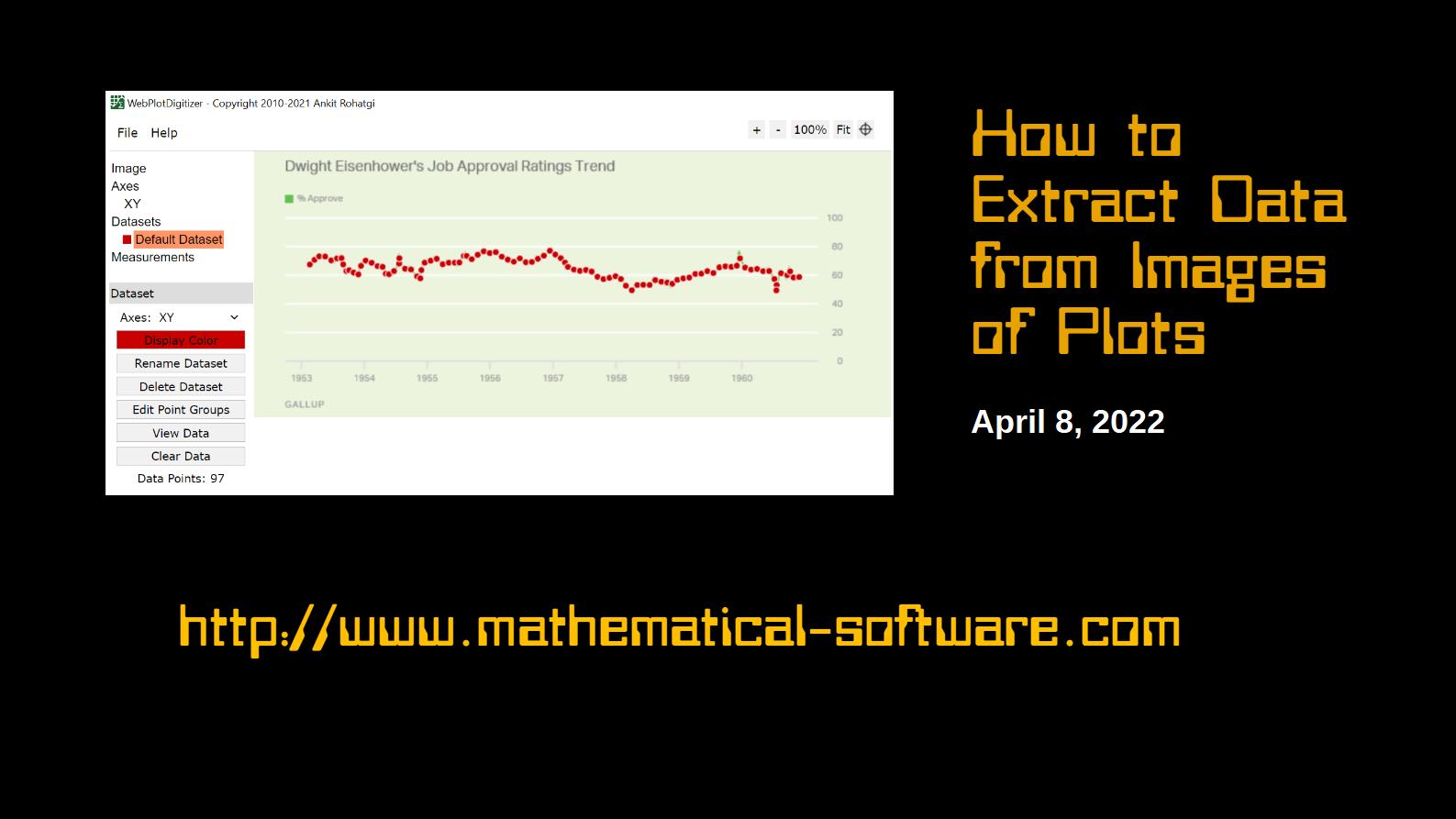
Short video on how to extract data from images of plots using WebPlotDigitizer, a free, open-source program available for Windows, Mac OS X, and Linux platforms.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
A brief introduction to the math recognition problem and automatic math recognition using modern artificial intelligence and pattern recognition methods. Includes a call for data. About 14 minutes.
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I attended a “Machine Learning at Google” event at the Google Quad 3 building off Ellis in Mountain View last night (August 23, 2017). This seemed to be mostly a recruiting event for some or all of Google’s high profile Machine Learning/Deep Learning groups, notably the team responsible for TensorFlow.
Woman Opens Event
I had no trouble finding the registration table when I arrived and getting my badge. All the presentations seemed to run on time or nearly on time. There was free food, a cute bag with Google gewgaws, and plenty of seating (about 280 seats with attendance about 240 I thought).
The event invitation that I received was rather vague and it did not become clear this was a recruiting event until well into the event. It had the alluring title:
An Exclusive Invite | Machine Learning @ Google
Ooh, exclusive! Aren’t I special! Along with 240 other attendees as it turned out. 🙂
Andrew Zaldivar (see below) explicitly called it a recruiting event in the Q&A panel at the end. It would have been good to know this as I am not looking for a job at Google. That does not mean the event wasn’t interesting to me for other reasons, but Google and other companies should be up front about this.
Although I think the speakers were on a low platform, they weren’t up high enough to see that well, even though I was in the front. This was particularly true of Jasmine Hsu who was short. I managed to get one picture of her not fully or mostly obscured by someone’s head. Probably a higher platform for the presenters would have helped.
A good looking woman who seemed to be some sort of public relations or marketing person opened the event at 6:30 PM. She went through all the usual event housekeeping and played a slick Madison Avenue style video on the coming wonders of machine learning. Then she introduced the keynote speaker Ravi Kumar.
Ravi Kumar Keynote
Ravi was followed by a series of “lightning talks” on machine learning and deep learning at Google by Sandeep Tata, Heng-Tze Cheng, Ian Goodfellow, James Kunz, Jasmine Hsu, and Andrew Zaldivar.
The presentations tended to blur together. The typical machine learning/deep learning presentation is an extremely complex model that has been fitted to a very large data set. Giant companies like Google and Facebook have huge proprietary data sets that few others can match. The presenters tend to be very confident and assert major advances over past methods and often to match or exceed human performance. It is often impossible to evaluate these claims without access to both the huge data sets and vast computing power. People who try to duplicate the reported dramatic results with more modest resources often report failure.
The presentations often avoid the goodness-of-fit statistics, robustness, and overfitting issues that experts in mathematical modeling worry about with such complex models. A very complex model such as a polynomial with thousands of terms can always fit a data set but it will usually fail to extrapolate outside the data set correctly. Polynomials, for example, always blow up to plus or minus infinity as the largest power term dominates.
In fact one Google presenter mentioned a “training-server skew” problem where the field data would frequently fail to match the training data used for the model. If I understood his comments, this seemed to occur almost every time supposedly for different reasons for each model. This sounded a lot like the frequent failure of complex models to extrapolate to new data correctly.
Ravi Kumar’s keynote presentation appeared to be a maximum likelihood estimation (MLE) of a complex model of repeat consumption by users: how often, for example, a user will replay the same song or YouTube video. MLE is not a robust estimation method and it is vulnerable to outliers in the data, almost a given in real data, yet there seemed to be no discussion of this issue in the presentation.
Often when researchers and practitioners from other fields that make heavy use of mathematical modeling such as statistics or physics bring up these issues, the machine learning/deep learning folks either circle the wagons and deny the issues or assert dismissively that they have the issues under control. Move on, nothing to see here.
Sandeep Tata
Hang Tze
Ian Goodfellow on Deep Learning Research at Google
Jasmine Hsu on Robotics and Computer Vision
James Kunz
Andrew Zaldivar on SPAM Fighting with Machine Learning
Andrew Zaldivar introduced the Q&A panel for which he acted as moderator. Instead of having audience members take the microphone and ask their questions uncensored as many events do, he read out questions supposedly submitted by e-mail or social media.
Andrew Zaldivar Introduces the Panel
Q and A Panel
The Q&A panel was followed by a reception from 8-9 PM to “meet the speakers.” It was difficult to see how this would work with about thirty (30) audience members for each presenter. I did not stay for the reception.
Conclusion
I found the presentations interesting but they did not go into most of the deeper technical questions such as goodness-of-fit, robustness, and overfitting that I would have liked to hear. I feel Google should have been clearer about the purpose of the event up front.
(C) 2017 John F. McGowan, Ph.D.
About the author
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).