Is that COVID-19 model true? An intro to quantitative falsifiability metrics for confirming the safety and effectiveness of drugs and medical treatments, the reliability of mathematical models used in complex derivative securities and other practical applications. It starts with a discussion of the myth of falsifiability, a commonly cited doctrine often used to exclude certain points of view and evidence from consideration as “not scientific”. It discusses the glaring problems with the popular versions of this doctrine and the lack of a rigorous quantitative formulation of a more nuanced concept of falsifiability as originally proposed, but not developed, by the philosopher Karl Popper. The video concludes with a brief accessible presentation of our work on rigorous quantitative falsifiability metrics for practical science and engineering.
It is generally faster to read the article than watch the video.
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
As of March 21, 2020, the United States Centers for Disease Control (CDC) has posted weekly death numbers for pneumonia and influenza (P&I) that are substantially lower than the weekly death numbers for the matching weeks last year (2019) despite the Coronavirus COVID-19 Pandemic. This is remarkable given that with the lack of widespread testing many deaths caused by the pandemic would be expected to appear as a surge in deaths attributed to pneumonia and influenza. One can also argue that deaths caused by COVID-19, where known, should be included in the pneumonia and influenza death tally as well.
NOTE: The latest numbers, through the week ending March 21, 2020, were posted last Friday, April 3, 2020.
The weekly numbers for 2017 and previous years also sum to a total number of annual deaths due to pneumonia and influenza that is about three times larger than the widely quoted numbers from the 2017 and earlier leading causes of death reports.
I have done a number of video posts on the seeming absence of COVID-19 from reports through March 21, 2020. Remarkably the latest raw (?) data file NCHSData13.csv from https://www.cdc.gov/flu/weekly/#S2 (click on View Chart Data below the plot) shows total 40,002 deaths in week 12 of 2020 and 57,086 total deaths in week 12 of 2019 (see screenshot below) — much lower in 2020 despite the pandemic. The file shows total pneumonia and influenza deaths of 3,261 in week 12 of 2020 and 4,276 deaths in week 12 of 2019 (last year). Again many more deaths last year.
CDC Pneumonia and Influenza Deaths File NCHSData13.csv
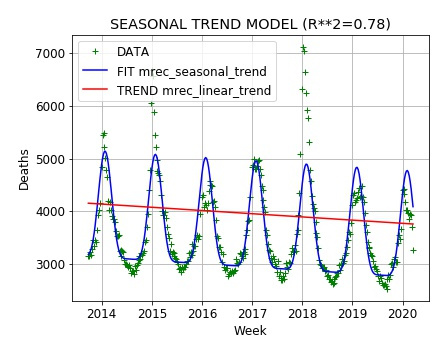
Remarkably the weekly death numbers attributed to pneumonia and influenza have been running below last year’s numbers for the same weeks for almost all weeks since the beginning of 2020 and well below what might be expected from simple modeling of the long term trend and seasonal variation.
In the plot below, the green plus signs are the data from the NCHSData13.csv file. The red line is the long term trend and the blue line if the full model with a roughly sinusoidal model of the seasonal variation in deaths added. One can see that the weekly death numbers are lower this year than last year and also fall well below the model prediction.
US Centers for Disease Control (CDC) Weekly Deaths from Pneumonia and Influenza (to March 21, 2020)
There are many possible explanations for this remarkable shortfall in deaths. No doubt the CDC is fielding hard questions from web site visitors, analysts, and others. Fox News host Tucker Carlson included the discrepancy in his commentary on the COVID-19 crisis on April 7 (from 3:24 to 3:50 in the linked video):
Tucker Carlson Highlights the CDC P and I Deaths Anomaly
The CDC appears to have updated its FluView web site with information on how complete the numbers for the last three weeks are — how many death certificates have been collected. They appear to have added a table at the bottom with the weekly numbers:
CDC FluView Table on Pneumonia and Influenza Deaths (AT BOTTOM)
The final right-most column labeled “Percent Complete” seems to refer to how complete the numbers are, although this is not clear. Hovering the mouse pointer over the question mark to the right of “Percent Complete” brings up a legal disclaimer and not a clear explanation of what “Percent Complete” means. The final week (week 12, ending March 21, 2020) is listed as 85.4 % complete. Oddly, the previous two weeks (week 10 and week 11) are listed as (> 100 %) complete — note the greater than sign. Since one-hundred percent (100%) means COMPLETE, it is especially difficult to understand the use of the greater than sign > in the table. 🙂
In the FluView application/web page (today, April 9, 2020) the CDC seems to be claiming the numbers up to week 11 ending March 14, 2020 are in fact complete. The remarkable absence of COVID-19 deaths up to March 14, 2020 cannot be attributed to delays in collecting and processing death certificates or reports. A number of legal disclaimers such as the popup shown seem to have appeared recently (last few days) on the CDC web site.
As I have noted there are many possible explanations for this remarkable reported decline in deaths during a purported pandemic. It may be that people have been extra careful during the pandemic, staying home, avoiding risky behaviors, thus resulting in a drop in deaths both in general and from pneumonia and influenza causes other than COVID-19. It could be there are errors or omissions caused by the crisis response that are making the numbers unreliable. It could be pneumonia and influenza deaths from other causes are being incorrectly labeled as COVID-19 and omitted from the numbers; this is why it would be best to include COVID-19 as part of the P&I deaths. It could be that COVID-19, despite the headlines, is not unusually deadly.
NOTE: Total deaths in Europe have risen sharply in the latest weekly numbers from EuropMOMO, consistent with an unusually deadly new cause of death, after many weeks of remarkably showing no sign of the COVID-19 pandemic.
The CDC Weekly Pneumonia and Influenza Death Numbers are Three Times the Widely Reported Annual Death Numbers
Astonishingly the weekly death numbers in the NCHSData13.csv file — which go back to 2013 as shown in the plot above — indicate that about three times as many people in the United States have died from pneumonia and influenza in 2017 and preceding years as reported in the National Vital Statistics.
For example, the National Vital Statistics Report Volume 69, Number 8 dated June 24, 2019: “Deaths: Final Data for 2017” gives 55,672 deaths from “Influenza and pneumonia” in its table (Table B) of leading causes of deaths. “Influenza and pneumonia” is the eighth leading cause of death in 2017.
Death: Final Data for 2017Leading Causes of Death Table (2017)
Note that the report uses the phrase “Influenza and pneumonia” whereas the weekly death web site uses the language “Pneumonia and influenza (P&I)”. As I will explain below this may be a clue to the reason for the huge discrepancy.
In contrast, summing the weekly death numbers for 2017 in NCHSData13.csv gives 188,286 deaths for the entire year. This is OVER three times the number in the “Deaths: Final Data for 2017” (June 24, 2019).
It is worth noting that the web site, the NCHSData13.csv file, and the report appear intended for the general public, in part for educational and informational purposes — as well as doctors and other professionals who have limited time to dig into the numbers. Most people would interpret deaths due to “Influenza and pneumonia” in one report as the same or nearly the same (except for minor technical issues) number as “Pneumonia and influenza” in another report, data file, or web site.
What gives?
In 2005, Peter Doshi, an associate editor with the British Medical Journal (BMJ), one of the most prestigious medical journals in the world, wrote a highly critical, though short, article on the CDC’s pneumonia and influenza numbers: “Are US flu death figures more PR than science?”
BMJ. 2005 Dec 10; 331(7529): 1412. PMCID: PMC1309667
US data on influenza deaths are a mess. The Centers for Disease Control and Prevention (CDC) acknowledges a difference between flu death and flu associated death yet uses the terms interchangeably. Additionally, there are significant statistical incompatibilities between official estimates and national vital statistics data. Compounding these problems is a marketing of fear—a CDC communications strategy in which medical experts “predict dire outcomes” during flu seasons.
The CDC website states what has become commonly accepted and widely reported in the lay and scientific press: annually “about 36 000 [Americans] die from flu” (www.cdc.gov/flu/about/disease.htm) and “influenza/pneumonia” is the seventh leading cause of death in the United States (www.cdc.gov/nchs/fastats/lcod.htm). But why are flu and pneumonia bundled together? Is the relationship so strong or unique to warrant characterising them as a single cause of death?
BMJ. 2005 Dec 10; 331(7529): 1412. PMCID: PMC1309667
Peter Doshi goes on in this vein for a couple of pages (see the linked article above). Peter Doshi and other sources online seem to suggest that CDC estimates a large number of pneumonia deaths that are attributed to secondary effects of influenza such as a bacterial pneumonia infection caused by influenza. Influenza is rarely detected in actual tests of actual patients and only a small fraction of deaths reported in the weekly statistics are attributed in NCHSData13.csv to influenza (the virus, NOT “flu” as used in popular language which can mean any disease with similar symptoms to influenza — the scientific term).
The influenza and pneumonia deaths number in the National Vital Statistics Report may be this estimate that Doshi is describing in his critical article in the BMJ. The other (many more!) weekly “pneumonia and influenza” deaths presumably are assigned to some other categories in the annual leading causes of death report.
Presumably CDC can give some explanation for this vast discrepancy between two numbers that most of us would expect to be the same. “Influenza and pneumonia” and “pneumonia and influenza” mean the same thing in common English usage. They almost certainly mean the same thing to most doctors and other health professionals as well.
Conclusion
These pneumonia and influenza death numbers need to be clarified in an open and transparent manner. The next set of numbers will probably be posted tomorrow Friday April 10, 2020. Hopefully these new numbers and accompanying commentary will explain the situation in an open and transparent manner that survives critical scrutiny.
The proper response to the COVID-19 pandemic depends on knowing a range of parameters including the actual mortality rate broken down by age, sex, race, obesity, other medical conditions, whatever can be measured quickly and accurately. The actual rates and modes of transmission. The false positive and false negative rates for the various tests, both for active infection and past infection. These are mostly not known.
Most of us are experiencing the instinctive fight or flight response which degrades higher cognitive function, aggravated by the 24/7 Internet/social media fear barrage. It is important to calm down, collect actual data in a genuinely open, transparent way that will yield broad public support, and think carefully.
UPDATE (February 13, 2021):
We have received some questions about more up to date information on the issues raised in this article. Our most recent and comprehensive article on the CDC’s historical influenza and pneumonia death numbers and their current COVID-19 death numbers is:
This article argues that the US Centers for Disease Control (CDC)’s April 2020 guidance for filling out death certificates for possible COVID-19 related deaths strongly encourages, if not requires, assigning COVID-19 as the underlying cause of death (UCOD) in any death where COVID-19 or the SARS-COV-2 virus may be present, which appears to differ from common historical practice for pneumonia and influenza deaths where pneumonia was frequently treated as a “complication,” a cause of death but not the underlying cause of death.
This means the number of COVID deaths should be compared to a count of death certificates where pneumonia and influenza were listed as a cause of death or even a lesser contributing factor, a historical number which appears to have been at least 188,000 per year based on the CDC FluView web site. The proper comparison number may be even larger if deaths that historically were listed as heart attacks, cancer or other causes than pneumonia or influenza are also being reassigned due to the April 2020 guidance.
Here are some earlier articles and references:
This is a more recent article/video on the long standing problems with the pneumonia and influenza death numbers:
“How Reliable are the US Centers for Disease Control’s Death Numbers” (October 14, 2020)
The second article on the Santa Clara County death numbers includes a detailed section on the changes in the standard on assigning the underlying cause of death for COVID cases from the CDC’s April 2020 “guidance” document, which probably boost the COVID death numbers substantially. This section is broken out and edited into this article:
We are looking at the CDC’s excess death numbers which appear to be highly questionable. The CDC follows a non-standard procedure of zeroing out data points that are negative in summing the excess deaths. See this article by Tam Hunt:
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
An analysis of the latest weekly death numbers from the Centers for Disease Control (CDC) and the National Center for Health Statistics (NCHS) from the week ending March 21, 2020 and posted on the CDC Web Site on Friday, April 3, 2020
Doomsday Virus? Coronavirus cases are NOT boosting the weekly death numbers for pneumonia and influenza from the CDC and National Center for Health Statistics yet. This would be expected if the coronavirus (SARS-Cov-2) is unusually deadly compared to other diseases that contribute to deaths categorized as pneumonia and influenza… YET! (Based on data through March 21, 2020)
CDC Pneumonia and Influenza Mortality Surveillance: https://www.cdc.gov/flu/weekly/#S2
Credit: Pete Linforth by way of Pixabay for the background image of the coronavirus.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Luxury apartment construction in Palo Alto, CA (Santa Clara County, Silicon Valley) continues despite the Coronavirus (COVID-19) pandemic and a revised shelter-in-place order that appears to explicitly exclude almost all construction issued on March 31, 2020. It is difficult to understand why these projects were ever allowed to continue nor why some appear to be continuing after the new revised order if authorities genuinely believe COVID-19 is much more deadly than the common colds and flus that cause about 55,000 deaths per year in the United States.
Links: Perspectives on the Pandemic | Dr John Ioannidis of Stanford University | Interview:
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Doomsday Virus? Coronavirus Cases NOT Boosting Weekly Death Numbers…YET
Doomsday Virus? Coronavirus cases are NOT boosting the weekly death numbers for pneumonia and influenza from the CDC and National Center for Health Statistics yet. This would be expected if the coronavirus is unusually deadly compared to other diseases that contribute to deaths categorized as pneumonia and influenza… YET! (Based on data through March 14, 2020)
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Super Flu? Are Coronavirus Cases Increasing Weekly Death Numbers?
This video reviews weekly death figures for pneumonia and influenza from the National Center for Health Statistics to see if the coronavirus is increasing weekly deaths as expected if coronavirus is unusually deadly.
Support Us: PATREON: https://www.patreon.com/user?u=28764298
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This is a short video about current coronavirus (COVID-19) United States death numbers on March 17, 2020 compared to expected deaths from similar diseases usually categorized as influenza and pneumonia.
Credit: Pete Linforth by way of Pixabay for the background image of the coronavirus. https://pixabay.com/illustrations/coronavirus-corona-virus-covid-19-4833754/
Support Us: PATREON: https://www.patreon.com/user?u=28764298
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Vioxx: The Case of the Deadly Data Analysis (Video)
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
All About the Mysterious Death of Astronomer Tycho Brahe
(C) 2020 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This video argues that the Manhattan Project which developed the first atomic bombs and nuclear reactors during World War II was a fluke, not representative of what can be accomplished with Big Science programs. There have been many failed New Manhattan Projects since World War II.
Minor Correction: Trinity, the first atomic bomb test, took place on July 16, 1945 — not in May of 1945 as stated in the audio.
(C) 2019 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).