How to Defeat Internet Censorship with RSS (Independence Day Update)
Updated version of video on using RSS to defeat Internet Censorship for Independence Day (July 4, 2020). Note: Technology demonstration starts at 5:00 (five minutes).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
In this video, I discuss how to defeat soft or stealth censorship of the Internet by giant social media companies such as Facebook, Google/YouTube, Apple, Twitter and the government using the proven, established, widely used free open-source decentralized technology RSS (Rich Site Summary also known as Really Simple Syndication). I demonstrate this using the RSS reader in the free open-source Thunderbird e-mail program available for Microsoft Windows, Mac OS X, and most Linux platforms.
The government has many potential ways to apply pressure on social media companies in the absence of explicit censorship laws:
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Many online web sites and services, including many that have useful information, have become highly distracting and addictive — wasting many hours of precious time and clouding our judgement leading to bad purchases and other critical decisions. This increasing level of distraction is probably due to a combination of increasing integration of persuasive technology and advances in recommendation engines and other algorithms.
I personally have had significant problems with lost time and distractions from YouTube and Hacker News. Both of these sites have useful information as well as large amounts of distracting dreck. I find both addictive. I substantially reduced the amount of time wasted on Hacker News by switching from the web site to the Hacker News RSS feed in my Thunderbird email program.
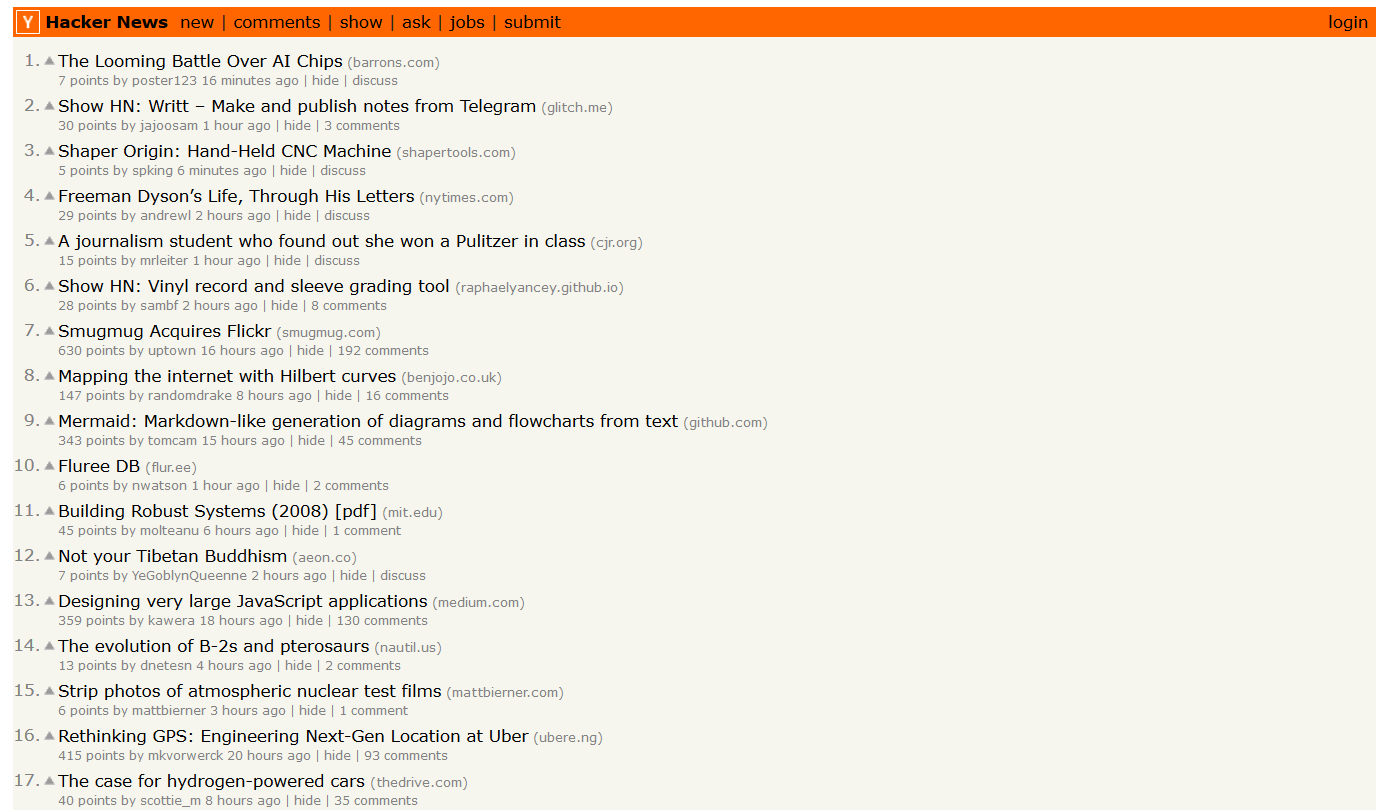
Hacker News Web Site
Below is the Hacker News RSS feed in Thunderbird.
Thunderbird RSS Hacker News Feed
Thunderbird has a feature to subscribe to and manage RSS feeds. As can be seen, I have subscribed to Hacker News and Slashdot. Although Slashdot is similar to Hacker News in a number of respects, I have consistently found Hacker News much more distracting and addictive.
There is also an “End of Month” folder. I have configured message filters in Thunderbird to move important but distracting articles from Hacker News and Slashdot to the “End of Month” folder. This includes for example articles on some political topics that tend to get my blood boiling.
Hacker News has a “social” system of user and article scores, upvotes, downvotes , comments and other decorations. This “socialization” of the new articles seems to be a major factor in why the web site is substantially more addictive and distracting than the RSS feed. In addition, as noted, I am able to filter out articles that tend to distract me, putting them aside for a planned time to deal with distracting topics.
Many web sites have RSS feeds including Hacker News, Slashdot, and Tech Crunch (not shown here). This method can be applied to many distracting web sites to reduce the unwanted distractions and lost time while still keeping up with useful information. Message Filters can be configured to delete dreck, set aside articles on important but distracting topics, and highlight articles of special interest. With message filters, you — the reader/user — are in control instead of mysterious machine learning algorithms and recommendation engines.
How to Set Up RSS in Thunderbird
The Thunderbird web site provides detailed instruction on how to set up a Feed Account and subscribe to RSS feeds here.
Step 1: Create a Feed Account
First you must create an account in Thunderbird for your feeds.
1. In the Menu Bar, click File > New > Feed Account. The Feed Account Wizard window appears.
2. Type a name for your Feed account in the Account Name box, then click Next.
3. Click Finish. Your new account will now appear in Thunderbird’s folder pane.
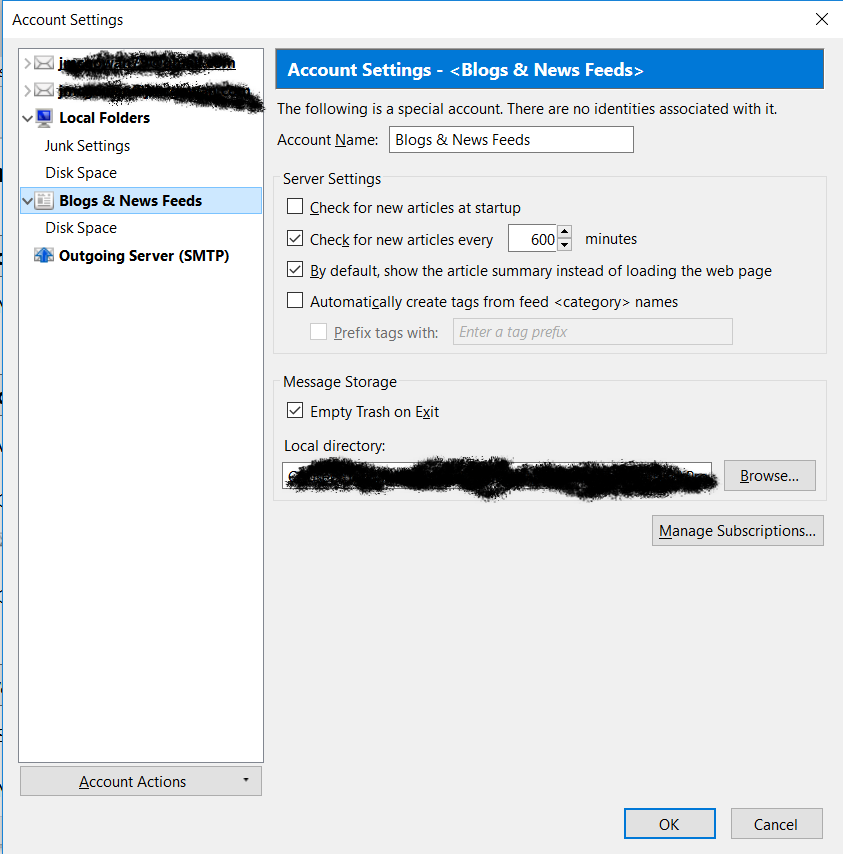
I gave my account the name Blogs and News Feeds:
Thunderbird RSS Blogs and News Feeds Account Example
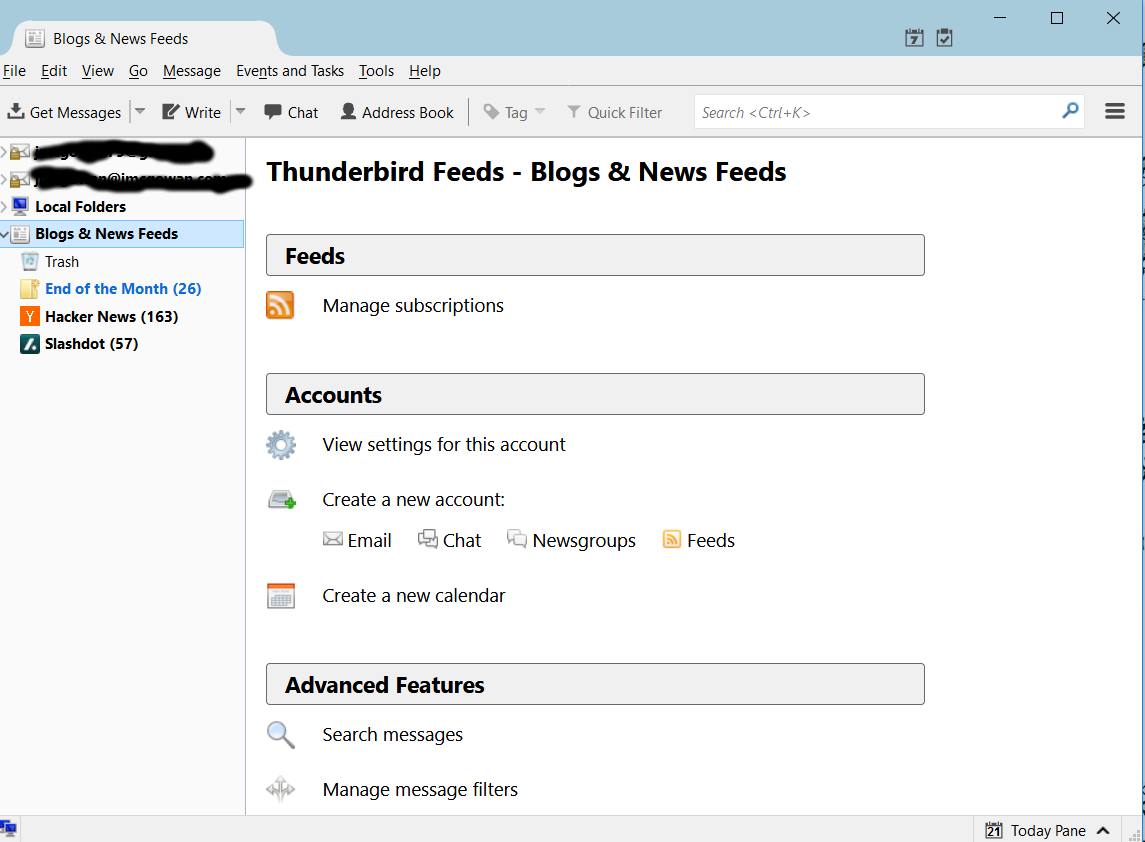
There is a main dashboard for Blogs and News Feeds in Thunderbird:
Thunderbird RSS Dashboard
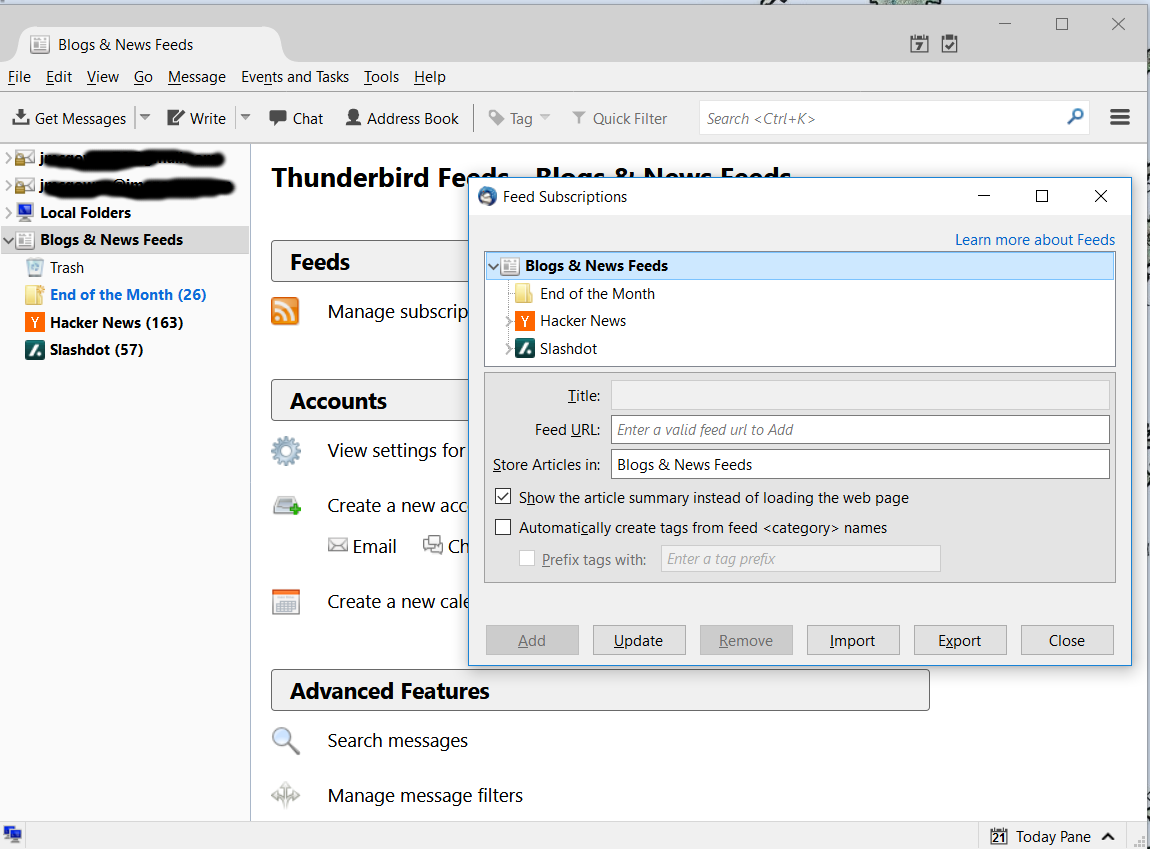
Click on Manage subscriptions to add an RSS feed. You will need the URL for the feed. The picture below shows the feed dialog in Thunderbird.
Thunderbird RSS Feed Dialog
How to set up message filters
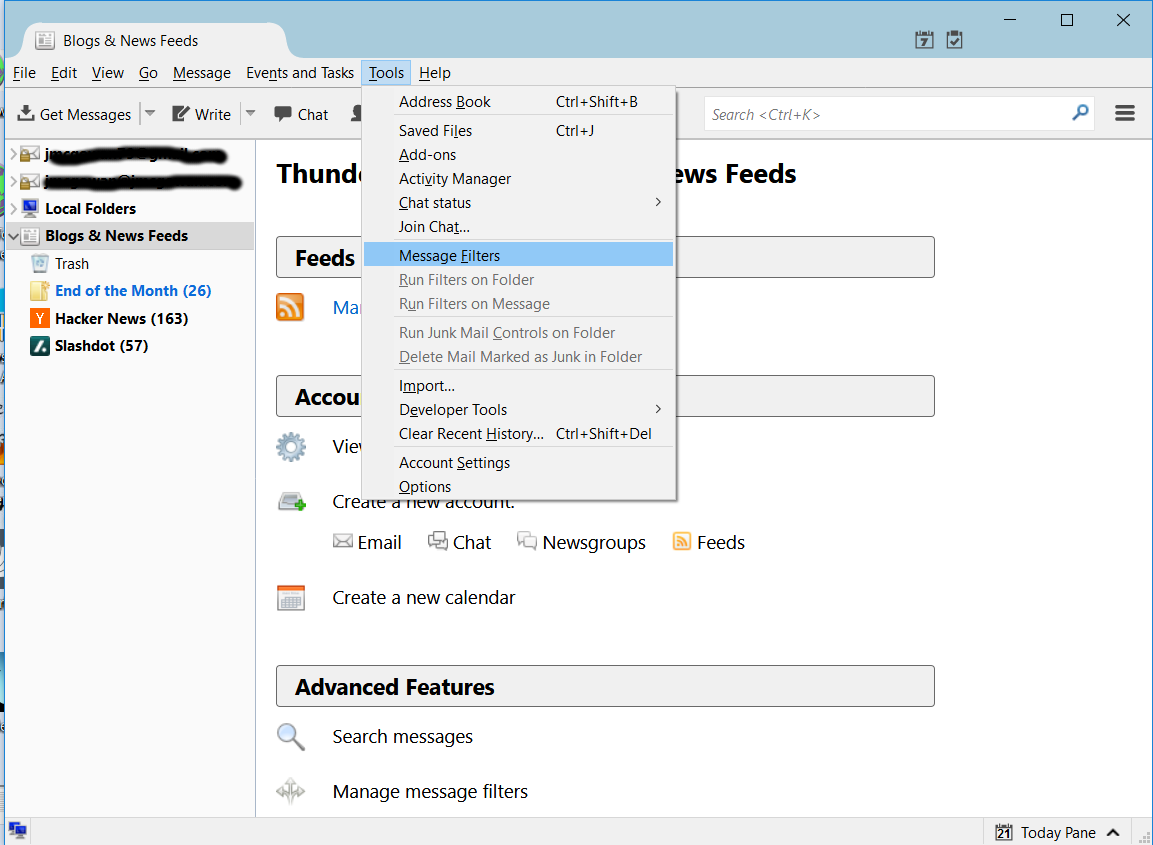
Select the Message Filters menu item from the Tools drop down menu:
Thunderbird RSS Message Filters Menu Item
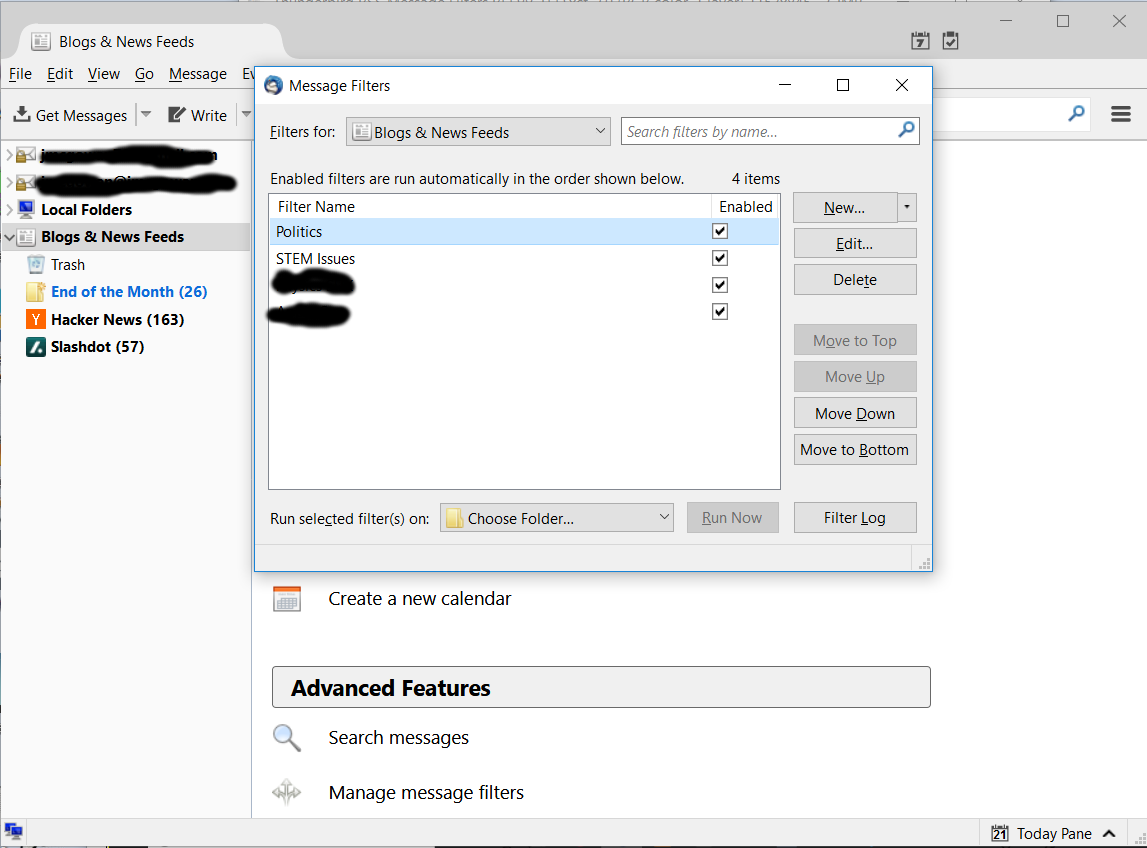
This brings up a dialog for creating and managing message filters:
Thunderbird RSS Message Filters Dialog
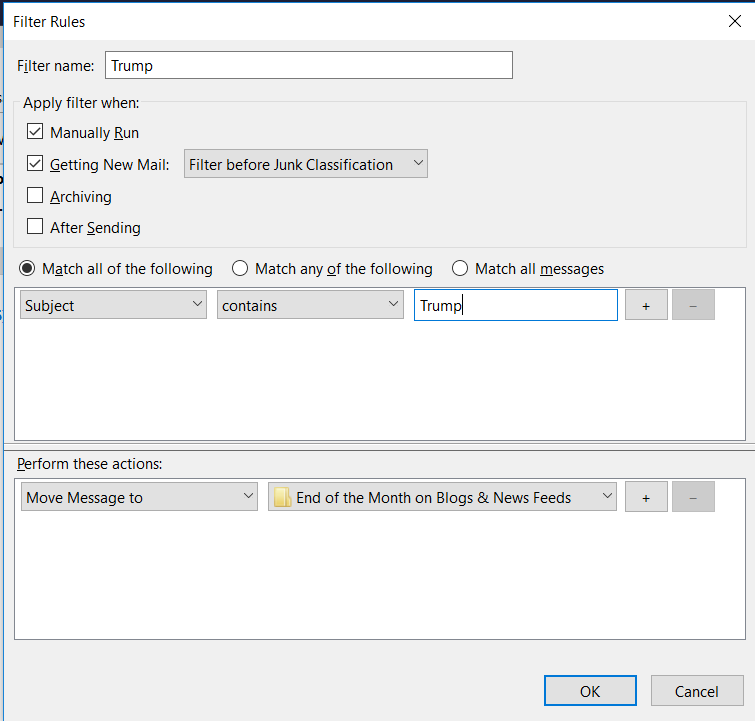
Click on the New button to create a new message filter. For example:
Thunderbird RSS Trump Filter Creation Example
The Distraction Economy
Smartphones and the Internet have become more and more distracting and addictive over the last several years with no signs of the trend reversing. This translates into many hours of lost time per week, month, and year. Even using the federal minimum wage of $7.25 per hour, five or ten hours per week lost to cat videos on YouTube, software industry gossip on Hacker News, or a million other online distractions translates into $36 to $72 per week, which is a lot for someone earning the minimum wage. Of course most readers of this article probably should value their time at $15 to $100 per hour.
A dollar estimate does not capture the lost real world social, personal, and professional opportunities. Outrage inducing videos and articles are often addictive but they are certainly not pleasant entertainment either.
Many of these distracting web sites, apps, and services seek to persuade us to buy products we don’t need, vote for public policies that don’t benefit us, and have other hidden costs that are difficult to measure — unlike lost time.
Many of these distracting web sites, apps, and services are also tightly integrated with a growing system of mass surveillance which, thanks to new technologies, is unprecedented in human history even in extreme dictatorships like Nazi Germany or Stalin’s Soviet Union. Extremely high bandwidth wireless networks, inexpensive high resolution video cameras, remarkable advances in video compression, huge disk drives, and ultra-fast computers have enabled levels of monitoring far beyond the dystopian future in George Orwell’s 1984.
Fears of terrorism and an implied Mad Max scenario of global economic collapse due to peak oil have contributed to a public acceptance of these highly questionable developments, along with shrewd marketing of social media and smartphones.
Waiting for companies obsessed with quarterly earnings and politicians beholden to wealthy campaign contributors to roll back or reform these developments is unlikely to work. People can take effective action — both individually and acting together — to reduce the level of distraction in their lives, regain valuable free time, and think more clearly, such as switching to RSS feeds and away from distracting web sites.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
I recently switched from an aging Apple Macbook Air to a shiny new, substantially lighterLG gram running Windows 10. This involved switching from Apple Mail to the free open-source Mozilla Thunderbird. In principle, Apple Mail can export my address book (contacts) in the human-readable vcard or VCF, Virtual Contact File, format and Thunderbird can import an address book in vcard format. BUT, as it happens, Thunderbird failed to import the telephone numbers for my contacts, a long standing problem with Thunderbird.
Mozilla Thunderbird
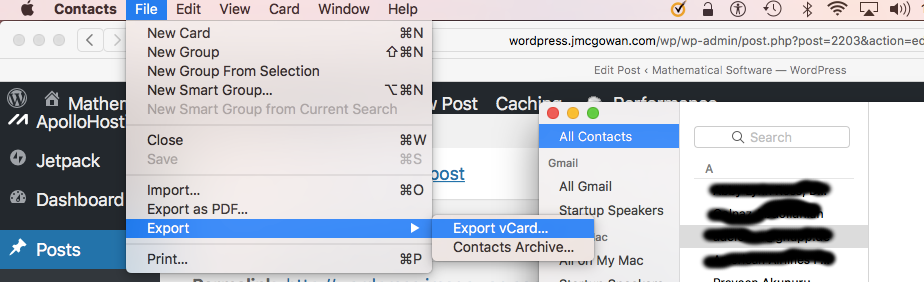
To export the Apple Mail contacts, bring up the Apple Contacts application, select All Contacts, and select File | Export | Export vCard…
Apple Contacts Export Closeup
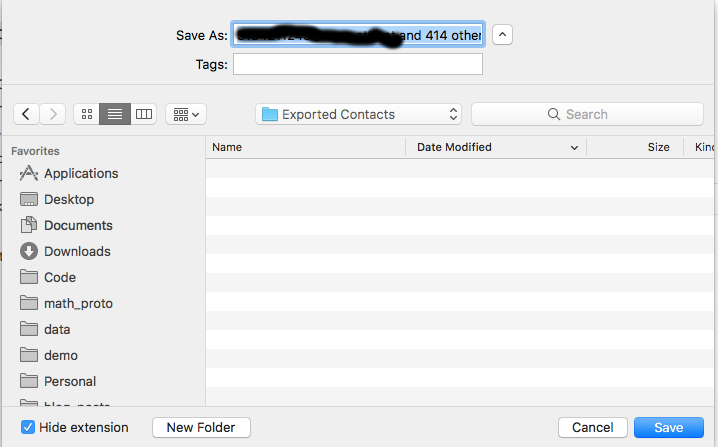
Then save the vCard file:
Apple Contacts Save Dialog Box
To import the Apple Mail contacts with the phone numbers successfully, I wrote a Python 3 script to convert the VCF file to a comma separated values (CSV) file that Thunderbird could import with the phone numbers. I used Python 3.6.4 installed as part of the Anaconda Python distribution. Python and Anaconda are both available for Windows, Mac OS X, and most major flavors of the free open-source GNU/Linux operating system. In principle, the Python script should run correctly on any of these platforms.
By default the script (below) assumes the vcard file is named jfm_contacts.vcf and writes the Thunderbird compliant CSV to tbird_imports.vcf
To run the script using ipython (installed by Anaconda) and override these defaults:
C:\Users\John McGowan\Code>ipython
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 6.2.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: run convert_vcf_to_csv.py mytest.vcf -o tbird_mytest.csv
Reading vcard (vcf) file: mytest.vcf
WARNING: VCARD 19 ( Apple Inc. ) 1-800-MY-APPLE MAY NOT BE A VALID PHONE NUMBER
WARNING: VCARD 301 ( Name ) Mobile MAY NOT BE A VALID PHONE NUMBER
WARNING: VCARD 301 ( Name ) Home MAY NOT BE A VALID PHONE NUMBER
WARNING: VCARD 301 ( Name ) Work MAY NOT BE A VALID PHONE NUMBER
WARNING: VCARD 301 ( Name ) Fax MAY NOT BE A VALID PHONE NUMBER
Processed 503 vcards
Wrote Thunderbird Compliant CSV file with phone numbers to: tbird_mytest.csv
ALL DONE
DISCLAIMER: Note that this script is provided “AS IS” (see license terms for more details). Giant corporations like Apple work long and hard to lock users into their “ecosystems” by, for example, using obfuscated non-standard “standard” formats for key contacts and other critical information stored in their products. Make sure to keep backups of your address books and contacts before using this script or similar software.
convert_vcf_to_csv.py
"""
convert Apple Mail VCF archive to CSV file for Mozilla Thunderbird (tbird)
tbird cannot read phone numbers from Apple Mail VCF file
"""
import sys
import os.path # os.path.isfile(fname)
import re # regular expressions
import phone # my phone number validation module
VERBOSE_FLAG = False # debug trace flag
# CSV file header generated by exporting contacts from Mozilla Thunderbird 52.6.0
TBIRD_ADR_BOOK_HEADER = 'First Name,Last Name,Display Name,Nickname,Primary Email,Secondary Email,Screen Name,Work Phone,Home Phone,Fax Number,Pager Number,Mobile Number,Home Address,Home Address 2,Home City,Home State,Home ZipCode,Home Country,Work Address,Work Address 2,Work City,Work State,Work ZipCode,Work Country,Job Title,Department,Organization,Web Page 1,Web Page 2,Birth Year,Birth Month,Birth Day,Custom 1,Custom 2,Custom 3,Custom 4,Notes' # was carriage return here
# John Nada from John Carpenter's THEY LIVE
DUMMY_CONTACT = 'John,Nada,John Nada,Nada,nada@nowhere.com,nada@cable54.com,NADA,999-555-1212,888-555-1234,777-555-6655,111-555-1234,111-555-9876,123 Main Street, Apt 13, Los Angeles, CA, 91210,USA,Work Address,Work Address 2,Work City,Work State,Work ZipCode,Work Country,Job Title,Department,Organization,Web Page 1,Web Page 2,Birth Year,Birth Month,Birth Day,Custom 1,Custom 2,Custom 3,Custom 4,Notes'
# break into values
FIELD_NAMES = TBIRD_ADR_BOOK_HEADER.split(',')
FIELD_VALUES_START = DUMMY_CONTACT.split(',')
for index, value in enumerate(FIELD_VALUES_START):
FIELD_VALUES_START[index] = '' # try single space
# build dictionary to map from field name to index
FIELD_INDEX = {}
for index, field_name in enumerate(FIELD_NAMES):
FIELD_INDEX[field_name] = index
if VERBOSE_FLAG:
print(FIELD_INDEX)
print(TBIRD_ADR_BOOK_HEADER)
print(DUMMY_CONTACT)
if len(sys.argv) < 2:
VCARD_FILE = 'jfm_contacts.vcf'
else:
VCARD_FILE = sys.argv[1] # 0 is script name
def usage(cmd):
""" usage message """
print("Usage: ", cmd, " [-license] [-o output_file.csv] ")
print(" -- generate Thunderbird Compliant CSV file with importable telephone numbers ")
print(" -- from Apple Mail generated .vcf (vcard) file")
print(" -- (C) 2018 by John F. McGowan, Ph.D.")
print(" ")
print(" -license -- print license terms")
print(" ")
print("In Mozilla Thunderbird 52.6.0, Tools | Import | Address Books | Text file(LDIF,csv,tab,txt) | choose output file from this program.")
print(" ")
print("Tested with Python 3.6.4 installed by/with Anaconda")
def license_terms():
""" license terms """
license_msg = """Copyright 2018 John F. McGowan, Ph.D.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
print(license_msg)
if VCARD_FILE == "--help" or VCARD_FILE == "-h"\
or VCARD_FILE == "-help" or VCARD_FILE == "-?":
usage(sys.argv[0])
sys.exit(0)
if VCARD_FILE == "--license" or VCARD_FILE == "-license":
license_terms()
sys.exit(0)
OUTPUT_FILENAME = 'tbird_imports.csv'
OUTPUT_FLAG = False
for arg_index, argval in enumerate(sys.argv):
if OUTPUT_FLAG:
OUTPUT_FILENAME = argval
OUTPUT_FLAG = False
if argval == "-o":
OUTPUT_FLAG = True
# write import file with one dummy contact (John Nada from THEY LIVE)
OUTPUT_FILE = open(OUTPUT_FILENAME, 'w')
OUTPUT_FILE.write(TBIRD_ADR_BOOK_HEADER)
OUTPUT_FILE.write('\n')
OUTPUT_FILE.write(DUMMY_CONTACT)
OUTPUT_FILE.write('\n')
COMMA_DELIM = r"\,"
VCARD_COUNT = 0
b_processing = False # processing a vcard
# check if input file exists
if os.path.isfile(VCARD_FILE):
print("Reading vcard (vcf) file: ", VCARD_FILE)
else:
print("Input vcard (vcf) file ", VCARD_FILE, " does not exist (missing)!")
sys.exit(0)
input_file = open(VCARD_FILE)
for line in input_file:
values = line.split(':')
if values[0] == 'BEGIN':
if len(values) > 1:
if values[1] == 'VCARD\n':
VCARD_COUNT = VCARD_COUNT + 1
b_processing = True
FIELD_VALUES = FIELD_VALUES_START.copy()
if b_processing:
tag = values[0]
if tag == 'END': # reached end of vcard
if VERBOSE_FLAG:
print("END OF VCARD ", VCARD_COUNT)
b_processing = False
# process non-dummy contact
if FIELD_VALUES[FIELD_INDEX['Display Name']] != FIELD_VALUES_START[FIELD_INDEX['Display Name']]:
contact_record = ','.join(FIELD_VALUES)
if VERBOSE_FLAG:
print(contact_record)
OUTPUT_FILE.write(contact_record)
OUTPUT_FILE.write('\n')
# parse info for the contact
if tag == 'N':
contact_name = values[1].strip().replace(';', ' ')
if COMMA_DELIM in contact_name:
contact_name = contact_name.split(COMMA_DELIM)[0]
if isinstance(contact_name, str):
name_parts = contact_name.split()
if len(name_parts) > 1:
contact_first_name = name_parts[1]
contact_last_name = name_parts[0]
else:
contact_first_name = ''
contact_last_name = ''
FIELD_VALUES[FIELD_INDEX['First Name']] = contact_first_name
FIELD_VALUES[FIELD_INDEX['Last Name']] = contact_last_name
if tag == 'FN': # FN (full name) is usually first_name last_name
contact_fullname = values[1].strip().replace(';', ' ')
if COMMA_DELIM in contact_fullname:
contact_fullname = contact_fullname.split(COMMA_DELIM)[0]
if isinstance(contact_fullname, str):
FIELD_VALUES[FIELD_INDEX['Display Name']] = contact_fullname
name_parts = contact_fullname.split()
contact_first_name = name_parts[0]
if len(name_parts) > 1:
contact_last_name = name_parts[1]
else:
contact_last_name = ''
else:
contact_first_name = ''
contact_last_name = ''
FIELD_VALUES[FIELD_INDEX['First Name']] = contact_first_name
FIELD_VALUES[FIELD_INDEX['Last Name']] = contact_last_name
#print(contact_fullname)
if tag == 'ORG': # ORG (organization)
contact_org = values[1].strip().replace(';', ' ')
# Apple vcard uses semicolon as embedded delimiter
FIELD_VALUES[FIELD_INDEX['Organization']] = contact_org
if tag == 'NOTE': # NOTE (notes) in VCF
contact_notes = values[1].strip().replace(r'\n', ' ')
FIELD_VALUES[FIELD_INDEX['Notes']] = 'NOTE: ' + contact_notes
if tag == 'TITLE': # TITLE
contact_title = values[1].strip()
FIELD_VALUES[FIELD_INDEX['Job Title']] = 'TITLE: ' + contact_title
if tag.startswith('EMAIL'): #process emails
contact_email = values[1].strip()
FIELD_VALUES[FIELD_INDEX['Primary Email']] = contact_email
if tag.startswith('TEL'): # process phone numbers
contact_phone = values[1].strip()
# remove special characters and other noise
contact_phone = re.sub('[^A-Za-z0-9() -]+', ' ', contact_phone)
contact_phone = contact_phone.strip() # remove leading/trailing whitespace
if not phone.is_valid_phone(contact_phone):
print("WARNING: VCARD ", VCARD_COUNT, " (", contact_fullname, ") ", \
contact_phone, " MAY NOT BE A VALID PHONE NUMBER")
if "HOME" in tag:
FIELD_VALUES[FIELD_INDEX['Home Phone']] = contact_phone
elif "WORK" in tag:
FIELD_VALUES[FIELD_INDEX['Work Phone']] = contact_phone
elif "MAIN" in tag:
FIELD_VALUES[FIELD_INDEX['Work Phone']] = contact_phone
elif "CELL" in tag:
FIELD_VALUES[FIELD_INDEX['Mobile Number']] = contact_phone
elif "OTHER" in tag:
FIELD_VALUES[FIELD_INDEX['Custom 1']] = 'OTHER PHONE: ' + contact_phone
else:
FIELD_VALUES[FIELD_INDEX['Work Phone']] = contact_phone
if tag.startswith('ADR'): # physical addresses
contact_address = values[1].strip().strip(';')
contact_address = contact_address.replace(r'\n', ';')
if "HOME" in tag:
FIELD_VALUES[FIELD_INDEX['Home Address']] = contact_address
elif "WORK" in tag:
FIELD_VALUES[FIELD_INDEX['Work Address']] = contact_address
elif "OTHER" in tag:
FIELD_VALUES[FIELD_INDEX['Custom 2']] = 'OTHER ADDRESS: ' + contact_address
else:
FIELD_VALUES[FIELD_INDEX['Home Address']] = contact_address
# just ^URL;....:url
if tag.startswith('URL'): # url
contact_url = values[1].strip()
index = FIELD_INDEX['Web Page 1']
if not FIELD_VALUES[index]:
FIELD_VALUES[index] = contact_url
else:
FIELD_VALUES[FIELD_INDEX['Web Page 2']] = contact_url
if tag.startswith('item1.URL'): # item1.URL...:https:remaining_url
contact_url = ':'.join(values[1:])
contact_url = contact_url.strip()
if contact_url[:4] != 'http':
contact_url = 'http://' + contact_url
index = FIELD_INDEX['Web Page 1']
if not FIELD_VALUES[index]:
FIELD_VALUES[index] = contact_url
else:
FIELD_VALUES[FIELD_INDEX['Web Page 2']] = contact_url
if tag.startswith('item2.URL'): # item2.URL...:https:remaining_url
contact_url = ':'.join(values[1:])
contact_url = contact_url.strip()
if contact_url[:4] != 'http':
contact_url = 'http://' + contact_url
index = FIELD_INDEX['Web Page 1']
if not FIELD_VALUES[index]:
FIELD_VALUES[index] = contact_url
else:
FIELD_VALUES[FIELD_INDEX['Web Page 2']] = contact_url
print("Processed ", VCARD_COUNT, " vcards")
OUTPUT_FILE.close()
print("Wrote Thunderbird Compliant CSV file with phone numbers to: ", OUTPUT_FILENAME)
print('ALL DONE')
convert_vcf_to_csv.py expects a module phone.py which contains code to check if a phone number is valid. The convert_vcf_to_csv.py script will print warning messages if it encounters a phone number that may be invalid although it still inserts the suspect phone number in the CSV file.
phone.py
'''
validate phone number module
(C) 2018 by John F. McGowan, Ph.D.
'''
import re
def is_valid_phone(phone_number):
''' determine if argument is a valid phone number '''
result = re.match(r'\d?[ -]*(\d{3}|\(\d{3}\))?[ -]*\d{3}[- ]*\d{4}', phone_number)
return bool(result != None)
Usage message
convert_vcf_to_csv.py --help
Usage: convert_vcf_to_csv.py [-license] [-o output_file.csv]
-- generate Thunderbird Compliant CSV file with importable telephone numbers
-- from Apple Mail generated .vcf (vcard) file
-- (C) 2018 by John F. McGowan, Ph.D.
-license -- print license terms
In Mozilla Thunderbird 52.6.0, Tools | Import | Address Books | Text file(LDIF,csv,tab,txt) | choose output file from this program.
Tested with Python 3.6.4 installed by/with Anaconda
By default, convert_vcf_to_csv.py writes an output file tbird_imports.csv which can be imported into the Thunderbird Address Book as follows:
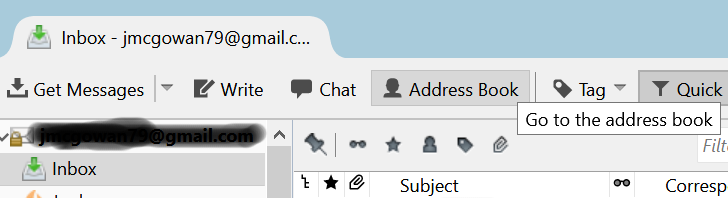
(1) Bring up the Mozilla Thunderbird Address Book by clicking on the Address Bookbutton in Thunderbird:
Address Book Button in Thunderbird
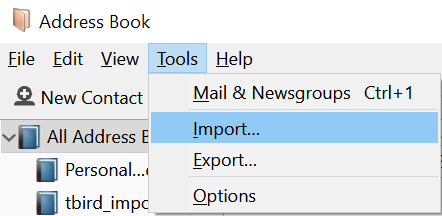
(2) Select Tools | Import
Import Menu Item in Thunderbird Address Book
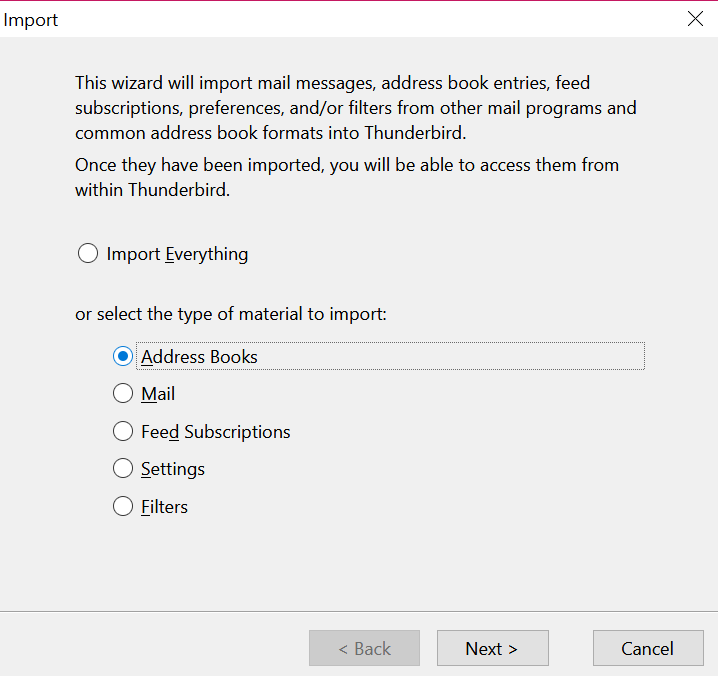
(3) This brings up an Importdialog. Select the Address Books option in the Importdialog.
Select Address Books Item in Import Dialog
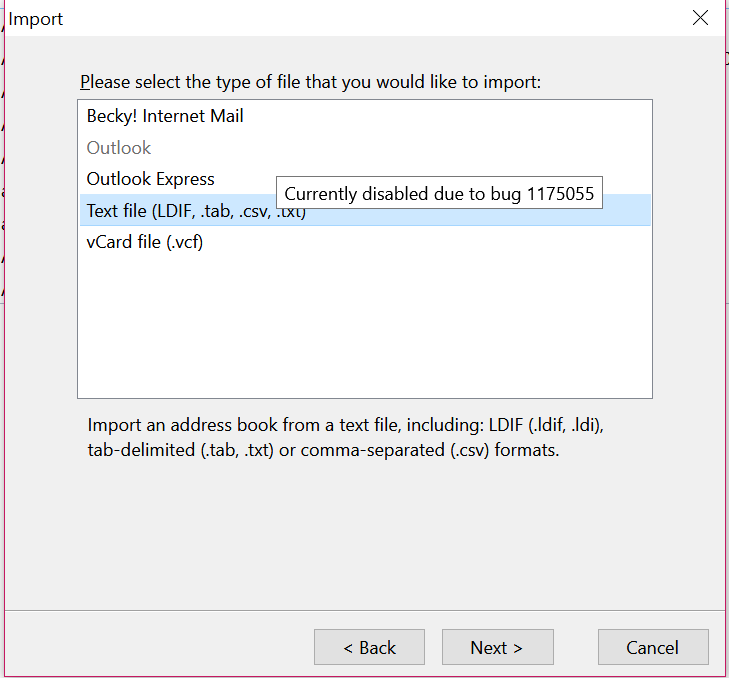
(4) Select Nextbutton. This brings up a File Type Selection Dialog. Select Text File (LDIF, .tab, .csv, .txt)
Select Text File Type for Import
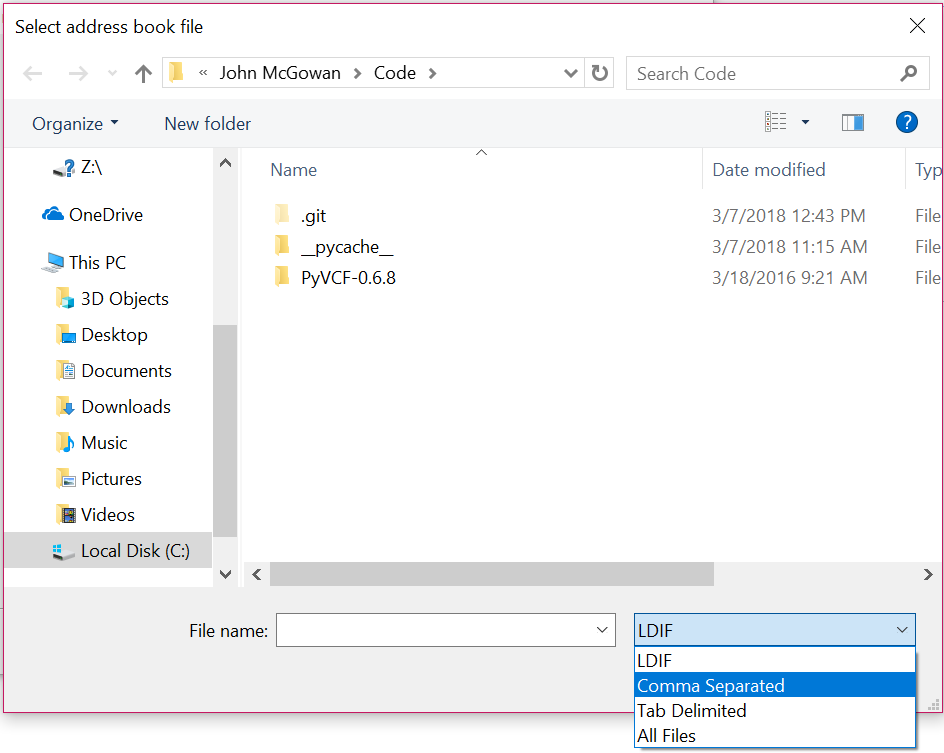
(5) Select Nextbutton. This brings up the Select address book filedialog. By default this displays and imports LDIF format address book. Select comma separated values (CSV) instead:
Select address book file dialog box
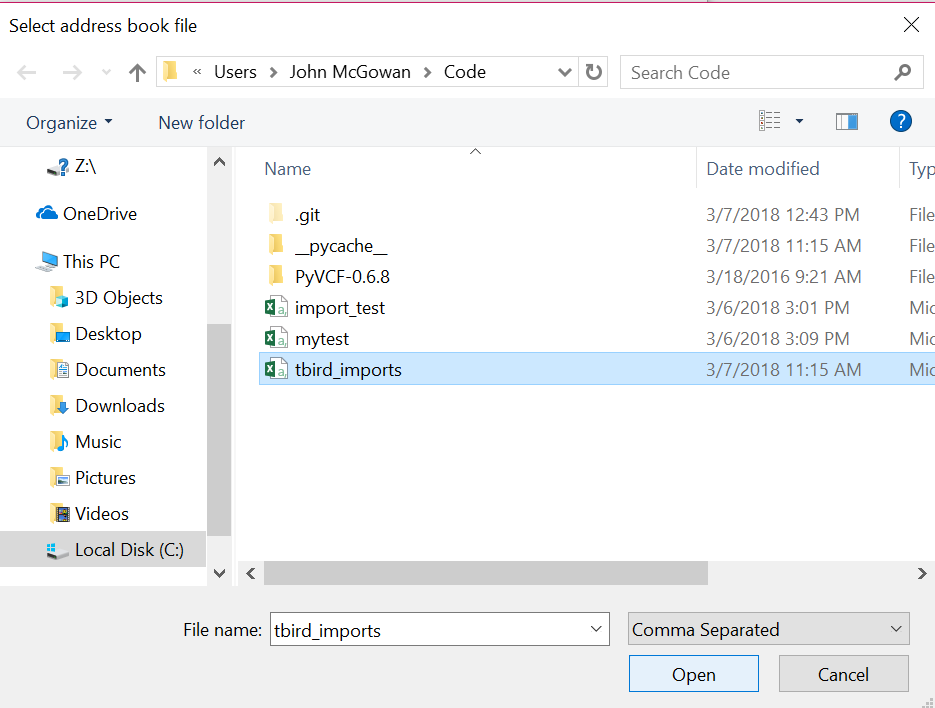
(6) Now open the Thunderbird compliant CSV file, default name tbird_imports.csv:
Open tbird_imports CSV file
(7) The new address book will now be imported into Mozilla Thunderbird complete with phone numbers. The new address book will appear in the list of address books displayed but the individual contacts may not be displayed immediately. Switch to another address book and back to see the new contacts or try searching for a new contact.
NOTE: Tested with Python 3.6.4 installed by Anaconda, Mozilla Thunderbird 52.6.0 on LG gram with Windows 10, and VCF contacts file exported from Apple Contacts Version 10.0 (1756.20) on a 13 inch Macbook Air (about 2014 vintage) running Mac OS X version 10.12.6 (macOS Sierra).
(C) 2018 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).