

DNA ancestry tests are tests marketed by genetic testing firms such as 23andme , Ancestry.com , Family Tree DNA, and National Geographic Geno as well as various consultants and academic researchers that purport to give the percentage of ancestry of a customer from various races, ethnic groups, and nationalities. They have been marketed to African-Americans to supposedly locate their ancestors in Africa (e.g. Ghana versus Mozambique) and many other groups with serious questions about their family history and background.
It is difficult (perhaps impossible) to find detailed information on the accuracy and reliability of the DNA ancestry kits on the web sites of major home DNA testing companies such as 23andMe. The examples shown on the web sites usually show only point estimates of ancestry percentages without errors. This is not common scientific practice where numbers should always be reported with errors (e.g. ±0.5 percent). The lack of reported errors on the percentages implies no significant errors are present; any error is less than the least significant reported digit (a tenth of one percent here).

The terms of service on the web sites often contain broad disclaimers:
23andMe Terms of Service on Feb. 14, 2019 (Emphasis added)
The laboratory may not be able to process your sample, and the laboratory process may result in errors. The laboratory may not be able to process your sample up to 3.0% of the time if your saliva does not contain a sufficient volume of DNA, you do not provide enough saliva, or the results from processing do not meet our standards for accuracy.* If the initial processing fails for any of these reasons, 23andMe will reprocess the same sample at no charge to the user. If the second attempt to process the same sample fails, 23andMe will offer to send another kit to the user to collect a second sample at no charge. If the user sends another sample and 23andMe’s attempts to process the second sample are unsuccessful, (up to 0.35% of all samples fail the second attempt at testing according to 23andMe data obtained in 2014 for all genotype testing),* 23andMe will not send additional sample collection kits and the user will be entitled solely and exclusively to a complete refund of the amount paid to 23andMe, less shipping and handling, provided the user shall not resubmit another sample through a future purchase of the service. If the user breaches this policy agreement and resubmits another sample through a future purchase of the service and processing is not successful, 23andMe will not offer to reprocess the sample or provide the user a refund. Even for processing that meets our high standards, a small, unknown fraction of the data generated during the laboratory process may be un-interpretable or incorrect (referred to as “Errors”). As this possibility is known in advance, users are not entitled to refunds where these Errors occur.
“A small, unknown fraction” can mean ten percent or even more in common English usage. No numerical upper bound is given. Presumably, “un-interpretable” results can be detected and the customer notified that an “Error” occurred. The Terms of Service does not actually say that this will happen.
Nothing indicates the “incorrect” results can be detected and won’t be sent to the customer. It is not clear whether “data generated during the laboratory process” includes the ancestry percentages reported to customers.
On January 18, 2019 the CBC (Canadian Broadcasting Corporation) ran a news segment detailing the conflicting results from sending a reporter and her identical twin sister’s DNA to several major DNA ancestry testing companies: “Twins get some ‘mystifying’ results when they put 5 DNA Ancestry Kits to the test.” These included significant — several percent — differences in reported ancestry between different companies and significant differences in reported ancestry between the two twins at the same DNA testing company! The identical twins have almost the same DNA.
The CBC is not the first news organization to put the DNA ancestry tests to a test and get surprising results. For example, on February 21, 2017, CBS’s Inside Edition ran a segment comparing test results for three identical triplets: “How Reliable are Home DNA Ancestry Tests? Investigation Uses Triplets to Find Out.”
The sisters were all 99 percent European but the test from 23andMe also showed some surprising differences.
Nicole was 11 percent French and German but Erica was 22.3 percent. Their sister Jaclyn was in the middle at 18 percent.
Inside Edition: How Reliable Are Home DNA Ancestry Tests
It is not uncommon to encounter YouTube videos and blog posts reporting experiences with home DNA tests where the results from different companies differ by several percent, the results from the same company change by several percent, or report a small percentage of ancestry not supported by any family history, documentation or visible features. Ashkenazi Jewish, African, Asian, and American Indian are all common in the surprising results. Test results from commercial DNA tests reporting American Indian ancestry seem remarkably uncorrelated with family traditions of American Indian ancestry. Some users have reported gross errors in the test results although these seem rare.
The major DNA ancestry testing companies such as 23andMe may argue that they have millions of satisfied customers and these reports are infrequent exceptions. This excuse is difficult to evaluate since the companies keep their databases and algorithms secret, the ground truth in many cases is unknown, and many customers have only a passing “recreational” interest in the results.
Where the interest in the DNA ancestry results is more serious customers should receive a very high level of accuracy with the errors clearly stated. Forensic DNA tests used in capital offenses and paternity tests are generally marketed with claims of astronomical accuracy (chances of a wrong result being one in a billion or trillion). In fact, errors have occurred in both forensic DNA tests and paternity tests, usually attributed to sample contamination.
How Accurate are DNA Ancestry Tests?
DNA ancestry tests are often discussed as if the DNA in our cells comes with tiny molecular barcodes attached identifying some DNA as black, white, Irish, Thai and so forth. News reports and articles speak glibly of “Indian DNA” or “Asian DNA”. It sounds like DNA ancestry tests simply find the barcoded DNA and count how much is in the customer’s DNA.
The critical point, which is often unclear to users of the tests, is that the DNA ancestry test results are estimates based on statistical models of the frequency of genes and genetic markers in populations. Red hair gives a simple, visible example. Red hair is widely distributed. There are people with red hair in Europe, Central Asia, and even Middle Eastern countries such as Iran, Iraq and Afghanistan. There were people with red hair in western China in ancient times. There are people with red hair in Polynesia and Melanesia!
However red hair is unusually common in Ireland, Scotland, and Wales with about 12-13% of people having red hair. It is estimated about forty percent of people in Ireland, Scotland, and Wales carry at least one copy of the variant M1CR gene that seems to be the primary cause of most red hair. Note that variations in other genes are also believed to cause red hair. Not everyone with red hair has the variation in M1CR thought to be the primary cause of red hair. Thus, if someone has red hair (or the variant M1CR gene common in people with red hair), we can guess they have Irish, Scottish, or Welsh ancestry and we will be right very often.
Suppose we combine the red hair with traits — genes or genetic markers in general — that are more common in people of Irish, Scottish or Welsh descent than in other groups. Then we can be more confident that someone has Irish, Scottish, or Welsh ancestry than using red hair or the M1CR gene alone. In general, even with many such traits or genes we cannot be absolutely certain.
To make combining multiple traits or genes more concrete, let’s consider two groups (A and B) with different frequencies of common features. Group A is similar to the Irish, Scots, and Welsh with thirteen percent having red hair. Group A is more southern European with only one percent having red hair. The distributions of skin tone differ with Group A having eighty percent with very fair skin versus only fifty percent in Group B. Similarly blue eyes are much more common in Group A: fifty percent in group A and only 8.9 percent in group B. To make the analysis and computations simple, Groups A and B have the same number of members — one million.
For illustrative purposes only, we are assuming the traits are uncorrelated. In reality, red hair is correlated with very fair skin and freckles.
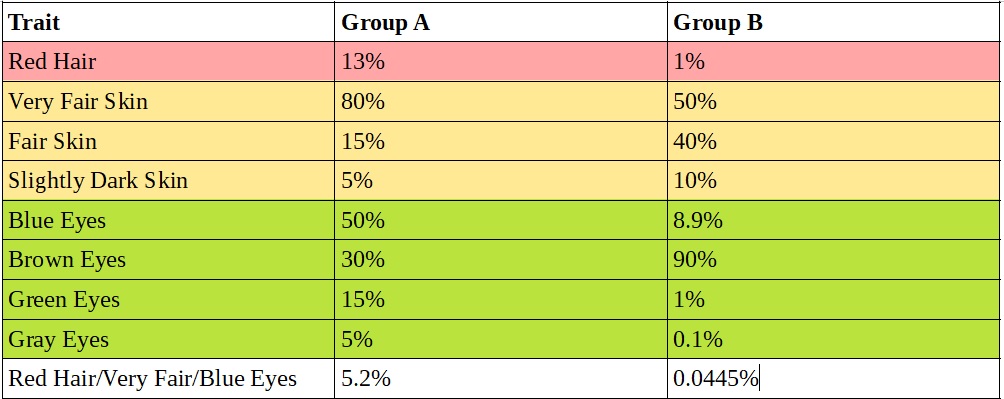
Using hair color alone, someone with red hair has a 13/(13+1=14) or 95.86% chance of belonging to group A. Using hair color, skin tone, and eye color, someone with red hair and very fair skin and blue eyes has a 5.2/(5.2+0.0445=5.2445) or 99.14% chance of belonging to group A.
Combining multiple traits (or genes and genetic markers) increases our confidence in the estimate of group membership but it cannot give an absolute definitive answer unless at least one trait (or gene or genetic marker) is unique to one group. This “barcode” trait or gene is a unique identifier for group membership.
Few genes or genetic markers have been identified that correlate strongly with our concepts of race, ethnicity, or nationality. One of the most well known and highly correlated examples is the Duffy null allele which is found in about ninety percent of Sub-Saharan Africans and is quite rare outside of Sub-Saharan Africa. The Duffy allele is thought to provide some resistance to vivax malaria.
Nonetheless, white people with no known African ancestry are sometimes encountered with the Duffy allele. This is often taken as indicating undocumented African ancestry, but we don’t really know. At least anecdotally, it is not uncommon for large surveys of European ancestry populations to turn up a few people with genes or genetic markers like the Duffy allele that are rare in Europe but common in Africa or Polynesia or other distant regions.
A More Realistic Example
The Duffy null allele and the variant M1CR gene that is supposed to be the cause of most red hair are unusually highly correlated with group membership. For illustrative purposes, let’s consider a model of combining multiple genes to identify group membership that may be more like the real situation.
Let’s consider a collection of one hundred genes. For example these could be genes that determine skin tone. Each gene has a light skin tone and a dark skin tone variant. The more dark skin tone variants someone has, the darker their skin tone. For bookkeeping we label the the light skin tone gene variants L1 through L100 and the dark skin tone genes variants D1 through D100.
Group A has a ten percent (1 in 10) chance of having the dark skin variant of each gene. On average, a member of group A has ninety (90) of the light skin tone variants and ten (10) of the dark skin variants. Group A may be somewhat like Northern Europeans.
Group B has a thirty percent (about 1 in 3) chance of having the dark skin variant of each gene. On average, a member of group B has seventy (70) of the light skin variants and thirty (30) of the dark skin variants. Group B may be somewhat like Mediterranean or some East Asian populations.
Notice that none of the gene variants is at all unique or nearly unique to either group. None of them acts like the M1CR variant associated with red hair, let alone the Duffy null allele. Nonetheless a genetic test can distinguish between membership in group A and group B with high confidence.

Group A members have on average ten (10) dark skin variants with a standard deviation of three (3). This means ninety-five percent (95%) of Group A members will have between four (4) and sixteen (16) of the dark skin variant genes.
Group B members have on average thirty (30) dark skin variants with a standard deviation of about 4.6. This means about ninety-five percent (95%) of Group B members will have between twenty-one (21) and thirty-nine (39) dark skin variants.
In most cases, counting the number of dark skin variants that a person possesses will give over a ninety-five percent (95%) confidence level as to their group membership.
Someone with a parent from Group A and a parent from group B will fall smack in the middle, with an average of twenty (20) dark skin gene variants. Based on the genetic testing alone, they could be an unusually dark skinned member of Group A, an unusually light skinned member of Group B, or someone of mixed ancestry.
Someone with one grandparent from Group B and three grandparents from Group A would have fifteen (15) dark skin gene variants in their DNA, falling within two standard deviations of the Group A average. At least two percent (2%) of the members of Group A will have a darker skin tone than this person. Within just a few generations we lose the ability to detect Group B ancestry!
In the real world, each gene will have different variant frequencies, not ten percent versus thirty percent for every one, making the real world probability computations much more complicated.
The Out of Africa Hypothesis
The dominant hypothesis of human origins is that all humans are descended from an original population of early humans in Africa, where most early fossil remains of human and pre-human hominids have been found. According to this theory, the current populations in Europe, Asia, the Pacific Islands, and the Americas are descended from small populations that migrated out of Africa relatively recently in evolutionary terms — fifty-thousand to two-hundred thousand years ago depending on the variant of the theory. Not a lot of time for significant mutations to occur. Thus our ancestors may have started out with very similar frequencies of various traits, genes, and genetic markers. Selection pressures caused changes in the frequency of the genes (along with occasional mutations), notably selecting for lighter skin in northern climates.
Thus all races and groups may contain from very ancient times some people with traits, genes and genetic markers from Africa that have become more common in some regions and less common in other regions. Quite possibly the original founding populations included some members with the Duffy allele which increased in prevalence in Africa and remained rare or decreased in the other populations. Thus the presence of the Duffy allele or other rare genes or genetic markers does not necessarily indicate undocumented modern African ancestry — although it surely does in many cases.
Racially Identifying Characteristics Are Caused By Multiple Genes
The physical characteristics used to identify races such as skin tone, the extremely curly hair among most black Africans, and the epicanthic folds in East Asians (Orientals) that give the distinctive “slant” eyed appearance with the fold frequently covering the interior corner of the eye appear to be caused by multiple genes rather than a single “barcode” racial gene. Several genes work together to determine skin tone in ways that are not fully understood. Thus children of a light skinned parent and a dark skinned parent generally fall somewhere on the spectrum between the two skin tones.
Racially identifying physical characteristics are subject to blending inheritance and generally dilute away with repeated intermixing with another race as is clearly visible in many American Indians with well documented heavy European ancestry as for example the famous Cherokee chief John Ross:

Would a modern DNA ancestry test have correctly detected John Ross’s American Indian ancestry?
There are also many examples of people with recent East Asian ancestry who nonetheless look entirely or mostly European. These include the actresses Phoebe Cates (Chinese-Filipino grandfather), Meg Tilly (Margaret Elizabeth Chan, Chinese father), and Kristin Kreuk (Smallville, Chinese mother). Note that none of these examples has an epicanthic fold that cover the interior corner of the eyes. Especially since these are performers, the possibility of unreported cosmetic surgery cannot be ignored, but it is common for the folds to disappear or be greatly moderated in just one generation — no longer covering the interior corner of the eye for example.

Greg in Hollywood (Greg Hernandez) – Flickr
CC BY 2.0 )

Mr. Bombdiggity – Flick
CC BY 2.0 )

Carlos Almendarez from San Francisco, USA
CC BY 2.0 )
How well do the DNA ancestry tests work for European looking people with well-documented East Asian ancestry, even a parent?
There are also examples of people with recent well-documented African, Afro-Carribean, or African-American ancestry who look very European. The best-selling author Malcolm Gladwell has an English father and a Jamaican mother. By his own account, his mother has some white ancestry. His hair is unusually curly and I suspect an expert in hair could distinguish it from unusually curly European hair.

Kris Krüg – https://www.flickr.com/photos/poptech2006/2967350188/
CC BY 2.0 )
In fact, some (not all) of the genes that cause racially identifying physical characteristics may be relatively “common” in other races, not extremely rare like the Duffy allele. For example, a few percent of Northern Europeans, particularly some Scandinavians, have folds around the eyes similar to East Asians, although the fully developed fold covering the interior corner of the eye is rare. Some people in Finland look remarkably Asian although they are generally distinguishable from true Asians. This is often attributed to Sami ancestry, although other theories include the Mongol invasions of the thirteenth century, the Hun invasions of the fifth century, other unknown migrations from the east, and captives brought back from North America or Central Asia by Viking raiders.
The Icelandic singer Björk (Björk Guðmundsdóttir) is a prominent example of a Scandinavian with strongly Asian features including a mild epicanthic fold that does not cover the interior corners of her eyes. Here are some links to closeups of her face that look particularly Asian: https://nocturnades.files.wordpress.com/2014/06/bjork.jpeg, http://music.mxdwn.com/wp-content/uploads/2015/03/Bjork_1_11920x1440_International_Star_Singer_Wallpaper.jpg and https://guidetoiceland.is/image/4927/x/0/top-10-sexiest-women-in-iceland-2014-10.jpg
There is a lot of speculation on-line that Björk has Inuit ancestry and she has performed with Inuit musicians, but there appears to be no evidence of this. As noted above, a small minority of Scandinavians have epicanthic folds and other stereotypically Asian features.
The epicanthic fold is often thought to be an adaptation to the harsh northern climate with East Asians then migrating south into warmer regions. It is worth noting that the epicanthic fold and other “East Asian” eye features are found in some Africans. The “Out of Africa” explanation for milder forms of this feature in some northern Europeans is some early Europeans carried the traits with them from Africa and it was selected for in the harsh northern climate of Scandinavia and nearby regions, just as may have happened to a much greater extent in East Asia.
The critical point is that at present DNA ancestry tests — which are generally secret proprietary algorithms — are almost certainly using relative frequencies of various genes and genetic markers in different populations rather than a mythical genetic barcode that uniquely identifies the race, ethnicity, or nationality of the customer or his/her ancestors.
Hill Climbing Algorithms Can Give Unpredictable Results
In data analysis, it is common to use hill-climbing algorithms to “fit” models to data. A hill climbing algorithm starts at an educated or sometimes completely random guess as to the right result, searches nearby, and moves to the best result found in the neighborhood. It repeats the process until it reaches the top of a hill. It is not unlikely that some of the DNA ancestry tests are using hill climbing algorithms to find the “best” guess as to the ancestry/ethnicity of the customer.
Hill climbing algorithms can give unpredictable results depending both on the original guess and very minor variations (such as small differences between the DNA of identical twins). This can happen when the search starts near the midpoint of a valley between two hills. Should the algorithm go up one side (east) or up the other side of the valley (west)? A very small difference in the nearly flat valley floor can favor one side over the other, even though otherwise the situation is very very similar.
In DNA testing, east-west location might represent the fraction of European ancestry and the north-west location might represent the fraction of American Indian ancestry (for example). The height of the hill is measure of the goodness of fit between the model and the data (the genes and genetic markers in the DNA). Consider the difficulties that might arise discriminating between someone, mostly European, with a small amount of American Indian ancestry (say some of the genes that contribute to the epicanthic fold found in some American Indians) and someone who is entirely European but has a mild epicanthic fold and, in fact, some of the same genes. Two adjacent hills with a separating valley may appear — one representing all European and one representing Mostly European with a small mixture of American Indian.
This problem with hill climbing algorithms may explain the striking different results for two identical twins from the same DNA testing company reported by the CBC.
Other model fitting and statistical analysis methods can also exhibit unstable results in certain situations.
Again, the DNA ancestry tests are using the relative frequency of genes and genetic markers found in many groups, even in different races and on different continents, rather than a hypothetical group “barcode” gene that is a unique identifier.
Conclusion
It is reasonable to strongly suspect, given the many reports like the recent CBC news segment of variations in the estimated ancestry of several percent, that DNA ancestry tests for race, ethnicity, and nationality are not reliable at the few percent level (about 1/16, 6.25%, great-great-grandparent level) at present (Feb. 2019). Even where an unusual gene or genetic marker such as the Duffy null allele that is highly correlated with group membership is found in a customer, some caution is warranted as the “out of Africa” hypothesis suggests that many potential group “barcode” genes and markers will be present at low levels in all human populations.
It may be that the many reports of several percent errors in DNA ancestry tests are relatively rare compared to the millions of DNA ancestry tests now administered. Many DNA ancestry tests are “recreational” and occasional errors of several percent in such recreational cases are tolerable. Where DNA ancestry tests have serious implications, public policy or otherwise, much higher accuracy — as is claimed for forensic DNA tests and DNA paternity tests — is expected and should be required. Errors (e.g. ±0.5 percent) and/or confidence levels should be clearly stated and explained.
Some Academic Critiques of DNA Ancestry Testing
Inferring Genetic Ancestry: Opportunities, Challenges, and Implications
Charmaine D. Royal, John Novembre, Stephanie M. Fullerton, David B. Goldstein, Jeffrey C. Long, Michael J. Bamshad, and Andrew G. Clark
The American Journal of Human Genetics 86, 661–673, May 14, 2010
The Illusive Gold Standard in Genetic Ancestry Testing
See all authors and affiliations
Science 03 Jul 2009:
Vol. 325, Issue 5936, pp. 38-39
DOI: 10.1126/science.1173038
The Science and Business of Genetic Ancestry Testing
- Deborah A. Bolnick1,*,
- Duana Fullwiley2,
- Troy Duster3,4,
- Richard S. Cooper5,
- Joan H. Fujimura6,
- Jonathan Kahn7,
- Jay S. Kaufman8,
- Jonathan Marks9,
- Ann Morning3,
- Alondra Nelson10,
- Pilar Ossorio11,
- Jenny Reardon12,
- Susan M. Reverby13,
- Kimberly TallBear14,15
See all authors and affiliations
Science 19 Oct 2007:
Vol. 318, Issue 5849, pp. 399-400
DOI: 10.1126/science.1150098
The American Society of Human Genetics Ancestry Testing Statement
November 13, 2008
(C) 2019 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).