Sabine Hossenfelder, a disillusioned (former?) theoretical particle physicist and science popularizer, recently published a video “What’s going wrong in particle physics?” on her YouTube channel criticizing fifty years of common practice in particle physics. I’ve previously reviewed her book Lost in Math: How Beauty Leads Physics Astray published in 2018 and an editorial “The Uncertain Future of Particle Physics” in The New York Times (January 23, 2019) questioning the wisdom of funding CERN’s recent proposal to build a new particle accelerator, the Future Circular Collider (FCC), estimated to cost over $10 billion. See the links below for the Lost in Math book review and commentary on the editorial. Comments on the YouTube video follow these links.
Dr. Hossenfelder’s point in the video is fairly simple. She argues that since the formulation of the so-called “standard model” (formerly known as Glashow-Weinberg-Salam or Weinberg-Salam after theoretical physicists Sheldon Glashow, Stephen Weinberg, and Abdus Salam) in the 1960’s and 1970’s, particle physicists have confirmed the standard model, discovering the predicted W and Z bosons in the 1980s, the top quark at Fermilab, and finally the Higgs particle at CERN in 2012.
However, all attempts to find new physics and new particles beyond the standard model since the 1970’s have failed. Particle physicists continue to construct more complex theories that include the standard model such as the Grand Unified Theories (GUTs) of the 1970s that predicted the decay of the proton — never detected. These theories have predicted a long succession of hypothetical particles such as axions, supersymmetric partners, WIMPs (weakly interacting massive particles), other candidates for hypothetical dark matter in cosmology, and many, many more.
These complex beyond the standard model theories keep moving the energy level — usually expressed in billions or trillions of electron volts higher and higher, justifying the research, development, and construction of ever larger and more expensive particle accelerators such as the Tevatron at Fermilab in the United States, the Large Hadron Collider (LHC) at CERN in Switzerland, and the proposed Future Circular Collider (FCC) at CERN.
This lack of success was becoming apparent in the 1980’s when I was studying particle physics at Caltech — I worked briefly on the IMB proton decay experiment which surprise, surprise failed to find the proton decay predicted by the GUTs — and the University of Illinois at Urbana-Champaign on the Stanford Linear Accelerator Center (SLAC)’s disastrous Stanford Linear Collider (SLC) which ran many years over schedule, many millions of dollars over budget, and surprise, surprise discovered nothing beyond the standard model much as Dr. Hossenfelder complains in her recent YouTube video.
Cynical experimental particle physicists would make snide comments about how theory papers kept moving the energy scale for supersymmetry, technicolor, and other popular beyond the standard model theories just above the energy scale of the latest experiments.
Not surprisingly those who clearly perceived this pattern tended to leave the field, most often moving to some form of software development or occasionally other scientific fields. A few found jobs on Wall Street developing models and software for options and other derivative securities.
The second physics bubble burst in about 1993, following the end of the Cold War with huge numbers of freshly minted Ph.D.’s unable to find physics jobs and mostly turning into software developers. The first physics bubble expanded after the launch of Sputnik in 1957 and bust in about 1967. The Reagan administration’s military build-up in the 1980’s fueled another bubble — often unbeknownst to the physics graduate students of the 1980’s.
Dr. Hossenfelder’s recent video, like Lost in Math, focuses on scientific theory and rarely touches on the economic forces that complement and probably drive — consciously or not — both theory and practice independent of actual scientific results.
Scientific research has a high failure rate, sometimes claimed to be eighty to ninety percent when scientists are excusing obvious failures and/or huge cost and schedule overruns — which are common. Even the few successes are often theoretical — better understanding of some physical phenomenon that does not translate into practical results such as new power sources or nuclear weapons for example. But huge experimental mega-projects such as the Large Hadron Collider (LHC) or the Future Circular Collider (FCC), justified by the endless unsuccessful theorizing Dr. Hossenfelder criticizes, are money here and now, jobs for otherwise potentially unemployed physicists, huge construction projects, contracts for research and development of magnets for the accelerators etc.
Big Science creates huge interest groups that perpetuate themselves independent of actual public utility. President Eisenhower identified the problem in his famous Farewell Address in 1961 — best known for popularizing the phrase “military industrial complex.”
Akin to, and largely responsible for the sweeping changes in our industrial-military posture, has been the technological revolution during recent decades.
In this revolution, research has become central; it also becomes more formalized, complex, and costly. A steadily increasing share is conducted for, by, or at the direction of, the Federal government.
Today, the solitary inventor, tinkering in his shop, has been over shadowed by task forces of scientists in laboratories and testing fields. In the same fashion, the free university, historically the fountainhead of free ideas and scientific discovery, has experienced a revolution in the conduct of research. Partly because of the huge costs involved, a government contract becomes virtually a substitute for intellectual curiosity. For every old blackboard there are now hundreds of new electronic computers.
The prospect of domination of the nation’s scholars by Federal employment, project allocations, and the power of money is ever present and is gravely to be regarded.
Yet, in holding scientific research and discovery in respect, as we should, we must also be alert to the equal and opposite danger that public policy could itself become the captive of a scientific-technological elite.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This article takes a first look at historical Presidential approval ratings (approval polls from Gallup and other polling services) from Harry Truman through Joe Biden using our math recognition and automated model fitting technology. Our Math Recognition (MathRec) engine has a large, expanding database of known mathematics and uses AI and pattern recognition technology to identify likely candidate mathematical models for data such as the Presidential Approval ratings data. It then automatically fits these models to the data and provides a ranked list of models ordered by goodness of fit, usually the coefficient of determination or “R Squared” metric. It automates, speeds up, and increases the accuracy of data analysis — finding actionable predictive models for data.
The plots show a model — the blue lines — which “predicts” the approval rating based on unemployment rate (UNRATE), the real inflation adjusted value of gold, and time after the first inauguration of a US President — the so-called honeymoon period. The model “explains” about forty-three (43%) of the variation in the approval ratings. This is the “R Squared” or coefficient of determination for the model. The model has a correlation of about sixty-six percent (0.66) with the actual Presidential approval ratings. Note that a model can have a high correlation with data and yet the coefficient of determination is small.
One might expect US Presidential approval ratings to decline with increasing unemployment and/or an increase in the real value of gold reflecting uncertainty and anxiety over the economy. It is generally thought that new Presidents experience a honeymoon period after first taking office. This seems supported by the historical data, suggesting a honeymoon of about six months — with the possible exception of President Trump in 2017.
The model does not (yet) capture a number of notable historical events that appear to have significantly boosted or reduced the US Presidential approval ratings: the Cuban Missile crisis, the Iran Hostage Crisis, the September 11 attacks, the Watergate scandal, and several others. Public response to dramatic events such as these is variable and hard to predict or model. The public often seems to rally around the President at first and during the early stages of a war, but support may decline sharply as a war drags on and/or serious questions arise regarding the war.
There are, of course, a number of caveats on the data. Presidential approval polls empirically vary by several percentage points today between different polling services. There are several historical cases where pre-election polling predictions were grossly in error including the 2016 US Presidential election. A number of polls called the Dewey-Truman race in 1948 wrong, giving rise to the famous photo of President Truman holding up a copy of the Chicago Tribune announcing Dewey’s election victory.
The input data is from the St. Louis Federal Reserve Federal Reserve Economic Data (FRED) web site, much of it from various government agencies such as unemployment data from the Bureau of Labor Statistics. There is a history of criticism of these numbers. Unemployment and inflation rate numbers often seem lower than my everyday experience. As noted, a number of economists and others have questioned the validity of federal unemployment, inflation and price level, and other economic numbers.
(C) 2022 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
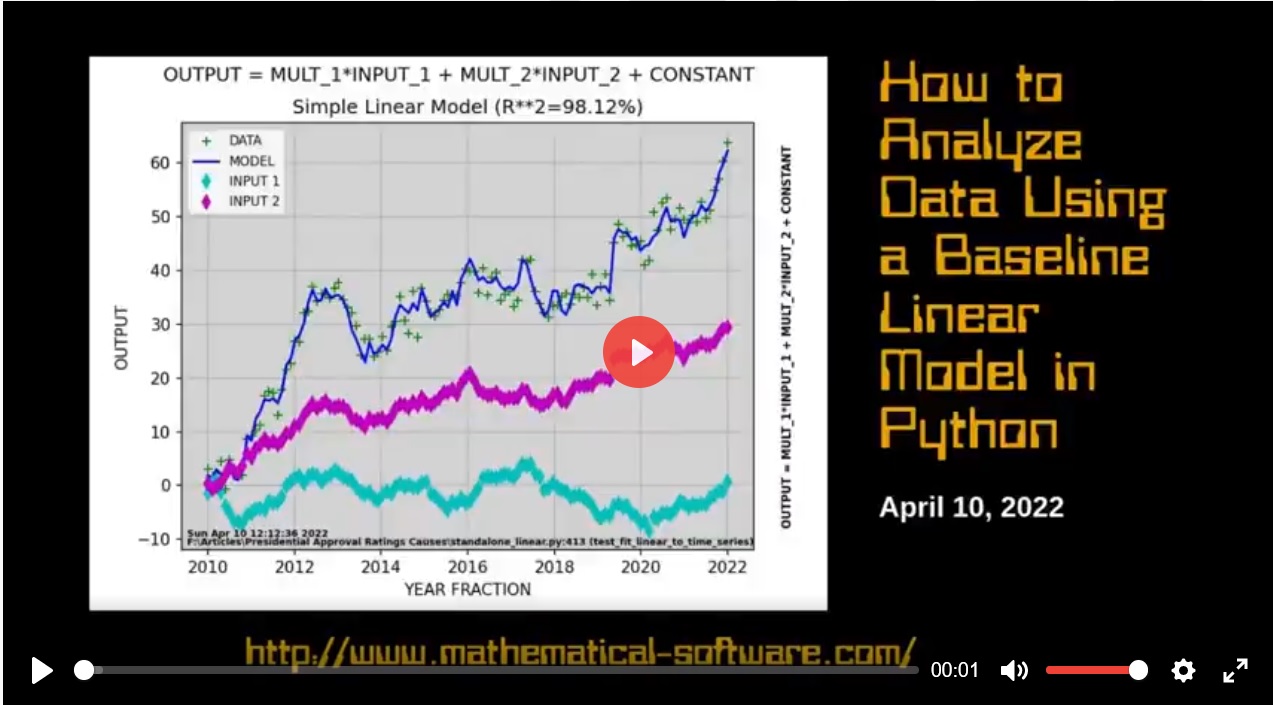
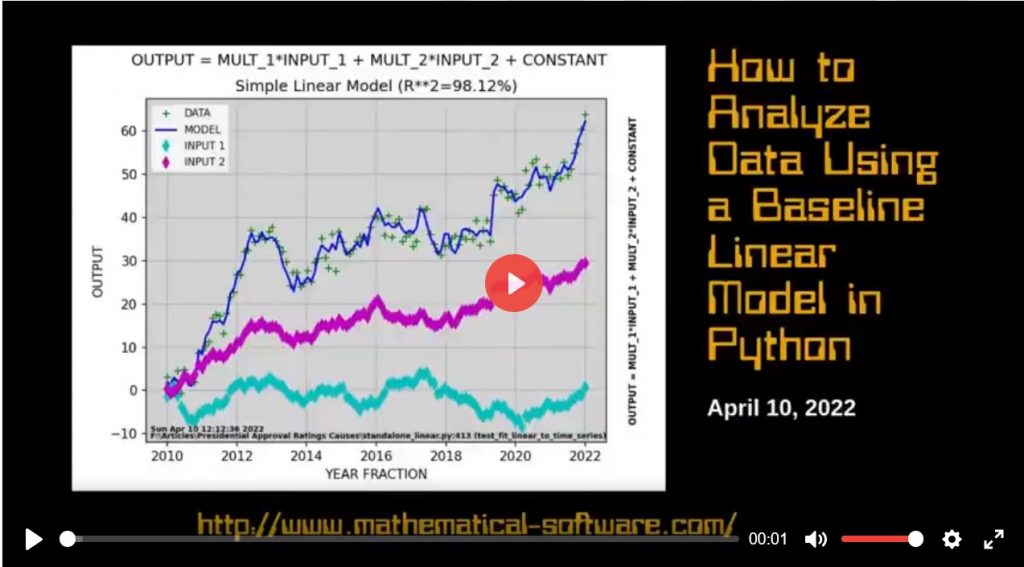
Video on how to analyze data using a baseline linear model in the Python programming language. A baseline linear model is often a good starting point, reference for developing and evaluating more advanced usually non-linear models of data.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
This article shows Python programming language source code to perform a simple linear model analysis of time series data. Most real world data is not linear but a linear model provides a common baseline starting point for comparison of more advanced, generally non-linear models.
Simulated Nearly Linear Data with Linear Model
"""
Standalone linear model example code.
Generate simulated data and fit model to this simulated data.
LINEAR MODEL FORMULA:
OUTPUT = MULT_T*DATE_TIME + MULT_1*INPUT_1 + MULT_2*INPUT_2 + CONSTANT + NOISE
set MULT_T to 0.0 for simulated data. Asterisk * means MULTIPLY
from grade school arithmetic. Python and most programming languages
use * to indicate ordinary multiplication.
(C) 2022 by Mathematical Software Inc.
Point of Contact (POC): John F. McGowan, Ph.D.
E-Mail: ceo@mathematical-software.com
"""
# Python Standard Library
import os
import sys
import time
import datetime
import traceback
import inspect
import glob
# Python add on modules
import numpy as np # NumPy
import pandas as pd # Python Data Analysis Library
import matplotlib.pyplot as plt # MATLAB style plotting
from sklearn.metrics import r2_score # scikit-learn
import statsmodels.api as sm # OLS etc.
# STATSMODELS
#
# statsmodels is a Python module that provides classes and functions for
# the estimation of many different statistical models, as well as for
# conducting statistical tests, and statistical data exploration. An
# extensive list of result statistics are available for each
# estimator. The results are tested against existing statistical
# packages to ensure that they are correct. The package is released
# under the open source Modified BSD (3-clause) license.
# The online documentation is hosted at statsmodels.org.
#
# statsmodels supports specifying models using R-style formulas and pandas DataFrames.
def debug_prefix(stack_index=0):
"""
return <file_name>:<line_number> (<function_name>)
REQUIRES: import inspect
"""
the_stack = inspect.stack()
lineno = the_stack[stack_index + 1].lineno
filename = the_stack[stack_index + 1].filename
function = the_stack[stack_index + 1].function
return (str(filename) + ":"
+ str(lineno)
+ " (" + str(function) + ") ") # debug_prefix()
def is_1d(array_np,
b_trace=False):
"""
check if array_np is 1-d array
Such as array_np.shape: (n,), (1,n), (n,1), (1,1,n) etc.
RETURNS: True or False
TESTING: Use DOS> python -c "from standalone_linear import *;test_is_1d()"
to test this function.
"""
if not isinstance(array_np, np.ndarray):
raise TypeError(debug_prefix() + "argument is type "
+ str(type(array_np))
+ " Expected np.ndarray")
if array_np.ndim == 1:
# array_np.shape == (n,)
return True
elif array_np.ndim > 1:
# (2,3,...)-d array
# with only one axis with more than one element
# such as array_np.shape == (n, 1) etc.
#
# NOTE: np.array.shape is a tuple (not a np.ndarray)
# tuple does not have a shape
#
if b_trace:
print("array_np.shape:", array_np.shape)
print("type(array_np.shape:",
type(array_np.shape))
temp = np.array(array_np.shape) # convert tuple to np.array
reference = np.ones(temp.shape, dtype=int)
if b_trace:
print("reference:", reference)
mask = np.zeros(temp.shape, dtype=bool)
for index, value in enumerate(temp):
if value == 1:
mask[index] = True
if b_trace:
print("mask:", mask)
# number of axes with one element
axes = temp[mask]
if isinstance(axes, np.ndarray):
n_ones = axes.size
else:
n_ones = axes
if n_ones >= (array_np.ndim - 1):
return True
else:
return False
# END is_1d(array_np)
def test_is_1d():
"""
test is_1d(array_np) function works
"""
assert is_1d(np.array([1, 2, 3]))
assert is_1d(np.array([[10, 20, 33.3]]))
assert is_1d(np.array([[1.0], [2.2], [3.34]]))
assert is_1d(np.array([[[1.0], [2.2], [3.3]]]))
assert not is_1d(np.array([[1.1, 2.2], [3.3, 4.4]]))
print(debug_prefix(), "PASSED")
# test_is_1d()
def is_time_column(column_np):
"""
check if column_np is consistent with a time step sequence
with uniform time steps. e.g. [0.0, 0.1, 0.2, 0.3,...]
ARGUMENT: column_np -- np.ndarray with sequence
RETURNS: True or False
"""
if not isinstance(column_np, np.ndarray):
raise TypeError(debug_prefix() + "argument is type "
+ str(type(column_np))
+ " Expected np.ndarray")
if is_1d(column_np):
# verify if time step sequence is nearly uniform
# sequence of time steps such as (0.0, 0.1, 0.2, ...)
#
delta_t = np.zeros(column_np.size-1)
for index, tval in enumerate(column_np.ravel()):
if index > 0:
previous_time = column_np[index-1]
if tval > previous_time:
delta_t[index-1] = tval - previous_time
else:
return False
# now check that time steps are almost the same
delta_t = np.median(delta_t)
delta_range = np.max(delta_t) - np.min(delta_t)
delta_pct = delta_range / delta_t
print(debug_prefix(),
"INFO: delta_pct is:", delta_pct, flush=True)
if delta_pct > 1e-6:
return False
else:
return True # steps are almost the same
else:
raise ValueError(debug_prefix() + "argument has more"
+ " than one (1) dimension. Expected 1-d")
# END is_time_column(array_np)
def validate_time_series(time_series):
"""
validate a time series NumPy array
Should be a 2-D NumPy array (np.ndarray) of float numbers
REQUIRES: import numpy as np
"""
if not isinstance(time_series, np.ndarray):
raise TypeError(debug_prefix(stack_index=1)
+ " time_series is type "
+ str(type(time_series))
+ " Expected np.ndarray")
if not time_series.ndim == 2:
raise TypeError(debug_prefix(stack_index=1)
+ " time_series.ndim is "
+ str(time_series.ndim)
+ " Expected two (2).")
for row in range(time_series.shape[0]):
for col in range(time_series.shape[1]):
value = time_series[row, col]
if not isinstance(value, np.float64):
raise TypeError(debug_prefix(stack_index=1)
+ "time_series[" + str(row)
+ ", " + str(col) + "] is type "
+ str(type(value))
+ " expected float.")
# check if first column is a sequence of nearly uniform time steps
#
if not is_time_column(time_series[:, 0]):
raise TypeError(debug_prefix(stack_index=1)
+ "time_series[:, 0] is not a "
+ "sequence of nearly uniform time steps.")
return True # validate_time_series(...)
def fit_linear_to_time_series(new_series):
"""
Fit multivariate linear model to data. A wrapper
for ordinary least squares (OLS). Include possibility
of direct linear dependence of the output on the date/time.
Mathematical formula:
output = MULT_T*DATE_TIME + MULT_1*INPUT_1 + ... + CONSTANT
ARGUMENTS: new_series -- np.ndarray with two dimensions
with multivariate time series.
Each column is a variable. The
first column is the date/time
as a float value, usually a
fractional year. Final column
is generally the suspected output
or dependent variable.
(time)(input_1)...(output)
RETURNS: fitted_series -- np.ndarray with two dimensions
and two columns: (date/time) (output
of fitted model)
results --
statsmodels.regression.linear_model.RegressionResults
REQUIRES: import numpy as np
import pandas as pd
import statsmodels.api as sm # OLS etc.
(C) 2022 by Mathematical Software Inc.
"""
validate_time_series(new_series)
#
# a data frame is a package for a set of numbers
# that includes key information such as column names,
# units etc.
#
input_data_df = pd.DataFrame(new_series[:, :-1])
input_data_df = sm.add_constant(input_data_df)
output_data_df = pd.DataFrame(new_series[:, -1])
# statsmodels Ordinary Least Squares (OLS)
model = sm.OLS(output_data_df, input_data_df)
results = model.fit() # fit linear model to the data
print(results.summary()) # print summary of results
# with fit parameters, goodness
# of fit statistics etc.
# compute fitted model values for comparison to data
#
fitted_values_df = results.predict(input_data_df)
fitted_series = np.vstack((new_series[:, 0],
fitted_values_df.values)).transpose()
assert fitted_series.shape[1] == 2, \
str(fitted_series.shape[1]) + " columns, expected two(2)."
validate_time_series(fitted_series)
return fitted_series, results # fit_linear_to_time_series(...)
def test_fit_linear_to_time_series():
"""
simple test of fitting a linear model to simple
simulated data.
ACTION: Displays plot comparing data to the linear model.
REQUIRES: import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics impor r2_score (scikit-learn)
NOTE: In mathematics a function f(x) is linear if:
f(x + y) = f(x) + f(y) # function of sum of two inputs
# is sum of function of each input value
f(a*x) = a*f(x) # function of constant multiplied by
# an input is the same constant
# multiplied by the function of the
# input value
(C) 2022 by Mathematical Software Inc.
"""
# simulate monthly data for years 2010 to 2021
time_steps = np.linspace(2010.0, 2022.0, 120)
#
# set random number generator "seed"
#
np.random.seed(375123) # make test reproducible
# make random walks for the input values
input_1 = np.cumsum(np.random.normal(size=time_steps.shape))
input_2 = np.cumsum(np.random.normal(size=time_steps.shape))
# often awe inspiring Greek letters (alpha, beta,...)
mult_1 = 1.0 # coefficient or multiplier for input_1
mult_2 = 2.0 # coefficient or multiplier for input_2
constant = 3.0 # constant value (sometimes "pedestal" or "offset")
# simple linear model
output = mult_1*input_1 + mult_2*input_2 + constant
# add some simulated noise
noise = np.random.normal(loc=0.0,
scale=2.0,
size=time_steps.shape)
output = output + noise
# bundle the series into a single multivariate time series
data_series = np.vstack((time_steps,
input_1,
input_2,
output)).transpose()
#
# np.vstack((array1, array2)) vertically stacks
# array1 on top of array 2:
#
# (array 1)
# (array 2)
#
# transpose() to convert rows to vertical columns
#
# data_series has rows:
# (date_time, input_1, input_2, output)
# ...
#
# the model fit will estimate the values for the
# linear model parameters MULT_T, MULT_1, and MULT_2
fitted_series, \
fit_results = fit_linear_to_time_series(data_series)
assert fitted_series.shape[1] == 2, "wrong number of columns"
model_output = fitted_series[:, 1].flatten()
#
# Is the model "good enough" for practical use?
#
# Compure R-SQUARED also known as R**2
# coefficient of determination, a goodness of fit measure
# roughly percent agreement between data and model
#
r2 = r2_score(output, # ground truth / data
model_output # predicted values
)
#
# Plot data and model predictions
#
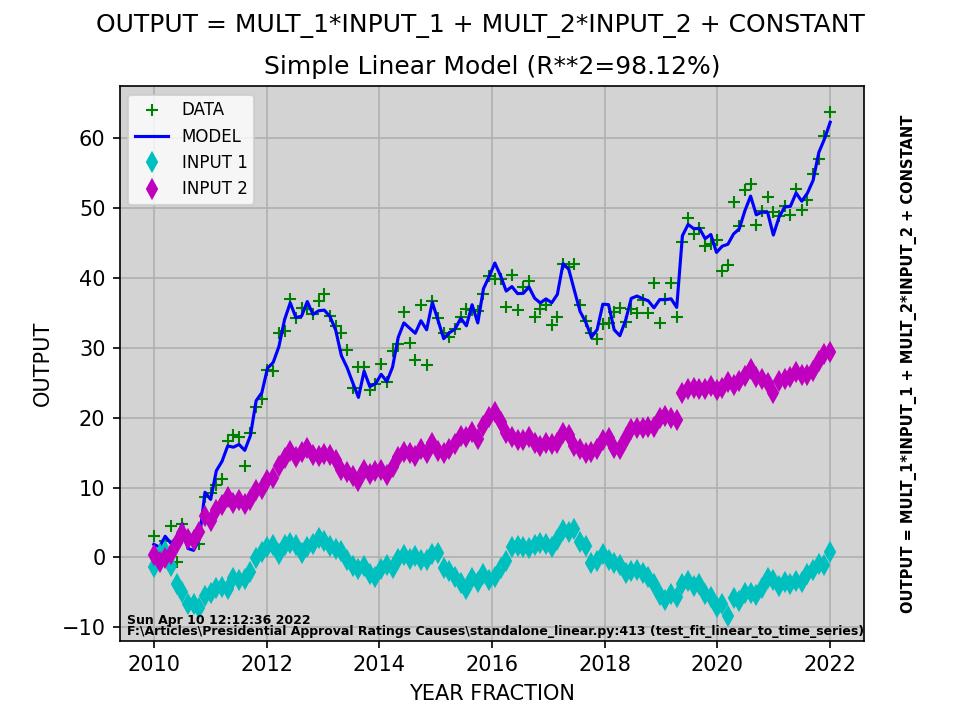
model_str = "OUTPUT = MULT_1*INPUT_1 + MULT_2*INPUT_2 + CONSTANT"
f1 = plt.figure()
# set light gray background for plot
# must do this at start after plt.figure() call for some
# reason
#
ax = plt.axes() # get plot axes
ax.set_facecolor("lightgray") # confusingly use set_facecolor(...)
# plt.ylim((ylow, yhi)) # debug code
plt.plot(time_steps, output, 'g+', label='DATA')
plt.plot(time_steps, model_output, 'b-', label='MODEL')
plt.plot(time_steps, data_series[:, 1], 'cd', label='INPUT 1')
plt.plot(time_steps, data_series[:, 2], 'md', label='INPUT 2')
plt.suptitle(model_str)
plt.title(f"Simple Linear Model (R**2={100*r2:.2f}%)")
ax.text(1.05, 0.5,
model_str,
rotation=90, size=7, weight='bold',
ha='left', va='center', transform=ax.transAxes)
ax.text(0.01, 0.01,
debug_prefix(),
color='black',
weight='bold',
size=6,
transform=ax.transAxes)
ax.text(0.01, 0.03,
time.ctime(),
color='black',
weight='bold',
size=6,
transform=ax.transAxes)
plt.xlabel("YEAR FRACTION")
plt.ylabel("OUTPUT")
plt.legend(fontsize=8)
# add major grid lines
plt.grid()
plt.show()
image_file = "test_fit_linear_to_time_series.jpg"
if os.path.isfile(image_file):
print("WARNING: removing old image file:",
image_file)
os.remove(image_file)
f1.savefig(image_file,
dpi=150)
if os.path.isfile(image_file):
print("Wrote plot image to:",
image_file)
# END test_fit_linear_to_time_series()
if __name__ == "__main__":
# MAIN PROGRAM
test_fit_linear_to_time_series() # test linear model fit
print(debug_prefix(), time.ctime(), "ALL DONE!")
(C) 2022 by John F. McGowan, Ph.D.
About Me
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
The Election and the Missing Error Bars on COVID and Flu Death Numbers
A video on the grossly contradictory CDC FluView pneumonia and influenza death numbers, implied to be influenza virus death numbers, and the CDC Leading causes of death report pneumonia and influenza death numbers, which differ by over a factor of THREE, the lack of reported error bars on the CDC flu and COVID death number counts, required by standard scientific practice, and the effect of this on the US Presidential election.
The FluView web site claims six to ten percent of all deaths are pneumonia and influenza in a prominently displayed graphic. However, the Leading Causes of Death report claims about two percent of deaths are caused by pneumonia and influenza, less than one third of the percentages reported on the FluView web site. No error bars are reported on these numbers.
Looking at the numbers behind the percentages. The CDC uses two grossly contradictory numbers of annual deaths from pneumonia and influenza: about 55,000 in the annual leading causes of the death report and about 188,000 in National Center for Health Statistics (NCHS) data used on the FluView web site to report the percentage of deaths each week due to pneumonia and influenza. These differ by a factor of OVER THREE. The larger FluView number is comparable to the current cumulative total COVID-19 deaths in the United States frequently cited by the media and compared to a smaller number of about 40,000 “flu deaths.”
O Use of the flu death numbers in popular reporting on COVID and the election, usually lacking any error bars, is discussed.
o The CDC’s mysterious “flu death” mathematical model — a theory — assigning about 50,000 deaths per year to the influenza virus, mostly pneumonia deaths that lack a laboratory confirmed influenza infection, and the usually unreported errors on the output of this model is discussed.
o Evidence of large uncertainties in the assignment of cause of death by doctors, coroners and others is discussed. The lack of proper error bars due to this on both reported “flu death” numbers and COVID death numbers.
o Specific reasons why the CDC would likely be biased against President Trump due to his criticism of vaccine safety and historical statements on the possible role of childhood vaccines promoted by the CDC in causing autism are discussed.
Subscribers gain access to the advanced professional features of our censored search web site and service — censored-search.com — a search engine for censored Internet content banned or shadow-banned by increasingly censored, advertising beholden social media and search engines such as Google, YouTube, and Facebook. The free version of censored-search.com — available to all — uses a modified page rank algorithm, essentially a popularity contest. The paid professional version includes advanced search algorithms to find and prioritize content that is probably being censored by vested interests because it is useful and true — for example, evidence that a product or service is harmful to users.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
As of March 21, 2020, the United States Centers for Disease Control (CDC) has posted weekly death numbers for pneumonia and influenza (P&I) that are substantially lower than the weekly death numbers for the matching weeks last year (2019) despite the Coronavirus COVID-19 Pandemic. This is remarkable given that with the lack of widespread testing many deaths caused by the pandemic would be expected to appear as a surge in deaths attributed to pneumonia and influenza. One can also argue that deaths caused by COVID-19, where known, should be included in the pneumonia and influenza death tally as well.
NOTE: The latest numbers, through the week ending March 21, 2020, were posted last Friday, April 3, 2020.
The weekly numbers for 2017 and previous years also sum to a total number of annual deaths due to pneumonia and influenza that is about three times larger than the widely quoted numbers from the 2017 and earlier leading causes of death reports.
I have done a number of video posts on the seeming absence of COVID-19 from reports through March 21, 2020. Remarkably the latest raw (?) data file NCHSData13.csv from https://www.cdc.gov/flu/weekly/#S2 (click on View Chart Data below the plot) shows total 40,002 deaths in week 12 of 2020 and 57,086 total deaths in week 12 of 2019 (see screenshot below) — much lower in 2020 despite the pandemic. The file shows total pneumonia and influenza deaths of 3,261 in week 12 of 2020 and 4,276 deaths in week 12 of 2019 (last year). Again many more deaths last year.
CDC Pneumonia and Influenza Deaths File NCHSData13.csv
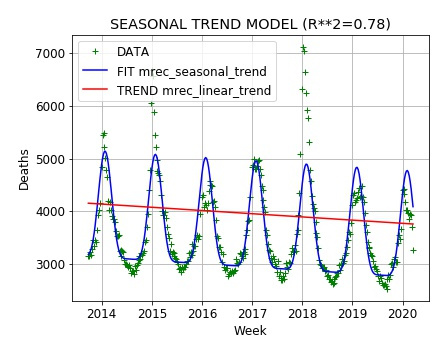
Remarkably the weekly death numbers attributed to pneumonia and influenza have been running below last year’s numbers for the same weeks for almost all weeks since the beginning of 2020 and well below what might be expected from simple modeling of the long term trend and seasonal variation.
In the plot below, the green plus signs are the data from the NCHSData13.csv file. The red line is the long term trend and the blue line if the full model with a roughly sinusoidal model of the seasonal variation in deaths added. One can see that the weekly death numbers are lower this year than last year and also fall well below the model prediction.
US Centers for Disease Control (CDC) Weekly Deaths from Pneumonia and Influenza (to March 21, 2020)
There are many possible explanations for this remarkable shortfall in deaths. No doubt the CDC is fielding hard questions from web site visitors, analysts, and others. Fox News host Tucker Carlson included the discrepancy in his commentary on the COVID-19 crisis on April 7 (from 3:24 to 3:50 in the linked video):
Tucker Carlson Highlights the CDC P and I Deaths Anomaly
The CDC appears to have updated its FluView web site with information on how complete the numbers for the last three weeks are — how many death certificates have been collected. They appear to have added a table at the bottom with the weekly numbers:
CDC FluView Table on Pneumonia and Influenza Deaths (AT BOTTOM)
The final right-most column labeled “Percent Complete” seems to refer to how complete the numbers are, although this is not clear. Hovering the mouse pointer over the question mark to the right of “Percent Complete” brings up a legal disclaimer and not a clear explanation of what “Percent Complete” means. The final week (week 12, ending March 21, 2020) is listed as 85.4 % complete. Oddly, the previous two weeks (week 10 and week 11) are listed as (> 100 %) complete — note the greater than sign. Since one-hundred percent (100%) means COMPLETE, it is especially difficult to understand the use of the greater than sign > in the table. 🙂
In the FluView application/web page (today, April 9, 2020) the CDC seems to be claiming the numbers up to week 11 ending March 14, 2020 are in fact complete. The remarkable absence of COVID-19 deaths up to March 14, 2020 cannot be attributed to delays in collecting and processing death certificates or reports. A number of legal disclaimers such as the popup shown seem to have appeared recently (last few days) on the CDC web site.
As I have noted there are many possible explanations for this remarkable reported decline in deaths during a purported pandemic. It may be that people have been extra careful during the pandemic, staying home, avoiding risky behaviors, thus resulting in a drop in deaths both in general and from pneumonia and influenza causes other than COVID-19. It could be there are errors or omissions caused by the crisis response that are making the numbers unreliable. It could be pneumonia and influenza deaths from other causes are being incorrectly labeled as COVID-19 and omitted from the numbers; this is why it would be best to include COVID-19 as part of the P&I deaths. It could be that COVID-19, despite the headlines, is not unusually deadly.
NOTE: Total deaths in Europe have risen sharply in the latest weekly numbers from EuropMOMO, consistent with an unusually deadly new cause of death, after many weeks of remarkably showing no sign of the COVID-19 pandemic.
The CDC Weekly Pneumonia and Influenza Death Numbers are Three Times the Widely Reported Annual Death Numbers
Astonishingly the weekly death numbers in the NCHSData13.csv file — which go back to 2013 as shown in the plot above — indicate that about three times as many people in the United States have died from pneumonia and influenza in 2017 and preceding years as reported in the National Vital Statistics.
For example, the National Vital Statistics Report Volume 69, Number 8 dated June 24, 2019: “Deaths: Final Data for 2017” gives 55,672 deaths from “Influenza and pneumonia” in its table (Table B) of leading causes of deaths. “Influenza and pneumonia” is the eighth leading cause of death in 2017.
Death: Final Data for 2017Leading Causes of Death Table (2017)
Note that the report uses the phrase “Influenza and pneumonia” whereas the weekly death web site uses the language “Pneumonia and influenza (P&I)”. As I will explain below this may be a clue to the reason for the huge discrepancy.
In contrast, summing the weekly death numbers for 2017 in NCHSData13.csv gives 188,286 deaths for the entire year. This is OVER three times the number in the “Deaths: Final Data for 2017” (June 24, 2019).
It is worth noting that the web site, the NCHSData13.csv file, and the report appear intended for the general public, in part for educational and informational purposes — as well as doctors and other professionals who have limited time to dig into the numbers. Most people would interpret deaths due to “Influenza and pneumonia” in one report as the same or nearly the same (except for minor technical issues) number as “Pneumonia and influenza” in another report, data file, or web site.
What gives?
In 2005, Peter Doshi, an associate editor with the British Medical Journal (BMJ), one of the most prestigious medical journals in the world, wrote a highly critical, though short, article on the CDC’s pneumonia and influenza numbers: “Are US flu death figures more PR than science?”
BMJ. 2005 Dec 10; 331(7529): 1412. PMCID: PMC1309667
US data on influenza deaths are a mess. The Centers for Disease Control and Prevention (CDC) acknowledges a difference between flu death and flu associated death yet uses the terms interchangeably. Additionally, there are significant statistical incompatibilities between official estimates and national vital statistics data. Compounding these problems is a marketing of fear—a CDC communications strategy in which medical experts “predict dire outcomes” during flu seasons.
The CDC website states what has become commonly accepted and widely reported in the lay and scientific press: annually “about 36 000 [Americans] die from flu” (www.cdc.gov/flu/about/disease.htm) and “influenza/pneumonia” is the seventh leading cause of death in the United States (www.cdc.gov/nchs/fastats/lcod.htm). But why are flu and pneumonia bundled together? Is the relationship so strong or unique to warrant characterising them as a single cause of death?
BMJ. 2005 Dec 10; 331(7529): 1412. PMCID: PMC1309667
Peter Doshi goes on in this vein for a couple of pages (see the linked article above). Peter Doshi and other sources online seem to suggest that CDC estimates a large number of pneumonia deaths that are attributed to secondary effects of influenza such as a bacterial pneumonia infection caused by influenza. Influenza is rarely detected in actual tests of actual patients and only a small fraction of deaths reported in the weekly statistics are attributed in NCHSData13.csv to influenza (the virus, NOT “flu” as used in popular language which can mean any disease with similar symptoms to influenza — the scientific term).
The influenza and pneumonia deaths number in the National Vital Statistics Report may be this estimate that Doshi is describing in his critical article in the BMJ. The other (many more!) weekly “pneumonia and influenza” deaths presumably are assigned to some other categories in the annual leading causes of death report.
Presumably CDC can give some explanation for this vast discrepancy between two numbers that most of us would expect to be the same. “Influenza and pneumonia” and “pneumonia and influenza” mean the same thing in common English usage. They almost certainly mean the same thing to most doctors and other health professionals as well.
Conclusion
These pneumonia and influenza death numbers need to be clarified in an open and transparent manner. The next set of numbers will probably be posted tomorrow Friday April 10, 2020. Hopefully these new numbers and accompanying commentary will explain the situation in an open and transparent manner that survives critical scrutiny.
The proper response to the COVID-19 pandemic depends on knowing a range of parameters including the actual mortality rate broken down by age, sex, race, obesity, other medical conditions, whatever can be measured quickly and accurately. The actual rates and modes of transmission. The false positive and false negative rates for the various tests, both for active infection and past infection. These are mostly not known.
Most of us are experiencing the instinctive fight or flight response which degrades higher cognitive function, aggravated by the 24/7 Internet/social media fear barrage. It is important to calm down, collect actual data in a genuinely open, transparent way that will yield broad public support, and think carefully.
UPDATE (February 13, 2021):
We have received some questions about more up to date information on the issues raised in this article. Our most recent and comprehensive article on the CDC’s historical influenza and pneumonia death numbers and their current COVID-19 death numbers is:
This article argues that the US Centers for Disease Control (CDC)’s April 2020 guidance for filling out death certificates for possible COVID-19 related deaths strongly encourages, if not requires, assigning COVID-19 as the underlying cause of death (UCOD) in any death where COVID-19 or the SARS-COV-2 virus may be present, which appears to differ from common historical practice for pneumonia and influenza deaths where pneumonia was frequently treated as a “complication,” a cause of death but not the underlying cause of death.
This means the number of COVID deaths should be compared to a count of death certificates where pneumonia and influenza were listed as a cause of death or even a lesser contributing factor, a historical number which appears to have been at least 188,000 per year based on the CDC FluView web site. The proper comparison number may be even larger if deaths that historically were listed as heart attacks, cancer or other causes than pneumonia or influenza are also being reassigned due to the April 2020 guidance.
Here are some earlier articles and references:
This is a more recent article/video on the long standing problems with the pneumonia and influenza death numbers:
“How Reliable are the US Centers for Disease Control’s Death Numbers” (October 14, 2020)
The second article on the Santa Clara County death numbers includes a detailed section on the changes in the standard on assigning the underlying cause of death for COVID cases from the CDC’s April 2020 “guidance” document, which probably boost the COVID death numbers substantially. This section is broken out and edited into this article:
We are looking at the CDC’s excess death numbers which appear to be highly questionable. The CDC follows a non-standard procedure of zeroing out data points that are negative in summing the excess deaths. See this article by Tam Hunt:
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
An analysis of the latest weekly death numbers from the Centers for Disease Control (CDC) and the National Center for Health Statistics (NCHS) from the week ending March 21, 2020 and posted on the CDC Web Site on Friday, April 3, 2020
Doomsday Virus? Coronavirus cases are NOT boosting the weekly death numbers for pneumonia and influenza from the CDC and National Center for Health Statistics yet. This would be expected if the coronavirus (SARS-Cov-2) is unusually deadly compared to other diseases that contribute to deaths categorized as pneumonia and influenza… YET! (Based on data through March 21, 2020)
CDC Pneumonia and Influenza Mortality Surveillance: https://www.cdc.gov/flu/weekly/#S2
Credit: Pete Linforth by way of Pixabay for the background image of the coronavirus.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
Doomsday Virus? Coronavirus Cases NOT Boosting Weekly Death Numbers…YET
Doomsday Virus? Coronavirus cases are NOT boosting the weekly death numbers for pneumonia and influenza from the CDC and National Center for Health Statistics yet. This would be expected if the coronavirus is unusually deadly compared to other diseases that contribute to deaths categorized as pneumonia and influenza… YET! (Based on data through March 14, 2020)
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).
DNA ancestry tests are tests marketed by genetic testing firms such as 23andme , Ancestry.com , Family Tree DNA, and National Geographic Geno as well as various consultants and academic researchers that purport to give the percentage of ancestry of a customer from various races, ethnic groups, and nationalities. They have been marketed to African-Americans to supposedly locate their ancestors in Africa (e.g. Ghana versus Mozambique) and many other groups with serious questions about their family history and background.
It is difficult (perhaps impossible) to find detailed information on the accuracy and reliability of the DNA ancestry kits on the web sites of major home DNA testing companies such as 23andMe. The examples shown on the web sites usually show only point estimates of ancestry percentages without errors. This is not common scientific practice where numbers should always be reported with errors (e.g. ±0.5 percent). The lack of reported errors on the percentages implies no significant errors are present; any error is less than the least significant reported digit (a tenth of one percent here).
Point Estimates of Ancestry Percentages from 23andMe web site (screen capture on Feb. 14, 2019)
The terms of service on the web sites often contain broad disclaimers:
The laboratory may not be able to process your sample, and the laboratory process may result in errors. The laboratory may not be able to process your sample up to 3.0% of the time if your saliva does not contain a sufficient volume of DNA, you do not provide enough saliva, or the results from processing do not meet our standards for accuracy.* If the initial processing fails for any of these reasons, 23andMe will reprocess the same sample at no charge to the user. If the second attempt to process the same sample fails, 23andMe will offer to send another kit to the user to collect a second sample at no charge. If the user sends another sample and 23andMe’s attempts to process the second sample are unsuccessful, (up to 0.35% of all samples fail the second attempt at testing according to 23andMe data obtained in 2014 for all genotype testing),* 23andMe will not send additional sample collection kits and the user will be entitled solely and exclusively to a complete refund of the amount paid to 23andMe, less shipping and handling, provided the user shall not resubmit another sample through a future purchase of the service. If the user breaches this policy agreement and resubmits another sample through a future purchase of the service and processing is not successful, 23andMe will not offer to reprocess the sample or provide the user a refund. Even for processing that meets our high standards, a small, unknown fraction of the data generated during the laboratory process may be un-interpretable or incorrect (referred to as “Errors”). As this possibility is known in advance, users are not entitled to refunds where these Errors occur.
“A small, unknown fraction” can mean ten percent or even more in common English usage. No numerical upper bound is given. Presumably, “un-interpretable” results can be detected and the customer notified that an “Error” occurred. The Terms of Service does not actually say that this will happen.
Nothing indicates the “incorrect” results can be detected and won’t be sent to the customer. It is not clear whether “data generated during the laboratory process” includes the ancestry percentages reported to customers.
On January 18, 2019 the CBC (Canadian Broadcasting Corporation) ran a news segment detailing the conflicting results from sending a reporter and her identical twin sister’s DNA to several major DNA ancestry testing companies: “Twins get some ‘mystifying’ results when they put 5 DNA Ancestry Kits to the test.” These included significant — several percent — differences in reported ancestry between different companies and significant differences in reported ancestry between the two twins at the same DNA testing company! The identical twins have almost the same DNA.
The major DNA ancestry testing companies such as 23andMe may argue that they have millions of satisfied customers and these reports are infrequent exceptions. This excuse is difficult to evaluate since the companies keep their databases and algorithms secret, the ground truth in many cases is unknown, and many customers have only a passing “recreational” interest in the results.
Where the interest in the DNA ancestry results is more serious customers should receive a very high level of accuracy with the errors clearly stated. Forensic DNA tests used in capital offenses and paternity tests are generally marketed with claims of astronomical accuracy (chances of a wrong result being one in a billion or trillion). In fact, errors have occurred in both forensic DNA tests and paternity tests, usually attributed to sample contamination.
How Accurate are DNA Ancestry Tests?
DNA ancestry tests are often discussed as if the DNA in our cells comes with tiny molecular barcodes attached identifying some DNA as black, white, Irish, Thai and so forth. News reports and articles speak glibly of “Indian DNA” or “Asian DNA”. It sounds like DNA ancestry tests simply find the barcoded DNA and count how much is in the customer’s DNA.
The critical point, which is often unclear to users of the tests, is that the DNA ancestry test results are estimates based on statistical models of the frequency of genes and genetic markers in populations. Red hair gives a simple, visible example. Red hair is widely distributed. There are people with red hair in Europe, Central Asia, and even Middle Eastern countries such as Iran, Iraq and Afghanistan. There were people with red hair in western China in ancient times. There are people with red hair in Polynesia and Melanesia!
However red hair is unusually common in Ireland, Scotland, and Wales with about 12-13% of people having red hair. It is estimated about forty percent of people in Ireland, Scotland, and Wales carry at least one copy of the variant M1CR gene that seems to be the primary cause of most red hair. Note that variations in other genes are also believed to cause red hair. Not everyone with red hair has the variation in M1CR thought to be the primary cause of red hair. Thus, if someone has red hair (or the variant M1CR gene common in people with red hair), we can guess they have Irish, Scottish, or Welsh ancestry and we will be right very often.
Suppose we combine the red hair with traits — genes or genetic markers in general — that are more common in people of Irish, Scottish or Welsh descent than in other groups. Then we can be more confident that someone has Irish, Scottish, or Welsh ancestry than using red hair or the M1CR gene alone. In general, even with many such traits or genes we cannot be absolutely certain.
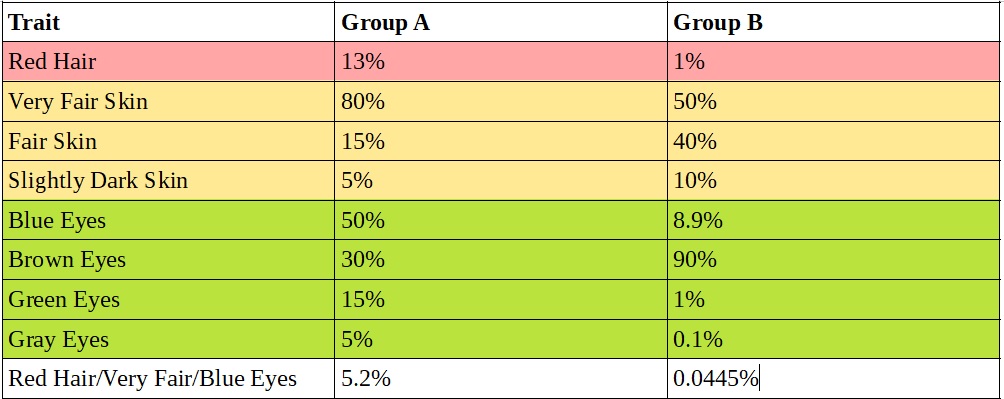
To make combining multiple traits or genes more concrete, let’s consider two groups (A and B) with different frequencies of common features. Group A is similar to the Irish, Scots, and Welsh with thirteen percent having red hair. Group A is more southern European with only one percent having red hair. The distributions of skin tone differ with Group A having eighty percent with very fair skin versus only fifty percent in Group B. Similarly blue eyes are much more common in Group A: fifty percent in group A and only 8.9 percent in group B. To make the analysis and computations simple, Groups A and B have the same number of members — one million.
For illustrative purposes only, we are assuming the traits are uncorrelated. In reality, red hair is correlated with very fair skin and freckles.
Estimating Group Membership from Multiple Traits
Using hair color alone, someone with red hair has a 13/(13+1=14) or 95.86% chance of belonging to group A. Using hair color, skin tone, and eye color, someone with red hair and very fair skin and blue eyes has a 5.2/(5.2+0.0445=5.2445) or 99.14% chance of belonging to group A.
Combining multiple traits (or genes and genetic markers) increases our confidence in the estimate of group membership but it cannot give an absolute definitive answer unless at least one trait (or gene or genetic marker) is unique to one group. This “barcode” trait or gene is a unique identifier for group membership.
Few genes or genetic markers have been identified that correlate strongly with our concepts of race, ethnicity, or nationality. One of the most well known and highly correlated examples is the Duffynull allele which is found in about ninety percent of Sub-Saharan Africans and is quite rare outside of Sub-Saharan Africa. The Duffy allele is thought to provide some resistance to vivax malaria.
Nonetheless, white people with no known African ancestry are sometimes encountered with the Duffy allele. This is often taken as indicating undocumented African ancestry, but we don’t really know. At least anecdotally, it is not uncommon for large surveys of European ancestry populations to turn up a few people with genes or genetic markers like the Duffy allele that are rare in Europe but common in Africa or Polynesia or other distant regions.
A More Realistic Example
The Duffy null allele and the variant M1CR gene that is supposed to be the cause of most red hair are unusually highly correlated with group membership. For illustrative purposes, let’s consider a model of combining multiple genes to identify group membership that may be more like the real situation.
Let’s consider a collection of one hundred genes. For example these could be genes that determine skin tone. Each gene has a light skin tone and a dark skin tone variant. The more dark skin tone variants someone has, the darker their skin tone. For bookkeeping we label the the light skin tone gene variants L1 through L100 and the dark skin tone genes variants D1 through D100.
Group A has a ten percent (1 in 10) chance of having the dark skin variant of each gene. On average, a member of group A has ninety (90) of the light skin tone variants and ten (10) of the dark skin variants. Group A may be somewhat like Northern Europeans.
Group B has a thirty percent (about 1 in 3) chance of having the dark skin variant of each gene. On average, a member of group B has seventy (70) of the light skin variants and thirty (30) of the dark skin variants. Group B may be somewhat like Mediterranean or some East Asian populations.
Notice that none of the gene variants is at all unique or nearly unique to either group. None of them acts like the M1CR variant associated with red hair, let alone the Duffy null allele. Nonetheless a genetic test can distinguish between membership in group A and group B with high confidence.
Group A versus Group B
Group A members have on average ten (10) dark skin variants with a standard deviation of three (3). This means ninety-five percent (95%) of Group A members will have between four (4) and sixteen (16) of the dark skin variant genes.
Group B members have on average thirty (30) dark skin variants with a standard deviation of about 4.6. This means about ninety-five percent (95%) of Group B members will have between twenty-one (21) and thirty-nine (39) dark skin variants.
In most cases, counting the number of dark skin variants that a person possesses will give over a ninety-five percent (95%) confidence level as to their group membership.
Someone with a parent from Group A and a parent from group B will fall smack in the middle, with an average of twenty (20) dark skin gene variants. Based on the genetic testing alone, they could be an unusually dark skinned member of Group A, an unusually light skinned member of Group B, or someone of mixed ancestry.
Someone with one grandparent from Group B and three grandparents from Group A would have fifteen (15) dark skin gene variants in their DNA, falling within two standard deviations of the Group A average. At least two percent (2%) of the members of Group A will have a darker skin tone than this person. Within just a few generations we lose the ability to detect Group B ancestry!
In the real world, each gene will have different variant frequencies, not ten percent versus thirty percent for every one, making the real world probability computations much more complicated.
The Out of Africa Hypothesis
The dominant hypothesis of human origins is that all humans are descended from an original population of early humans in Africa, where most early fossil remains of human and pre-human hominids have been found. According to this theory, the current populations in Europe, Asia, the Pacific Islands, and the Americas are descended from small populations that migrated out of Africa relatively recently in evolutionary terms — fifty-thousand to two-hundred thousand years ago depending on the variant of the theory. Not a lot of time for significant mutations to occur. Thus our ancestors may have started out with very similar frequencies of various traits, genes, and genetic markers. Selection pressures caused changes in the frequency of the genes (along with occasional mutations), notably selecting for lighter skin in northern climates.
Thus all races and groups may contain from very ancient times some people with traits, genes and genetic markers from Africa that have become more common in some regions and less common in other regions. Quite possibly the original founding populations included some members with the Duffy allele which increased in prevalence in Africa and remained rare or decreased in the other populations. Thus the presence of the Duffy allele or other rare genes or genetic markers does not necessarily indicate undocumented modern African ancestry — although it surely does in many cases.
Racially Identifying Characteristics Are Caused By Multiple Genes
The physical characteristics used to identify races such as skin tone, the extremely curly hair among most black Africans, and the epicanthic folds in East Asians (Orientals) that give the distinctive “slant” eyed appearance with the fold frequently covering the interior corner of the eye appear to be caused by multiple genes rather than a single “barcode” racial gene. Several genes work together to determine skin tone in ways that are not fully understood. Thus children of a light skinned parent and a dark skinned parent generally fall somewhere on the spectrum between the two skin tones.
Racially identifying physical characteristics are subject to blending inheritance and generally dilute away with repeated intermixing with another race as is clearly visible in many American Indians with well documented heavy European ancestry as for example the famous Cherokee chief John Ross:
The Cherokee Chief John Ross (1790-1866)
Would a modern DNA ancestry test have correctly detected John Ross’s American Indian ancestry?
There are also many examples of people with recent East Asian ancestry who nonetheless look entirely or mostly European. These include the actresses Phoebe Cates (Chinese-Filipino grandfather), Meg Tilly (Margaret Elizabeth Chan, Chinese father), and Kristin Kreuk (Smallville, Chinese mother). Note that none of these examples has an epicanthic fold that cover the interior corner of the eyes. Especially since these are performers, the possibility of unreported cosmetic surgery cannot be ignored, but it is common for the folds to disappear or be greatly moderated in just one generation — no longer covering the interior corner of the eye for example.
How well do the DNA ancestry tests work for European looking people with well-documented East Asian ancestry, even a parent?
There are also examples of people with recent well-documented African, Afro-Carribean, or African-American ancestry who look very European. The best-selling author Malcolm Gladwell has an English father and a Jamaican mother. By his own account, his mother has some white ancestry. His hair is unusually curly and I suspect an expert in hair could distinguish it from unusually curly European hair.
In fact, some (not all) of the genes that cause racially identifying physical characteristics may be relatively “common” in other races, not extremely rare like the Duffy allele. For example, a few percent of Northern Europeans, particularly some Scandinavians, have folds around the eyes similar to East Asians, although the fully developed fold covering the interior corner of the eye is rare. Some people in Finland look remarkably Asian although they are generally distinguishable from true Asians. This is often attributed to Sami ancestry, although other theories include the Mongol invasions of the thirteenth century, the Hun invasions of the fifth century, other unknown migrations from the east, and captives brought back from North America or Central Asia by Viking raiders.
There is a lot of speculation on-line that Björk has Inuit ancestry and she has performed with Inuit musicians, but there appears to be no evidence of this. As noted above, a small minority of Scandinavians have epicanthic folds and other stereotypically Asian features.
The epicanthic fold is often thought to be an adaptation to the harsh northern climate with East Asians then migrating south into warmer regions. It is worth noting that the epicanthic fold and other “East Asian” eye features are found in some Africans. The “Out of Africa” explanation for milder forms of this feature in some northern Europeans is some early Europeans carried the traits with them from Africa and it was selected for in the harsh northern climate of Scandinavia and nearby regions, just as may have happened to a much greater extent in East Asia.
The critical point is that at present DNA ancestry tests — which are generally secret proprietary algorithms — are almost certainly using relative frequencies of various genes and genetic markers in different populations rather than a mythical genetic barcode that uniquely identifies the race, ethnicity, or nationality of the customer or his/her ancestors.
Hill Climbing Algorithms Can Give Unpredictable Results
In data analysis, it is common to use hill-climbing algorithms to “fit” models to data. A hill climbing algorithm starts at an educated or sometimes completely random guess as to the right result, searches nearby, and moves to the best result found in the neighborhood. It repeats the process until it reaches the top of a hill. It is not unlikely that some of the DNA ancestry tests are using hill climbing algorithms to find the “best” guess as to the ancestry/ethnicity of the customer.
Hill climbing algorithms can give unpredictable results depending both on the original guess and very minor variations (such as small differences between the DNA of identical twins). This can happen when the search starts near the midpoint of a valley between two hills. Should the algorithm go up one side (east) or up the other side of the valley (west)? A very small difference in the nearly flat valley floor can favor one side over the other, even though otherwise the situation is very very similar.
In DNA testing, east-west location might represent the fraction of European ancestry and the north-west location might represent the fraction of American Indian ancestry (for example). The height of the hill is measure of the goodness of fit between the model and the data (the genes and genetic markers in the DNA). Consider the difficulties that might arise discriminating between someone, mostly European, with a small amount of American Indian ancestry (say some of the genes that contribute to the epicanthic fold found in some American Indians) and someone who is entirely European but has a mild epicanthic fold and, in fact, some of the same genes. Two adjacent hills with a separating valley may appear — one representing all European and one representing Mostly European with a small mixture of American Indian.
This problem with hill climbing algorithms may explain the striking different results for two identical twins from the same DNA testing company reported by the CBC.
Other model fitting and statistical analysis methods can also exhibit unstable results in certain situations.
Again, the DNA ancestry tests are using the relative frequency of genes and genetic markers found in many groups, even in different races and on different continents, rather than a hypothetical group “barcode” gene that is a unique identifier.
Conclusion
It is reasonable to strongly suspect, given the many reports like the recent CBC news segment of variations in the estimated ancestry of several percent, that DNA ancestry tests for race, ethnicity, and nationality are not reliable at the few percent level (about 1/16, 6.25%, great-great-grandparent level) at present (Feb. 2019). Even where an unusual gene or genetic marker such as the Duffy null allele that is highly correlated with group membership is found in a customer, some caution is warranted as the “out of Africa” hypothesis suggests that many potential group “barcode” genes and markers will be present at low levels in all human populations.
It may be that the many reports of several percent errors in DNA ancestry tests are relatively rare compared to the millions of DNA ancestry tests now administered. Many DNA ancestry tests are “recreational” and occasional errors of several percent in such recreational cases are tolerable. Where DNA ancestry tests have serious implications, public policy or otherwise, much higher accuracy — as is claimed for forensic DNA tests and DNA paternity tests — is expected and should be required. Errors (e.g. ±0.5 percent) and/or confidence levels should be clearly stated and explained.
John F. McGowan, Ph.D. solves problems using mathematics and mathematical software, including developing gesture recognition for touch devices, video compression and speech recognition technologies. He has extensive experience developing software in C, C++, MATLAB, Python, Visual Basic and many other programming languages. He has been a Visiting Scholar at HP Labs developing computer vision algorithms and software for mobile devices. He has worked as a contractor at NASA Ames Research Center involved in the research and development of image and video processing algorithms and technology. He has published articles on the origin and evolution of life, the exploration of Mars (anticipating the discovery of methane on Mars), and cheap access to space. He has a Ph.D. in physics from the University of Illinois at Urbana-Champaign and a B.S. in physics from the California Institute of Technology (Caltech).