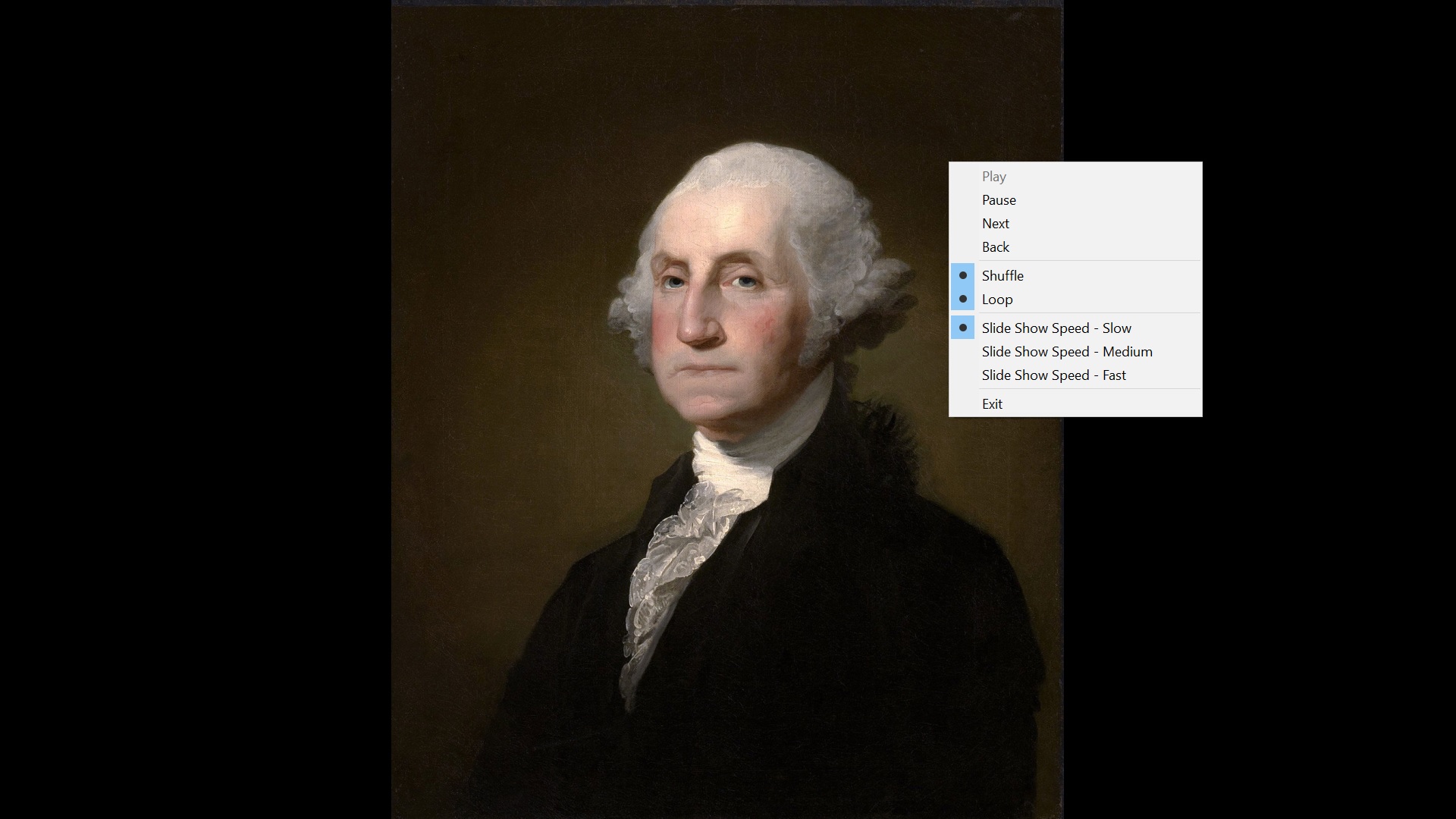
Right clicking with the mouse or other pointing device during the slide show brings up a popup menu with the Loop and Shuffle modes as well as other controls.
In the shuffle mode, the first slide is always displayed first. I will still get George Washington first in my example. All subsequent slides are displayed in random order. This seems like a bug; I would prefer the first slide to also be random.
Shuffle Mode Showing George Washington First
NOTE: If for some reason you do not like the first slide displayed every time in shuffle mode, add a prefix to a picture file that you would prefer to be first to place it alphabetically before all other picture files in the folder.
Once shuffle mode or other controls (slow or fast for example) are selected, the selections remain in force for subsequent slide shows until changed.
That is how to control the order of slides in a slide show in Microsoft Windows 10.
This is a short video on how to control the order of slides in a slide show on Windows 10:
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).